hadoop1.1.2分布式环境搭建
时间:2016-07-19 23:09 来源:linux.it.net.cn 作者:IT
hadoop1.1.2分布式安装
Hadoop简介

Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
环境说明
集群规划
集群中包括3个节点:1个Master,2个Slave,节点之间局域网连接,可以相互ping通,
机器名称
IP地址
节点说明
icity0
192.16.39.141
Master
icity1
192.16.39.174
Slave
icity2
192.16.39.175
Slave
3个节点上均是Redhat6系统,并且有一个相同的用户hadoop。Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;2个Salve机器配置DataNode和TaskTracker的角色,负责分布式数据存储以及任务的执行。
Linux服务器配置信息
[root@localhost ~]# uname -a
Linux localhost.localdomain2.6.32-220.el6.x86_64 #1 SMP Wed Nov 9 08:03:13 EST 2011 x86_64 x86_64 x86_64GNU/Linux
[root@localhost ~]# free
total used free shared buffers cached
Mem: 2054828 1928908 125920 0 67940 95796
-/+ buffers/cache: 1765172 289656
Swap: 6291448 511492 5779956
创建hadoop用户
[root@localhost ~]# uname -a
Linux localhost.localdomain 2.6.32-220.el6.x86_64#1 SMP Wed Nov 9 08:03:13 EST 2011 x86_64 x86_64 x86_64 GNU/Linux
[root@localhost ~]# free
total used free shared buffers cached
Mem: 2054828 1928908 125920 0 67940 95796
-/+ buffers/cache: 1765172 289656
Swap: 6291448 511492 5779956
1.3:创建hadoop用户
[root@localhost ~]# useradd hadoop
[root@localhost ~]# pwd hadoop
/root
[root@localhost ~]# passwd hadoop
Changing password for user hadoop.
New password:
BAD PASSWORD: it is WAY too short
BAD PASSWORD: is a palindrome
Retype new password:
Sorry, passwords do not match.
New password:
BAD PASSWORD: it is toosimplistic/systematic
BAD PASSWORD: is too simple
Retype new password:
passwd: all authentication tokens updatedsuccessfully.
[root@localhost ~]# su - hadoop
[hadoop@localhost ~]$ pwd
/home/hadoop
这里面我设置的密码是123456,所以比较简单,有提示,不用管,在另外两台服务器上按照这个操作创建hadoop用户。
修改网关
将141 服务器的hostname设置为icity0
vi /etc/sysconfig/network

依此操作将另外两台服务器修改为icity1 和 icity2;将此文件scp到另外两台服务器覆盖其上面的文件也可以。
设置完此部分,重启服务器。reboot。
配置hosts文件
将ip与hostname对应的信息写入hosts文件,如图所示:
vi /etc/hosts

依此操作将另外两台服务器修改为icity1 和 icity2;将此文件scp到另外两台服务器覆盖其上面的文件也可以。
配置完成后重启网卡:
service network restart
关闭防火墙
service iptables stop
建议将服务器按如下设置:
chkconfig iptables off --关闭防火墙开机启动
chkconfig iptables –list – 查看状态
如图所示:

依此操作另外两台服务器icity1和 icity2;
环境测试
每台服务器上操作,如图所示:

ping icity0
ping icity1
ping icity2
配置SSH无密码登录
SSH无密码原理
Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端Master复制到Slave上。
生成密钥
首先登陆141,切换到hadoop用户:
su – hadoop
执行:
ssh-keygen -t rsa
命令是生成其无密码密钥对,询问其保存路径时直接回车采用默认路径。生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/home/hadoop/.ssh"目录下。
如图所示:
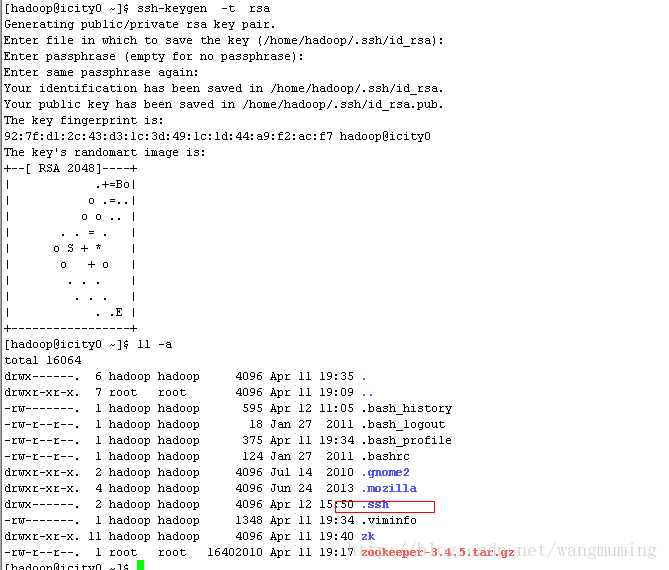
查看"/home/hadoop/"下是否有".ssh"文件夹,且".ssh"文件下是否有两个刚生产的无密码密钥对。

