Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
时间:2015-10-20 15:44 来源:linux.it.net.cn 作者:IT
最近一直在自学Hadoop,今天花点时间搭建一个开发环境,并整理成文。
首先要了解一下Hadoop的运行模式:
单机模式(standalone)
单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
伪分布模式(Pseudo-Distributed Mode)
伪分布模式在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
全分布模式(Fully Distributed Mode)
Hadoop守护进程运行在一个集群上。
版本:ubuntu 10.04.4,hadoop 1.0.2
1.添加hadoop用户到系统用户
安装前要做一件事——添加一个名为hadoop到系统用户,专门用来做Hadoop测试。
-
~$ sudo addgroup hadoop
-
~$ sudo adduser --ingroup hadoop hadoop
现在只是添加了一个用户hadoop,它并不具备管理员权限,因此我们需要将用户hadoop添加到管理员组:
-
~$ sudo usermod -aG admin hadoop
2.安装ssh
由于Hadoop用ssh通信,先安装ssh
-
~$ sudo apt-get install openssh-server
ssh安装完成以后,先启动服务:
-
~$ sudo /etc/init.d/ssh start
启动后,可以通过如下命令查看服务是否正确启动:
-
~$ ps -e | grep ssh
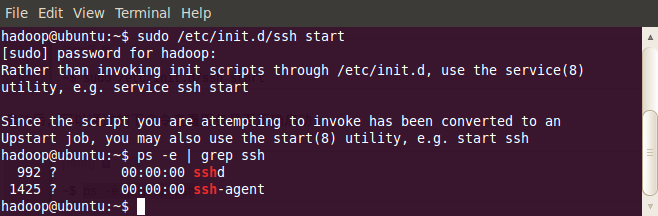
