SQL Azure存储架构设计
时间:2016-06-06 17:26 来源:linux.it.net.cn 作者:IT
SQL Azure简介
SQL Azure是Azure存储平台的逻辑数据库,物理数据库仍然是SQL Server。一个物理的SQL Server被分成多个逻辑分片(partition),每一个分片成为一个SQL Azure实例,在分布式系统中也经常被称作子表(tablet)。和大多数分布式存储系统一样,SQL Azure的数据存储三个副本,同一个时刻一个副本为Primary,提供读写服务,其它副本为Secondary,可以提供最终一致性的读服务。每一个SQL Azure实例的允许的最大数据量可以为1GB或者5GB(Web Edition),10GB, 20GB, 30GB, 40GB或者50GB(Business Edition)。由于限制了子表最大数据量,Azure存储平台内部不支持子表分裂。
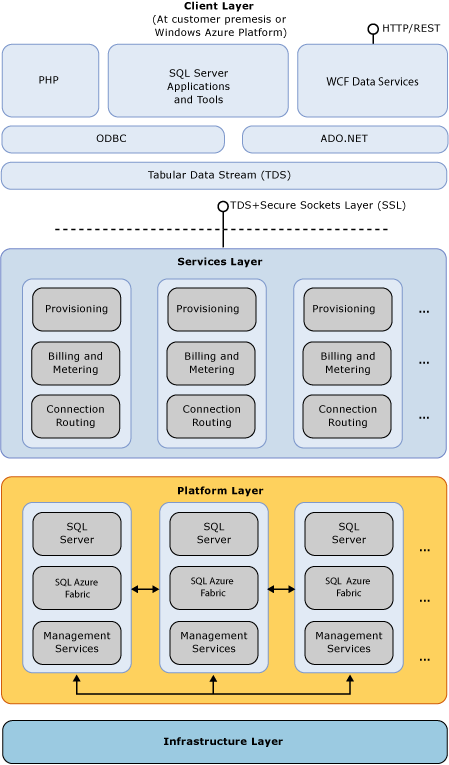
如上图,与大多数Web系统架构类似,Azure存储平台大致可以分为四层,从上到下分别为:
1)Client Layer:将用户的请求转化为Azure内部的TDS格式流;2)Services Layer:相当于网关,相当于普通Web系统的逻辑层;3)Platform Layer:存储节点集群,相当于普通Web系统的数据库层;4)Infrastructure Layer:硬件和操作系统。Azure使用的硬件为普通PC机,论文中给出的典型配置为:8核,32GB内存,12块磁盘,大致的价格为3500美金。
Services Layer
服务层相当于普通Web系统的逻辑层,包含的功能包括:路由,计费,权限验证。另外,SQL Azure的服务层还监控Platform Layer中的存储节点,完成宕机检测和恢复,负载均衡等总控工作。Services Layer的架构如下:
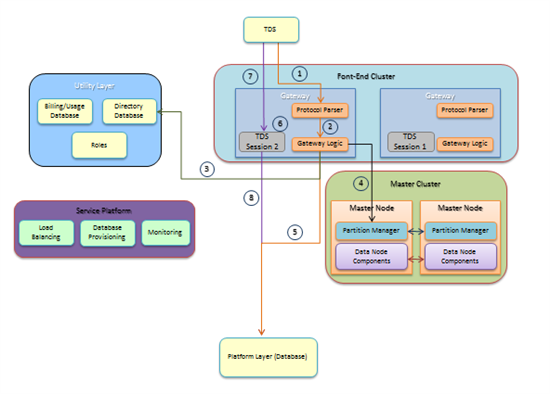
【sorry,图片直接copy的,字体比较小,重点理解功能划分及流程,Utility Layer理解大意即可】
如上图,服务层包含四种类型的组件:
1、Front-end cluster:完成路由功能并包含防攻击模块,相当于Web架构中的Web服务器,如Apache或者Nginx;
2、Utility Layer:请求服务器合法性验证,计费等功能;
3、Service Platform:监控存储节点集群的机器健康状况,完成宕机检测和恢复,负载均衡等功能;
4、Master Cluster:配置服务器,保存每个SQL Azure实例的副本所在的物理存储节点信息。
其中,Master Cluster一般配置为七台机器,采用”Quorum Commit”技术,也就是任何一个Master操作必须同步到四个以上副本才算成功,四个以下Master机器故障不影响服务;其它类型的机器都是无状态的,且机器之间同构。上图中,请求的流程说明如下:
1、客户端与Front-end机器建立连接,Front-end验证是否支持客户端的操作,如CREATE DATABASE这样的操作只能通过Azure实用工具执行;
2、Front-end网关机器与客户端进行SSL协议握手认证,如果客户端拒绝使用SSL协议则断开连接。这个过程中还将执行防攻击保护,比如拒绝某个或某一段范围IP地址频繁访问;
3、Front-end网关机器请求Utility Layer进行必要的验证,如请求服务器地址白名单认证;
4、Front-end网关机器请求Master获取用户请求的数据分片所在的物理存储节点副本信息;
5、Front-end网关机器请求请求Platform Layer中的物理存储节点验证用户的数据库权限;
6、如果以上认证均通过,客户端和Platform Layer中的存储节点建立新的连接;
7~8、后续所有的客户端请求都直接发送到Platform Layer中的物理存储节点,Front-end网关只是转发请求和回复数据,起一个中间代理作用。
Platform Layer