依此操作另外两台服务器icity1和 icity2;
Icity1:
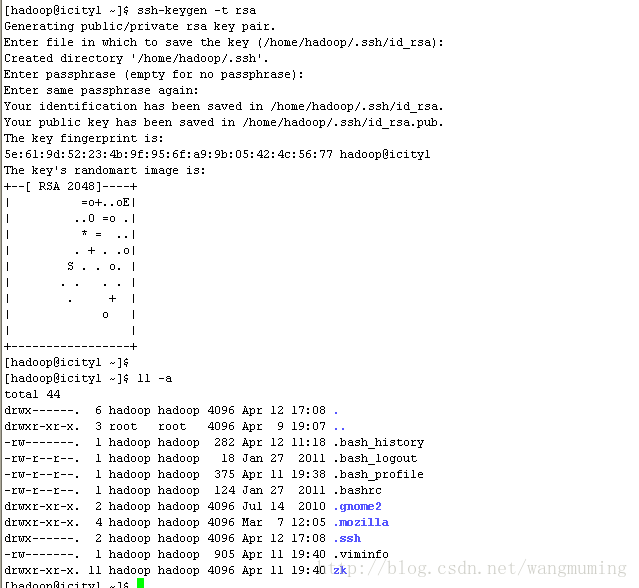
Icity2:

回到icity0服务器,切换到hadoop用户
cd /home/hadoop/.ssh
cp id_rsa.pub authorized_keys

回到hadoop目录,建立sshkey目录:

操作icity1和icity2服务器,将刚才生成的密钥文件scp到sshkey目录下面;
Icity1:

Icity2:

回到icity0服务器的hadoop用户,查看sshkey文件夹:

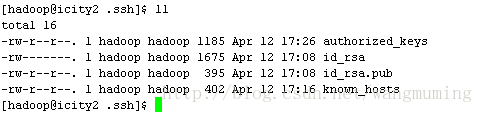
将icity1和icity2的密钥放入authorized_keys文件中,如图操作:
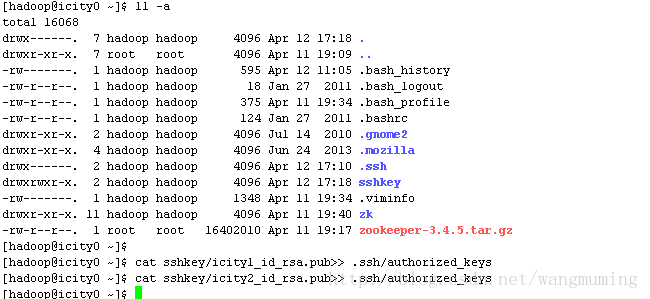
查看authorized_keys文件:

测试icity0无密码登录:
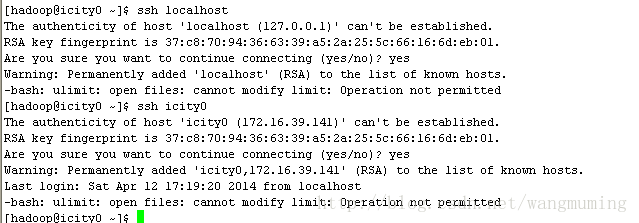
确实没有要求输入密码;
将icity0.ssh目录下面的authorized_keys文件scp到icity1和icity2 .ssh目录下面;
scp authorized_keys hadoop@icity1:/home/hadoop/.ssh/
scp authorized_keys hadoop@icity2:/home/hadoop/.ssh/
如图所示:

登录icity1和icity2的hadoop用户,查看文件:

回到icity0的hadoop用户,测试icity1和icity2的无密码登录验证:
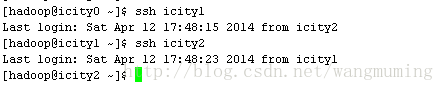


至此,无密码验证配置完成。
软件安装
Jdk安装配置
将jdk1.7上传到icity0服务器的/usr/java/目录下面,解压后如图所示:

解压完成后,将其scp到icity1和icity2服务器的/usr/java/目录下面,如果不存在java目录,先创建此java目录;
执行如下命令:
su – hadoop
scp -r /usr/java/jdk1.7.0_09hadoop@icity1:/usr/java/
scp -r /usr/java/jdk1.7.0_09 hadoop@icity2:/usr/java/
由于之前已经配置了无密码加密,故无需输入密码,直接执行命令即可。
配置jdk环境变量
在ictiy0服务器的hadoop用户下面,
su – haoop
vi .bash_profile

输入红圈中的内容即可。
依此操作另外两台服务器icity1和 icity2;
使配置生效
保存并退出,执行下面命令使其配置立即生效。
source .bash_profile
依此操作另外两台服务器icity1和 icity2;
“配置jdk环境变量”和“使配置生效”可以合为一步,将icity0配置好的.bash_profile文件scp到icity1和icity2 /home/haoop/目录下面,然后ssh icity1和ssh icity2上,执行
source .bash_profile 即可。
至此,jdk配置完成。
Hadoop安装
将hadoop1.1.2上传到icity0服务器的hadoop用户目录下面,如图所示:
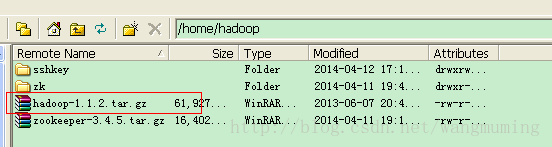
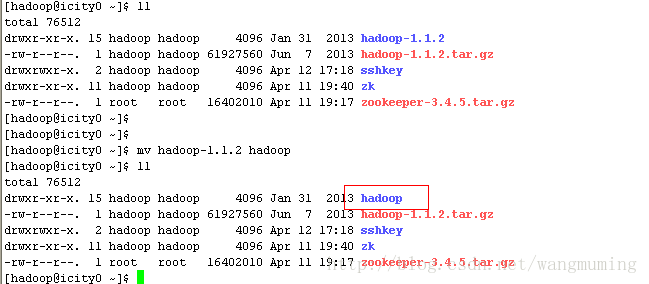
解压并重命名为hadoop,如图所示:
tar -zxvf hadoop-1.1.2.tar.gz
mv hadoop-1.1.2 hadoop
修改Hadoop的配置
修改conf/hadoop-env.sh
vi hadoop-env.sh
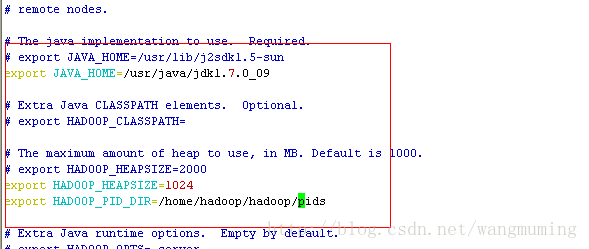
保存退出。
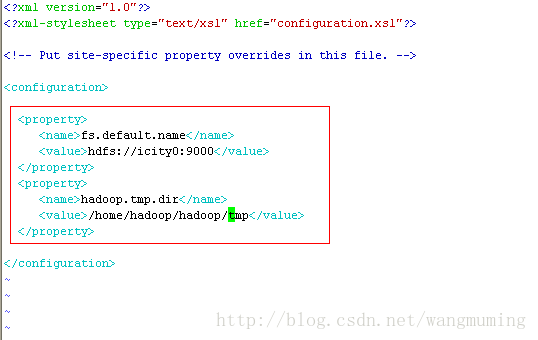
配置conf/core-site.xml
vi core-site.xml
增加如下内容:如图所示:
配置conf/hdfs-site.xml
vi hdfs-site.xml 增加如下内容,如图所示:

配置conf/mapred-site.xml
vi mapred-site.xml 增加如下内容,如图所示:

配置conf/masters
vi masters 增加如下内容,如图所示:

配置conf/slaves
vi slaves 增加如下内容,如图所示:

至此,hadoop配置完成。
配置hadoop环境变量
切换到icity0服务器,切换到hadoop用户,
配置.bash_profile文件,增加如下内容:
vi .bash_profile

保存退出。
使配置生效:
source .bash_profile
scp hadoop目录和文件到slave节点
将icity0 上面的hadoop安装目录和文件scp到icity1和icity2服务器上面。
scp -r hadoop hadoop@icity1:/home/hadoop/
scp -r hadoop hadoop@icity2:/home/hadoop/
scp .bash_profile 文件到slave节点
将.bash_profile配置文件scp到icity1和icity2的hadoop /home/hadoop/目录下面,然后ssh icity1和ssh icity2上,执行source .bash_profile即可。具体见图:

自此,所有配置工作完成,下面开始启动hadoop。
启动/停止Hadoop集群
启动hadoop集群
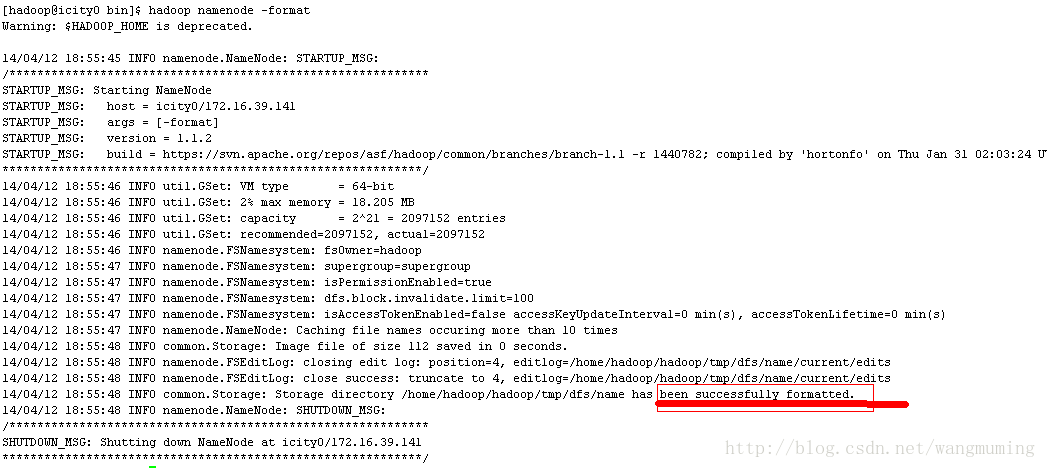
格式化
在icity0上第一次启动Hadoop,必须先格式化namenode
cd $HADOOP_HOME /bin
hadoop namenode –format
如图所示:
启动Hadoop
cd $HADOOP_HOME/bin
./start-all.sh
如果启动过程,报错safemode相关的Exception
执行命令
#hadoop dfsadmin -safemode leave
然后再启动Hadoop

启动没有报错。启动完成。
停止Hadoop
cd $HADOOP_HOME/bin
./stop-all.sh
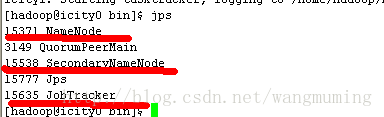
进程检查
在master icity0服务器上执行jps:存在3大进程:
NameNode
SecondaryNameNode
JobTracker
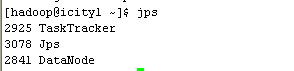
在slave上执行jps:存在进程:
DataNode
TaskTracker