作为一个安全通信协议,使用时需要密码,因此我们要设置成免密码登录,生成私钥和公钥:
因为我已有私钥,所以会提示是否覆盖当前私钥。第一次操作时会提示输入密码,按Enter直接过,这时会在~/home/{username}/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥,现在我们将公钥追加到authorized_keys中(authorized_keys用于保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容):
现在可以登入ssh确认以后登录时不用输入密码:
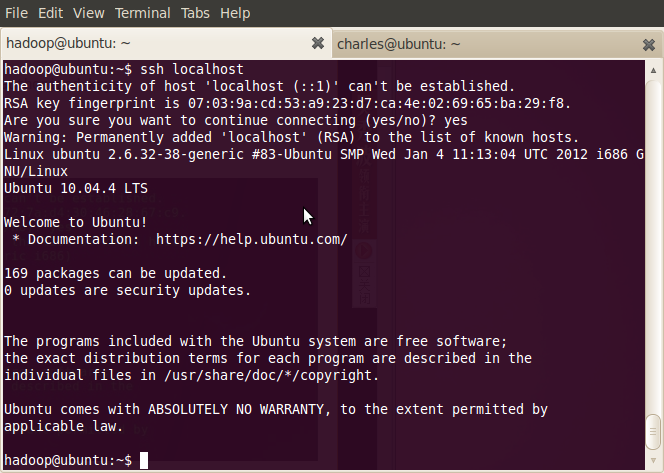
登出:
第二次登录:
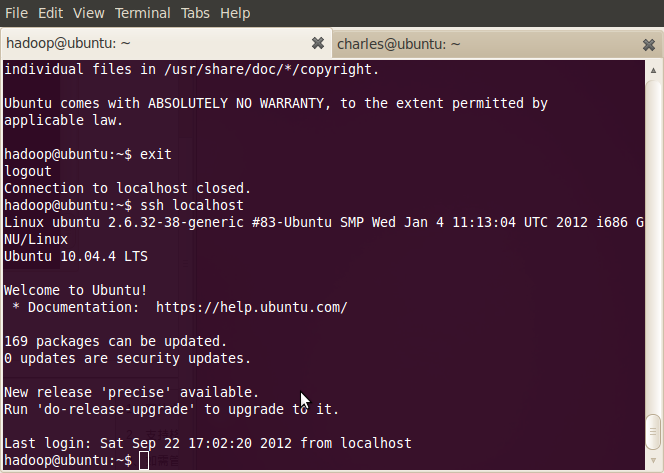
登出:
这样以后登录就不用输入密码了。
3.安装Java
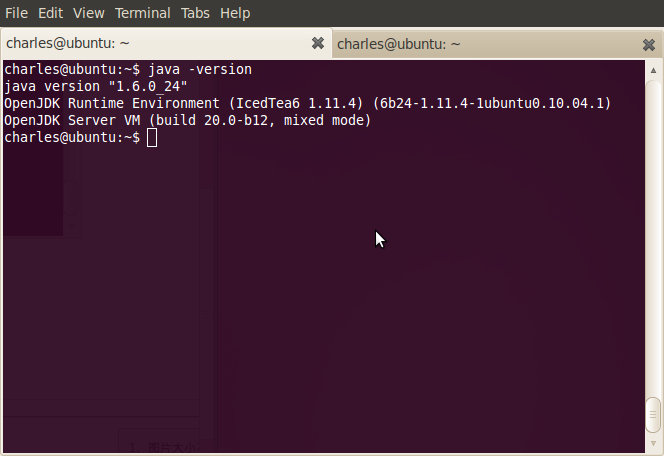
4.安装hadoop 1.0.2
到官网下载hadoop源文件,这里选择hadoop 1.0.2
解压并放到你希望的目录中。我是放到/usr/local/hadoop
要确保所有的操作都是在用户hadoop下完成的:
5.设定hadoop-env.sh(Java 安装路径)
进入hadoop目录,打开conf目录下到hadoop-env.sh,添加以下信息:
export JAVA_HOME=/usr/lib/jvm/java-6-openjdk (视你机器的java安装路径而定)
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:/usr/local/hadoop/bin
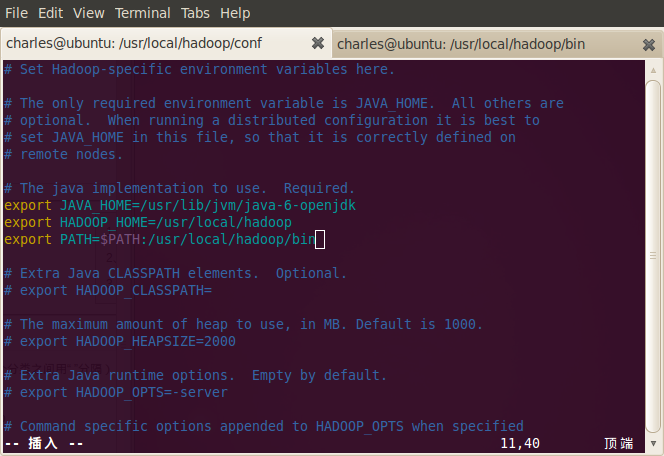
![]()
并且,让环境变量配置生效source