平台层就是存储节点集群,运行物理的SQL Server服务器。客户端的请求通过Front-end网关节点转发到平台层的数据节点,每个SQL Azure实例是SQL Server的一个数据分片,每个数据分片在不同的SQL Server数据节点上存储三个副本,同一时刻只有一个副本为Primary,其它副本为Secondary。数据写入采用”Quorum Commit”策略,至少两个副本写成功时才返回客户端,这样即使一个数据节点发生故障也不影响正常服务。Platform Layer的架构如下:
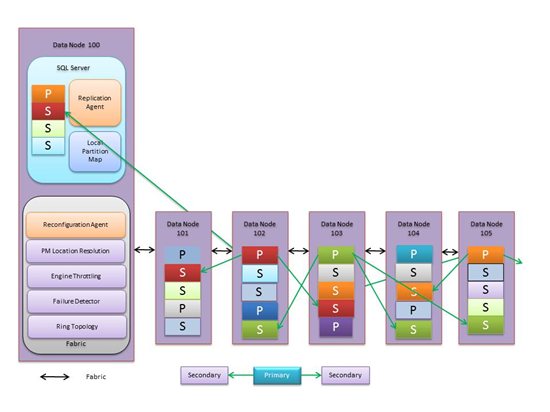
【sorry,图片直接copy,字体太小,请关注后续对存储节点Agent程序的描述】
如上图,每个SQL Server数据节点最多服务650个数据分片,每一个数据节点上的所有数据分片的写操作记录到一个操作日志文件中,从而提高写入操作的聚合性能。每个分片的多个副本之间的数据同步是通过同步并回放操作日志实现的,由于每个分片的副本所在的机器可能不同,因此,每个SQL Server存储节点最多需要和650个其它存储节点进行数据同步,网络聚合不够,这也是限制单个存储节点最多服务650个分片的原因。
如上图,每个物理存储节点上都运行了一些实用的deamon程序(称为fabric),大致介绍如下:
1、Failure detection:检测数据节点故障从而触发Reconfiguration过程;
2、Reconfiguration Agent:节点故障后负责在数据节点重新生成Primary或者Secondary数据分片;
3、PM (Partition Manager) Location Resolution:解析Master的地址从而发送数据节点的消息给Master的Partition Manager处理;
4、Engine Throttling:限制每个逻辑的SQL Azure实例占用的资源比例,防止超出容量限制;
5、Ring Topology:所有的数据节点构成一个环,从而每个节点有两个邻居节点可以检测节点是否宕机。
分布式相关问题
1、数据复制(Replication)
SQL Azure中采用”Quorum Commit”的策略,普通的数据存储三个副本,至少写成功两个副本才可以返回成功;Master存储七个副本,至少需要写成功四个副本。每个SQL Server节点的更新操作写到一个操作日志文件中并通过网络发送到另外两个副本,由于不同数据分片的副本所在的SQL Server机器可能不同,一个存储节点的操作日志最多需要和650个分片数量的机器通信,日志同步的网络聚合效果不够好。Yahoo的PNUTS为了解决这个问题采用了消息中间件进行操作日志分发,达到聚合操作日志的效果。
2、宕机检测和恢复
SQL Azure的宕机检测论文中讲的不够细,大致的意思是:每个数据节点都被一些对等的数据节点监控,发现宕机则报告总控节点进行宕机恢复过程;同时,如果无法确定数据节点是否宕机,比如待监控数据节点假死而停止回复命令,此时需要由仲裁者节点进行仲裁。判断机器是否宕机需要一些协议控制,后面的文章会专门介绍。
如果数据节点发生了故障,需要启动宕机恢复过程。由于宕机的数据节点服务了最多650个逻辑的SQL Azure实例(子表),这些子表可能是Primary,也可能是Secondary。总控节点统一调度,每次选择一个数据分片进行Reconfiguration,即子表复制过程。对于Secondary数据分片,只需要通过从Primary拷贝数据来增加副本;对于Primary,首先需要从另外两个副本中选择一个Secondary作为新的Primary,接着执行和Secondary数据分片Reconfiguration一样的过程。另外,这里需要进行优先级的控制,比如某个数据分片只有一个副本,需要优先复制;某个数据分片的Primary不可服务,需要优先执行从剩余的副本中选择Secondary切换为Primary的过程。当然,这里还需要配置一些策略,比如只有两个副本的状态持续多长时间开始复制第三个副本,SQL Azure目前配置为两小时。
3、负载均衡