终端查看集群状态
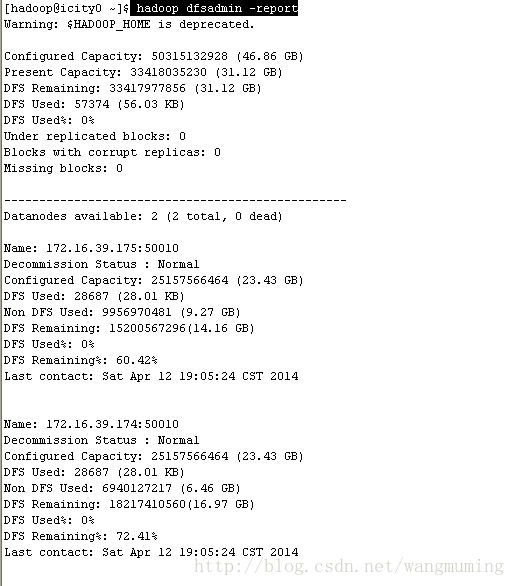
执行命令:
hadoop dfsadmin –report
如图所示:
到此,整个hadoop的分布式安装完成。
(责任编辑:IT)
hadoop1.1.2分布式安装 Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
环境说明集群规划集群中包括3个节点:1个Master,2个Slave,节点之间局域网连接,可以相互ping通,
3个节点上均是Redhat6系统,并且有一个相同的用户hadoop。Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;2个Salve机器配置DataNode和TaskTracker的角色,负责分布式数据存储以及任务的执行。
Linux服务器配置信息
[root@localhost ~]# uname -a Linux localhost.localdomain2.6.32-220.el6.x86_64 #1 SMP Wed Nov 9 08:03:13 EST 2011 x86_64 x86_64 x86_64GNU/Linux [root@localhost ~]# free total used free shared buffers cached Mem: 2054828 1928908 125920 0 67940 95796 -/+ buffers/cache: 1765172 289656 Swap: 6291448 511492 5779956
创建hadoop用户[root@localhost ~]# uname -a Linux localhost.localdomain 2.6.32-220.el6.x86_64#1 SMP Wed Nov 9 08:03:13 EST 2011 x86_64 x86_64 x86_64 GNU/Linux [root@localhost ~]# free total used free shared buffers cached Mem: 2054828 1928908 125920 0 67940 95796 -/+ buffers/cache: 1765172 289656 Swap: 6291448 511492 5779956
1.3:创建hadoop用户
[root@localhost ~]# useradd hadoop [root@localhost ~]# pwd hadoop /root [root@localhost ~]# passwd hadoop Changing password for user hadoop. New password: BAD PASSWORD: it is WAY too short BAD PASSWORD: is a palindrome Retype new password: Sorry, passwords do not match. New password: BAD PASSWORD: it is toosimplistic/systematic BAD PASSWORD: is too simple Retype new password: passwd: all authentication tokens updatedsuccessfully. [root@localhost ~]# su - hadoop [hadoop@localhost ~]$ pwd /home/hadoop
这里面我设置的密码是123456,所以比较简单,有提示,不用管,在另外两台服务器上按照这个操作创建hadoop用户。
修改网关将141 服务器的hostname设置为icity0 vi /etc/sysconfig/network
依此操作将另外两台服务器修改为icity1 和 icity2;将此文件scp到另外两台服务器覆盖其上面的文件也可以。
设置完此部分,重启服务器。reboot。
配置hosts文件将ip与hostname对应的信息写入hosts文件,如图所示: vi /etc/hosts
依此操作将另外两台服务器修改为icity1 和 icity2;将此文件scp到另外两台服务器覆盖其上面的文件也可以。
配置完成后重启网卡: service network restart
关闭防火墙service iptables stop
建议将服务器按如下设置: chkconfig iptables off --关闭防火墙开机启动 chkconfig iptables –list – 查看状态 如图所示:
依此操作另外两台服务器icity1和 icity2;
环境测试每台服务器上操作,如图所示:
ping icity0 ping icity1 ping icity2
配置SSH无密码登录SSH无密码原理Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端Master复制到Slave上。
生成密钥首先登陆141,切换到hadoop用户: su – hadoop 执行: ssh-keygen -t rsa 命令是生成其无密码密钥对,询问其保存路径时直接回车采用默认路径。生成的密钥对:id_rsa和id_rsa.pub,默认存储在"/home/hadoop/.ssh"目录下。 如图所示:
查看"/home/hadoop/"下是否有".ssh"文件夹,且".ssh"文件下是否有两个刚生产的无密码密钥对。
依此操作另外两台服务器icity1和 icity2;
Icity1:
Icity2:
回到icity0服务器,切换到hadoop用户