至此,hadoop的单机模式已经安装成功。
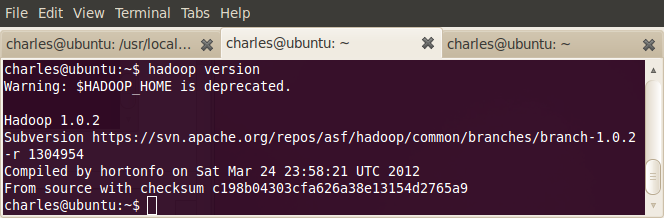
于是,运行一下hadoop自带的例子WordCount来感受以下MapReduce过程:
在hadoop目录下新建input文件夹
将conf中的所有文件拷贝到input文件夹中
-
~$ cp conf/* input<SPAN style="BACKGROUND-COLOR: rgb(255,255,255); FONT-FAMILY: Arial, Helvetica, sans-serif; WHITE-SPACE: normal"> </SPAN>
运行WordCount程序,并将结果保存到output中
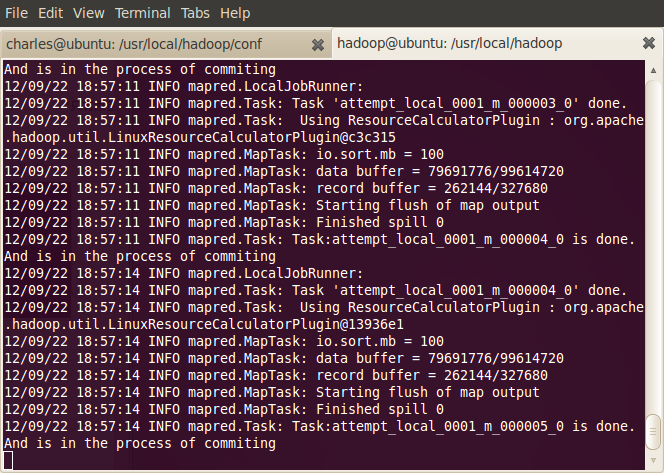
运行
-
~$ cat output/*
你会看到conf所有文件的单词和频数都被统计出来。
![]()
下面是伪分布模式需要的一些配置,继续。
6.设定*-site.xml
这里需要设定3个文件:core-site.xml,hdfs-site.xml,mapred-site.xml,都在/usr/local/hadoop/conf目录下
core-site.xml: Hadoop Core的配置项,例如HDFS和MapReduce常用的I/O设置等。
hdfs-site.xml: Hadoop 守护进程的配置项,包括namenode,辅助namenode和datanode等。
mapred-site.xml: MapReduce 守护进程的配置项,包括jobtracker和tasktracker。
首先在hadoop目录下新建几个文件夹
-
~/hadoop$ mkdir tmp
-
~/hadoop$ mkdir hdfs
-
~/hadoop$ mkdir hdfs/name
-
~/hadoop$ mkdir hdfs/data