新的数据节点加入或者发现某个节点负载过高时,总控节点启动负载均衡过程。数据节点负载影响因素包括:读写个数,磁盘/内存/CPU/IO使用量等。这里需要注意的是,新机器加入时需要控制子表迁移的节奏,否则大量的子表同时迁移到新加入的机器导致系统整体性能反而变慢。
SQL Azure由于可以控制每个逻辑SQL Azure实例,即每个子表的大小,因此,为了简便起见,可以不实现子表分裂,很大程度上简化了系统。
4、事务
SQL Azure支持数据库事务,数据库事务相关的SQL语句都会记录BEGIN TRANSACTION,ROLLBACK TRANSACTION和COMMIT TRANSACTION相关的操作日志。在SQL Azure中,只需要将这些操作日志同步到其它副本即可,由于同一时刻同一个数据分片最多有一个Primary提供写服务,不涉及分布式事务。SQL Azure系统支持的事务级别为READ_COMMITTED。
5、多租户干扰
云计算系统中多租用的操作相互干扰,因此需要限制每个SQL Azure逻辑实例使用的系统资源:
1)系统操作系统资源限制,比如CPU和内存。超过限制时回复客户端要求10s后重试;
2)SQL Azure逻辑数据库容量限制。每个逻辑数据库都预先设置了最大的容量,超过限制时拒绝更新请求,但允许删除操作;
3)SQL Server物理数据库数据大小限制。超过该限制时返回客户端系统错误,此时需要人工介入。
与SQL Server的差别
1、不支持的操作:Microsoft Azure作为一个针对企业级应用的平台,尽管尝试支持尽量多的SQL特性,仍然有一些特性无法支持。比如USE操作:SQL Server可以通过USE切换数据库,不过在SQL Azure不支持,这时因为不同的逻辑数据库可能位于不同的物理机器。具体可以参考SQL Azure vs. SQL Server。
2、观念转变:对于开发人员,需要用分布式系统的思维开发程序,比如一个连接除了成功,失败还有第三种不确定状态:云端没有返回操作结果,操作是否成功我们无从得知;又如,天下没有像SQL这么好的免费午餐;对于DBA同学,数据库的日常维护,比如升级,数据备份等工作都移交给了微软,可能会有更多的精力关注业务系统架构。
完整的信息可以参考微软前不久公布的Azure存储系统架构Inside SQL Azure论文。
(责任编辑:IT)
SQL Azure简介 SQL Azure是Azure存储平台的逻辑数据库,物理数据库仍然是SQL Server。一个物理的SQL Server被分成多个逻辑分片(partition),每一个分片成为一个SQL Azure实例,在分布式系统中也经常被称作子表(tablet)。和大多数分布式存储系统一样,SQL Azure的数据存储三个副本,同一个时刻一个副本为Primary,提供读写服务,其它副本为Secondary,可以提供最终一致性的读服务。每一个SQL Azure实例的允许的最大数据量可以为1GB或者5GB(Web Edition),10GB, 20GB, 30GB, 40GB或者50GB(Business Edition)。由于限制了子表最大数据量,Azure存储平台内部不支持子表分裂。
如上图,与大多数Web系统架构类似,Azure存储平台大致可以分为四层,从上到下分别为: 1)Client Layer:将用户的请求转化为Azure内部的TDS格式流;2)Services Layer:相当于网关,相当于普通Web系统的逻辑层;3)Platform Layer:存储节点集群,相当于普通Web系统的数据库层;4)Infrastructure Layer:硬件和操作系统。Azure使用的硬件为普通PC机,论文中给出的典型配置为:8核,32GB内存,12块磁盘,大致的价格为3500美金。 Services Layer 服务层相当于普通Web系统的逻辑层,包含的功能包括:路由,计费,权限验证。另外,SQL Azure的服务层还监控Platform Layer中的存储节点,完成宕机检测和恢复,负载均衡等总控工作。Services Layer的架构如下:
【sorry,图片直接copy的,字体比较小,重点理解功能划分及流程,Utility Layer理解大意即可】 如上图,服务层包含四种类型的组件: 1、Front-end cluster:完成路由功能并包含防攻击模块,相当于Web架构中的Web服务器,如Apache或者Nginx; 2、Utility Layer:请求服务器合法性验证,计费等功能; 3、Service Platform:监控存储节点集群的机器健康状况,完成宕机检测和恢复,负载均衡等功能; 4、Master Cluster:配置服务器,保存每个SQL Azure实例的副本所在的物理存储节点信息。 其中,Master Cluster一般配置为七台机器,采用”Quorum Commit”技术,也就是任何一个Master操作必须同步到四个以上副本才算成功,四个以下Master机器故障不影响服务;其它类型的机器都是无状态的,且机器之间同构。上图中,请求的流程说明如下: 1、客户端与Front-end机器建立连接,Front-end验证是否支持客户端的操作,如CREATE DATABASE这样的操作只能通过Azure实用工具执行; 2、Front-end网关机器与客户端进行SSL协议握手认证,如果客户端拒绝使用SSL协议则断开连接。这个过程中还将执行防攻击保护,比如拒绝某个或某一段范围IP地址频繁访问; 3、Front-end网关机器请求Utility Layer进行必要的验证,如请求服务器地址白名单认证; 4、Front-end网关机器请求Master获取用户请求的数据分片所在的物理存储节点副本信息; 5、Front-end网关机器请求请求Platform Layer中的物理存储节点验证用户的数据库权限; 6、如果以上认证均通过,客户端和Platform Layer中的存储节点建立新的连接; 7~8、后续所有的客户端请求都直接发送到Platform Layer中的物理存储节点,Front-end网关只是转发请求和回复数据,起一个中间代理作用。 Platform Layer 平台层就是存储节点集群,运行物理的SQL Server服务器。客户端的请求通过Front-end网关节点转发到平台层的数据节点,每个SQL Azure实例是SQL Server的一个数据分片,每个数据分片在不同的SQL Server数据节点上存储三个副本,同一时刻只有一个副本为Primary,其它副本为Secondary。数据写入采用”Quorum Commit”策略,至少两个副本写成功时才返回客户端,这样即使一个数据节点发生故障也不影响正常服务。Platform Layer的架构如下:
【sorry,图片直接copy,字体太小,请关注后续对存储节点Agent程序的描述】 如上图,每个SQL Server数据节点最多服务650个数据分片,每一个数据节点上的所有数据分片的写操作记录到一个操作日志文件中,从而提高写入操作的聚合性能。每个分片的多个副本之间的数据同步是通过同步并回放操作日志实现的,由于每个分片的副本所在的机器可能不同,因此,每个SQL Server存储节点最多需要和650个其它存储节点进行数据同步,网络聚合不够,这也是限制单个存储节点最多服务650个分片的原因。 如上图,每个物理存储节点上都运行了一些实用的deamon程序(称为fabric),大致介绍如下: 1、Failure detection:检测数据节点故障从而触发Reconfiguration过程; 2、Reconfiguration Agent:节点故障后负责在数据节点重新生成Primary或者Secondary数据分片; 3、PM (Partition Manager) Location Resolution:解析Master的地址从而发送数据节点的消息给Master的Partition Manager处理; 4、Engine Throttling:限制每个逻辑的SQL Azure实例占用的资源比例,防止超出容量限制; 5、Ring Topology:所有的数据节点构成一个环,从而每个节点有两个邻居节点可以检测节点是否宕机。 分布式相关问题 1、数据复制(Replication) SQL Azure中采用”Quorum Commit”的策略,普通的数据存储三个副本,至少写成功两个副本才可以返回成功;Master存储七个副本,至少需要写成功四个副本。