cd /home/hadoop/.ssh cp id_rsa.pub authorized_keys
回到hadoop目录,建立sshkey目录:
操作icity1和icity2服务器,将刚才生成的密钥文件scp到sshkey目录下面; Icity1:
Icity2:
回到icity0服务器的hadoop用户,查看sshkey文件夹:
将icity1和icity2的密钥放入authorized_keys文件中,如图操作:
查看authorized_keys文件:
测试icity0无密码登录:
确实没有要求输入密码;
将icity0.ssh目录下面的authorized_keys文件scp到icity1和icity2 .ssh目录下面; scp authorized_keys hadoop@icity1:/home/hadoop/.ssh/ scp authorized_keys hadoop@icity2:/home/hadoop/.ssh/ 如图所示:
登录icity1和icity2的hadoop用户,查看文件:
回到icity0的hadoop用户,测试icity1和icity2的无密码登录验证:
至此,无密码验证配置完成。
软件安装Jdk安装配置将jdk1.7上传到icity0服务器的/usr/java/目录下面,解压后如图所示:
解压完成后,将其scp到icity1和icity2服务器的/usr/java/目录下面,如果不存在java目录,先创建此java目录; 执行如下命令: su – hadoop scp -r /usr/java/jdk1.7.0_09hadoop@icity1:/usr/java/ scp -r /usr/java/jdk1.7.0_09 hadoop@icity2:/usr/java/
由于之前已经配置了无密码加密,故无需输入密码,直接执行命令即可。
配置jdk环境变量
在ictiy0服务器的hadoop用户下面, su – haoop vi .bash_profile
输入红圈中的内容即可。 依此操作另外两台服务器icity1和 icity2;
使配置生效保存并退出,执行下面命令使其配置立即生效。 source .bash_profile 依此操作另外两台服务器icity1和 icity2;
“配置jdk环境变量”和“使配置生效”可以合为一步,将icity0配置好的.bash_profile文件scp到icity1和icity2 /home/haoop/目录下面,然后ssh icity1和ssh icity2上,执行 source .bash_profile 即可。 至此,jdk配置完成。
Hadoop安装将hadoop1.1.2上传到icity0服务器的hadoop用户目录下面,如图所示:
解压并重命名为hadoop,如图所示: tar -zxvf hadoop-1.1.2.tar.gz mv hadoop-1.1.2 hadoop
修改Hadoop的配置修改conf/hadoop-env.shvi hadoop-env.sh
保存退出。
配置conf/core-site.xmlvi core-site.xml 增加如下内容:如图所示:
配置conf/hdfs-site.xmlvi hdfs-site.xml 增加如下内容,如图所示:
配置conf/mapred-site.xmlvi mapred-site.xml 增加如下内容,如图所示:
配置conf/mastersvi masters 增加如下内容,如图所示:
配置conf/slavesvi slaves 增加如下内容,如图所示:
至此,hadoop配置完成。
配置hadoop环境变量切换到icity0服务器,切换到hadoop用户, 配置.bash_profile文件,增加如下内容: vi .bash_profile
保存退出。 使配置生效: source .bash_profile
scp hadoop目录和文件到slave节点将icity0 上面的hadoop安装目录和文件scp到icity1和icity2服务器上面。 scp -r hadoop hadoop@icity1:/home/hadoop/ scp -r hadoop hadoop@icity2:/home/hadoop/
scp .bash_profile 文件到slave节点将.bash_profile配置文件scp到icity1和icity2的hadoop /home/hadoop/目录下面,然后ssh icity1和ssh icity2上,执行source .bash_profile即可。具体见图:
自此,所有配置工作完成,下面开始启动hadoop。
启动/停止Hadoop集群启动hadoop集群格式化在icity0上第一次启动Hadoop,必须先格式化namenode cd $HADOOP_HOME /bin hadoop namenode –format 如图所示:
启动Hadoopcd $HADOOP_HOME/bin ./start-all.sh 如果启动过程,报错safemode相关的Exception 执行命令 #hadoop dfsadmin -safemode leave 然后再启动Hadoop
启动没有报错。启动完成。
停止Hadoopcd $HADOOP_HOME/bin ./stop-all.sh
进程检查在master icity0服务器上执行jps:存在3大进程: NameNode SecondaryNameNode JobTracker
在slave上执行jps:存在进程: DataNode TaskTracker
终端查看集群状态执行命令: hadoop dfsadmin –report 如图所示:
到此,整个hadoop的分布式安装完成。 (责任编辑:IT) |