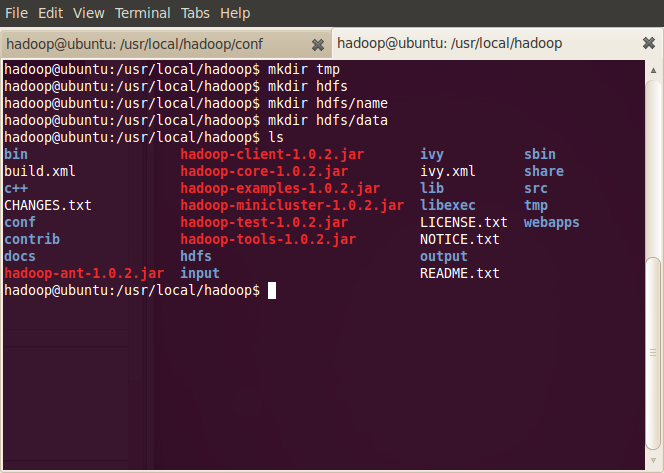
接下来编辑那三个文件:
core-site.xml:
-
<configuration>
-
<property>
-
<name>fs.default.name</name>
-
<value>hdfs://localhost:9000</value>
-
</property>
-
<property>
-
<name>hadoop.tmp.dir</name>
-
<value>/usr/local/hadoop/tmp</value>
-
</property>
-
</configuration>
hdfs-site.xml:
-
<configuration>
-
<property>
-
<name>dfs.replication</name>
-
<value>1</value>
-
</property>
-
<property>
-
<name>dfs.name.dir</name>
-
<value>/usr/local/hadoop/hdfs/name</value>
-
</property>
-
<property>
-
<name>dfs.data.dir</name>
-
<value>/usr/local/hadoop/hdfs/data</value>
-
</property>
-
</configuration>
mapred-site.xml:
-
<configuration>
-
<property>
-
<name>mapred.job.tracker</name>
-
<value>localhost:9001</value>
-
</property>
-
</configuration>
7.格式化HDFS