每个SQL Server节点的更新操作写到一个操作日志文件中并通过网络发送到另外两个副本,由于不同数据分片的副本所在的SQL Server机器可能不同,一个存储节点的操作日志最多需要和650个分片数量的机器通信,日志同步的网络聚合效果不够好。Yahoo的PNUTS为了解决这个问题采用了消息中间件进行操作日志分发,达到聚合操作日志的效果。 2、宕机检测和恢复 SQL Azure的宕机检测论文中讲的不够细,大致的意思是:每个数据节点都被一些对等的数据节点监控,发现宕机则报告总控节点进行宕机恢复过程;同时,如果无法确定数据节点是否宕机,比如待监控数据节点假死而停止回复命令,此时需要由仲裁者节点进行仲裁。判断机器是否宕机需要一些协议控制,后面的文章会专门介绍。 如果数据节点发生了故障,需要启动宕机恢复过程。由于宕机的数据节点服务了最多650个逻辑的SQL Azure实例(子表),这些子表可能是Primary,也可能是Secondary。总控节点统一调度,每次选择一个数据分片进行Reconfiguration,即子表复制过程。对于Secondary数据分片,只需要通过从Primary拷贝数据来增加副本;对于Primary,首先需要从另外两个副本中选择一个Secondary作为新的Primary,接着执行和Secondary数据分片Reconfiguration一样的过程。另外,这里需要进行优先级的控制,比如某个数据分片只有一个副本,需要优先复制;某个数据分片的Primary不可服务,需要优先执行从剩余的副本中选择Secondary切换为Primary的过程。当然,这里还需要配置一些策略,比如只有两个副本的状态持续多长时间开始复制第三个副本,SQL Azure目前配置为两小时。 3、负载均衡 新的数据节点加入或者发现某个节点负载过高时,总控节点启动负载均衡过程。数据节点负载影响因素包括:读写个数,磁盘/内存/CPU/IO使用量等。这里需要注意的是,新机器加入时需要控制子表迁移的节奏,否则大量的子表同时迁移到新加入的机器导致系统整体性能反而变慢。 SQL Azure由于可以控制每个逻辑SQL Azure实例,即每个子表的大小,因此,为了简便起见,可以不实现子表分裂,很大程度上简化了系统。 4、事务 SQL Azure支持数据库事务,数据库事务相关的SQL语句都会记录BEGIN TRANSACTION,ROLLBACK TRANSACTION和COMMIT TRANSACTION相关的操作日志。在SQL Azure中,只需要将这些操作日志同步到其它副本即可,由于同一时刻同一个数据分片最多有一个Primary提供写服务,不涉及分布式事务。SQL Azure系统支持的事务级别为READ_COMMITTED。 5、多租户干扰 云计算系统中多租用的操作相互干扰,因此需要限制每个SQL Azure逻辑实例使用的系统资源: 1)系统操作系统资源限制,比如CPU和内存。超过限制时回复客户端要求10s后重试; 2)SQL Azure逻辑数据库容量限制。每个逻辑数据库都预先设置了最大的容量,超过限制时拒绝更新请求,但允许删除操作; 3)SQL Server物理数据库数据大小限制。超过该限制时返回客户端系统错误,此时需要人工介入。 与SQL Server的差别 1、不支持的操作:Microsoft Azure作为一个针对企业级应用的平台,尽管尝试支持尽量多的SQL特性,仍然有一些特性无法支持。比如USE操作:SQL Server可以通过USE切换数据库,不过在SQL Azure不支持,这时因为不同的逻辑数据库可能位于不同的物理机器。具体可以参考SQL Azure vs. SQL Server。 2、观念转变:对于开发人员,需要用分布式系统的思维开发程序,比如一个连接除了成功,失败还有第三种不确定状态:云端没有返回操作结果,操作是否成功我们无从得知;又如,天下没有像SQL这么好的免费午餐;对于DBA同学,数据库的日常维护,比如升级,数据备份等工作都移交给了微软,可能会有更多的精力关注业务系统架构。
完整的信息可以参考微软前不久公布的Azure存储系统架构Inside SQL Azure论文。 |