通过以上步骤,我们已经设定好Hadoop单机测试到环境,接着就是启动Hadoop到相关服务,格式化namenode,secondarynamenode,tasktracker:
-
~$ source /usr/local/hadoop/conf/hadoop-env.sh
-
~$ hadoop namenode -format
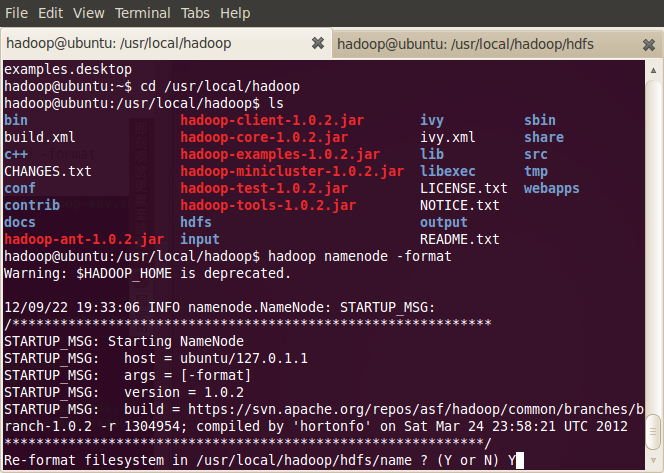
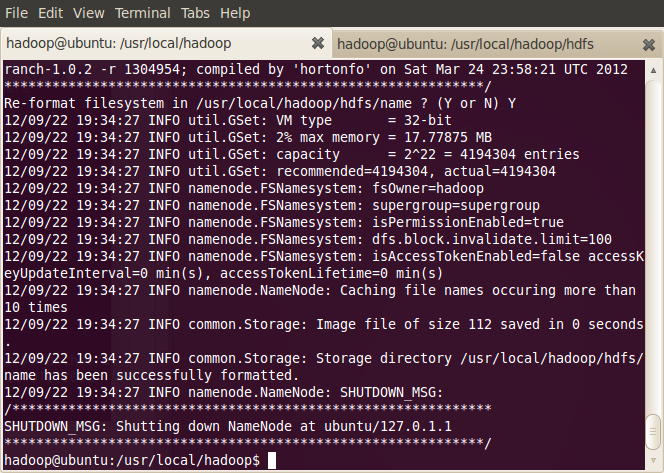
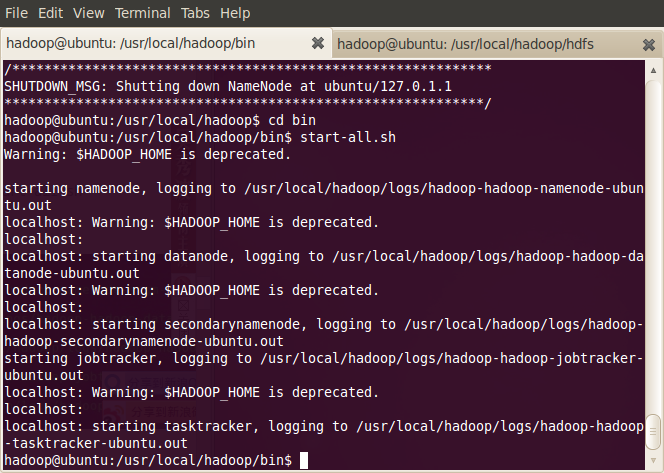
8.启动Hadoop
接着执行start-all.sh来启动所有服务,包括namenode,datanode,start-all.sh脚本用来装载守护进程。
-
hadoop@ubuntu:/usr/local/hadoop$ cd bin
-
hadoop@ubuntu:/usr/local/hadoop/bin$ start-all.sh
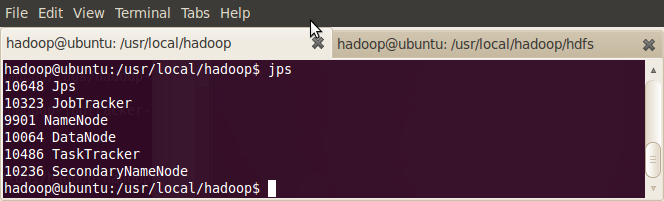
用Java的jps命令列出所有守护进程来验证安装成功
-
hadoop@ubuntu:/usr/local/hadoop$ jps
出现如下列表,表明成功
9.检查运行状态
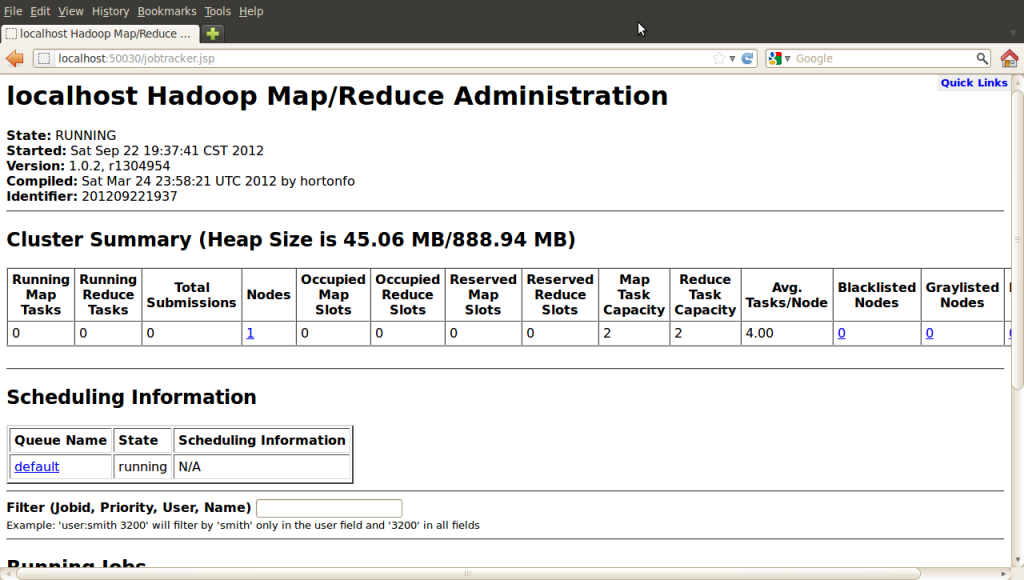
所有的设置已完成,Hadoop也启动了,现在可以通过下面的操作来查看服务是否正常,在Hadoop中用于监控集群健康状态的Web界面:
http://localhost:50030/ - Hadoop 管理介面
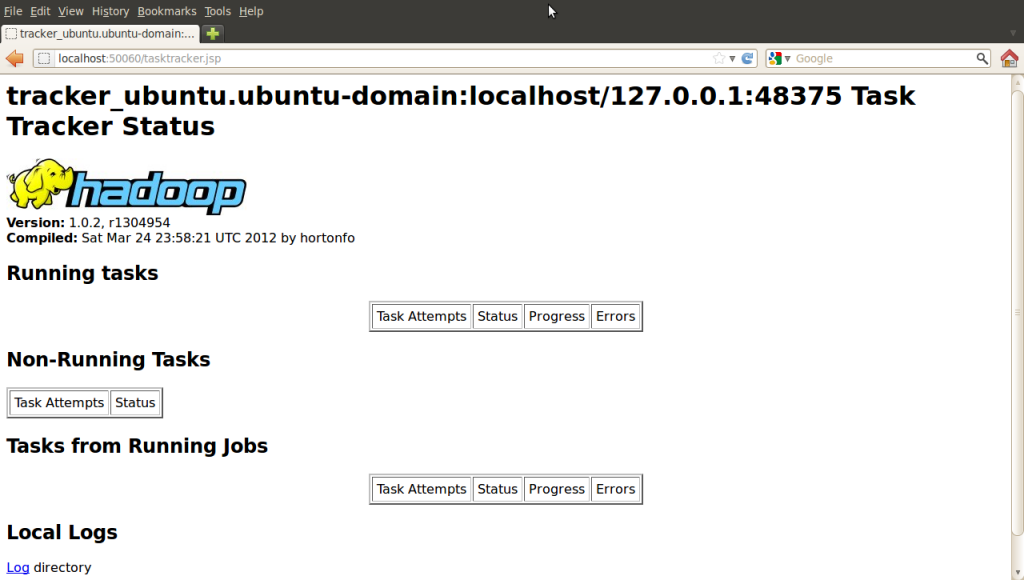
http://localhost:50060/ - Hadoop Task Tracker 状态
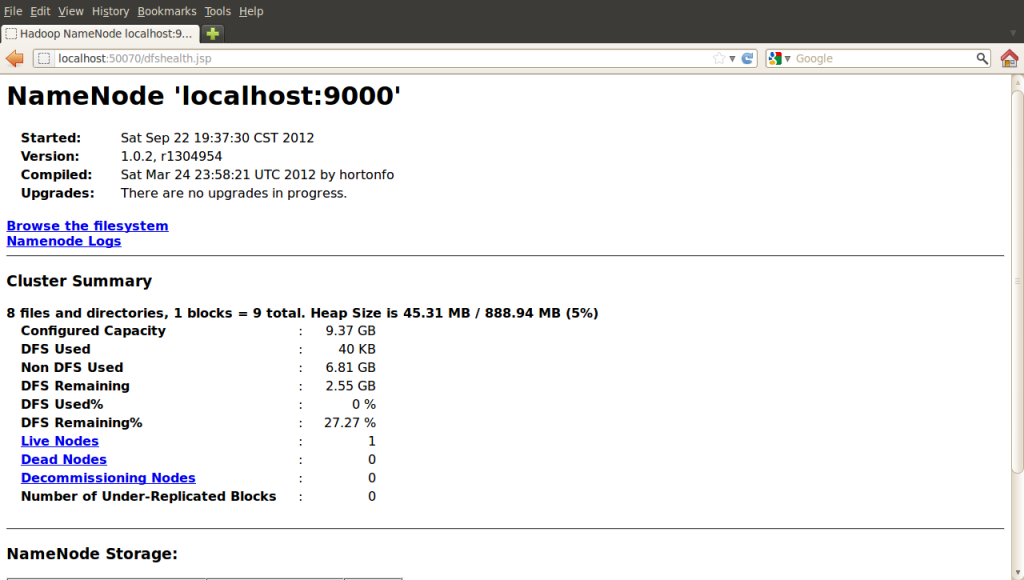
http://localhost:50070/ - Hadoop DFS 状态
Hadoop 管理介面:
Hadoop Task Tracker 状态:
Hadoop DFS 状态:
至此,hadoop的伪分布模式已经安装成功,于是,再次在伪分布模式下运行一下hadoop自带的例子WordCount来感受以下MapReduce过程:
这时注意程序是在文件系统dfs运行的,创建的文件也都基于文件系统:
首先在dfs中创建input目录
-
hadoop@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -mkdir input
将conf中的文件拷贝到dfs中的input
-
hadoop@ubuntu:/usr/local/hadoop$ hadoop dfs -copyFromLocal conf/* input
在伪分布式模式下运行WordCount
-
hadoop@ubuntu:/usr/local/hadoop$ hadoop jar hadoop-examples-1.0.2.jar wordcount input output
可看到以下过程
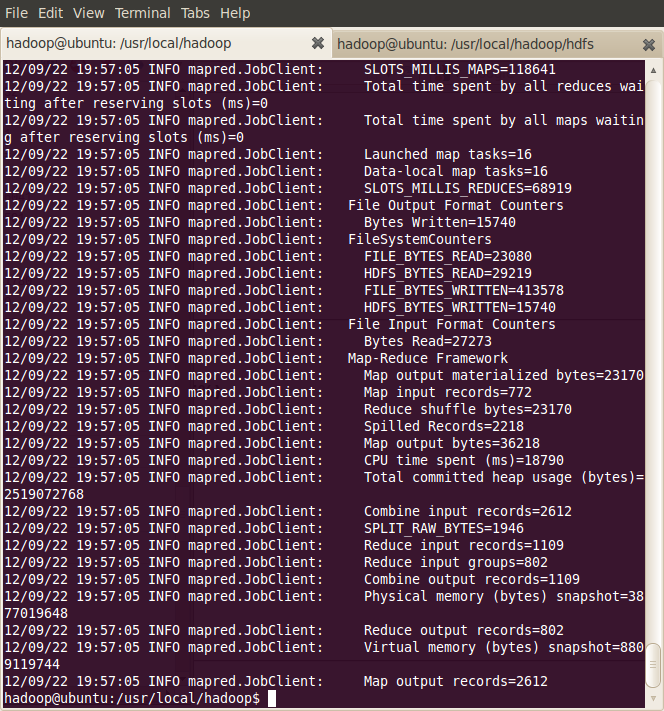
显示输出结果
-
hadoop@ubuntu:/usr/local/hadoop$ hadoop dfs -cat output/*
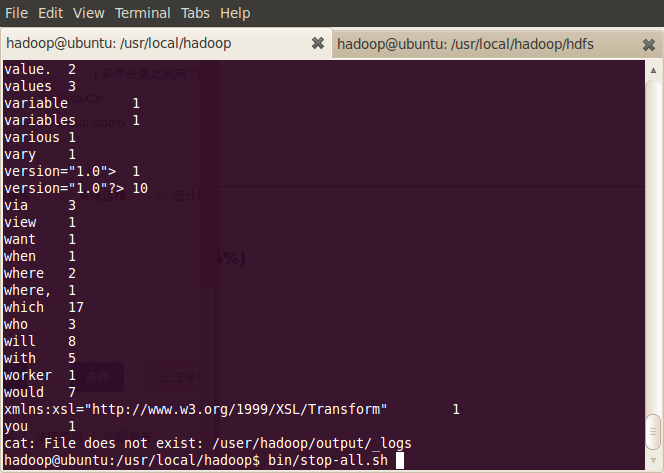
当Hadoop结束时,可以通过stop-all.sh脚本来关闭Hadoop的守护进程
-
hadoop@ubuntu:/usr/local/hadoop$ bin/stop-all.sh
10.结语
在ubuntu上搭建hadoop成功!有点小兴奋,已经迫不及待的想开始做一些相关的开发及深入理解hadoop内核实现,继续加油咯!
PS:单机模式和伪分布模式均用于开发和调试的目的。真实Hadoop集群的运行采用的是第三种模式,即全分布模式。待续。
本文参考了这两位同学的文章,感谢分享阿!
http://blog.sina.com.cn/s/blog_61ef49250100uvab.html
http://www.cnblogs.com/welbeckxu/category/346329.html
(责任编辑:IT)
最近一直在自学Hadoop,今天花点时间搭建一个开发环境,并整理成文。 首先要了解一下Hadoop的运行模式:
单机模式(standalone)
版本:ubuntu 10.04.4,hadoop 1.0.2 1.添加hadoop用户到系统用户 安装前要做一件事——添加一个名为hadoop到系统用户,专门用来做Hadoop测试。
现在只是添加了一个用户hadoop,它并不具备管理员权限,因此我们需要将用户hadoop添加到管理员组:
2.安装ssh
由于Hadoop用ssh通信,先安装ssh
ssh安装完成以后,先启动服务:
作为一个安全通信协议,使用时需要密码,因此我们要设置成免密码登录,生成私钥和公钥:
因为我已有私钥,所以会提示是否覆盖当前私钥。第一次操作时会提示输入密码,按Enter直接过,这时会在~/home/{username}/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥,现在我们将公钥追加到authorized_keys中(authorized_keys用于保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容):
登出:
登出:
3.安装Java
4.安装hadoop 1.0.2 到官网下载hadoop源文件,这里选择hadoop 1.0.2 解压并放到你希望的目录中。我是放到/usr/local/hadoop
5.设定hadoop-env.sh(Java 安装路径)
进入hadoop目录,打开conf目录下到hadoop-env.sh,添加以下信息:
并且,让环境变量配置生效source
至此,hadoop的单机模式已经安装成功。
于是,运行一下hadoop自带的例子WordCount来感受以下MapReduce过程: 在hadoop目录下新建input文件夹
运行
下面是伪分布模式需要的一些配置,继续。
6.设定*-site.xml 首先在hadoop目录下新建几个文件夹
接下来编辑那三个文件: core-site.xml:
7.格式化HDFS 通过以上步骤,我们已经设定好Hadoop单机测试到环境,接着就是启动Hadoop到相关服务,格式化namenode,secondarynamenode,tasktracker:
接着执行start-all.sh来启动所有服务,包括namenode,datanode,start-all.sh脚本用来装载守护进程。
用Java的jps命令列出所有守护进程来验证安装成功
Hadoop 管理介面:
Hadoop Task Tracker 状态:
Hadoop DFS 状态:
至此,hadoop的伪分布模式已经安装成功,于是,再次在伪分布模式下运行一下hadoop自带的例子WordCount来感受以下MapReduce过程: 这时注意程序是在文件系统dfs运行的,创建的文件也都基于文件系统: 首先在dfs中创建input目录
显示输出结果
10.结语 在ubuntu上搭建hadoop成功!有点小兴奋,已经迫不及待的想开始做一些相关的开发及深入理解hadoop内核实现,继续加油咯! PS:单机模式和伪分布模式均用于开发和调试的目的。真实Hadoop集群的运行采用的是第三种模式,即全分布模式。待续。
本文参考了这两位同学的文章,感谢分享阿! http://blog.sina.com.cn/s/blog_61ef49250100uvab.html http://www.cnblogs.com/welbeckxu/category/346329.html (责任编辑:IT) |