|
HadoopМвзхЯЕСаЮФеТЃЌжївЊНщЩмHadoopМвзхВњЦЗЃЌГЃгУЕФЯюФПАќРЈHadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, ChukwaЃЌаТдіМгЕФЯюФПАќРЈЃЌYARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, HueЕШЁЃ
Дг2011ФъПЊЪМЃЌжаЙњНјШыДѓЪ§ОнЗчЦ№дЦгПЕФЪБДњЃЌвдHadoopЮЊДњБэЕФМвзхШэМўЃЌеМОнСЫДѓЪ§ОнДІРэЕФЙуРЋЕиХЬЁЃПЊдДНчМАГЇЩЬЃЌЫљгаЪ§ОнШэМўЃЌЮовЛВЛЯђHadoopППТЃЁЃHadoopвВДгаЁжкЕФИпИЛЫЇСьгђЃЌБфГЩСЫДѓЪ§ОнПЊЗЂЕФБъзМЁЃдкHadoopдгаММЪѕЛљДЁжЎЩЯЃЌГіЯжСЫHadoopМвзхВњЦЗЃЌЭЈЙ§“ДѓЪ§Он”ИХФюВЛЖЯДДаТЃЌЭЦГіПЦММНјВНЁЃ
зїЮЊITНчЕФПЊЗЂШЫдБЃЌЮвУЧвВвЊИњЩЯНкзрЃЌзЅзЁЛњгіЃЌИњзХHadoopвЛЦ№алЦ№ЃЁ
ЙигкзїепЃК
-
еХЕЄ(Conan), ГЬађдБJava,R,PHP,Javascript
-
weiboЃК@Conan_Z
-
blog: http://blog.fens.me
-
email: bsspirit@gmail.com
зЊдиЧызЂУїГіДІЃК
http://blog.fens.me/hadoop-family-roadmap/

ЧАбд
ЪЙгУHadoopвбОгавЛЖЮЪБМфСЫЃЌДгПЊЪМЕФУдУЃЃЌЕНИїжжЕФГЂЪдЃЌЕНЯждкзщКЯгІгУ….Т§Т§ЕиЩцМАЕНЪ§ОнДІРэЕФЪТЧщЃЌвбОРыВЛПЊhadoopСЫЁЃHadoopдкДѓЪ§ОнСьгђЕФГЩЙІЃЌИќв§ЗЂСЫЫќБОЩэЕФМгЫйЗЂеЙЁЃЯждкHadoopМвзхВњЦЗЃЌвбОДяЕН20ИіСЫжЎЖрЁЃ
гаБивЊЖдздМКЕФжЊЪЖзівЛИіећРэСЫЃЌАбВњЦЗКЭММЪѕЖМДЎЦ№РДЁЃВЛНіФмМгЩюгЁЯѓЃЌИќПЩвдЖдвдКѓЕФММЪѕЗНЯђЃЌММЪѕбЁаЭзіКУЛљДЁзМБИЁЃ
БОЮФЮЊ“HadoopМвзх”ПЊЦЊЃЌHadoopМвзхбЇЯАТЗЯпЭМ
ФПТМ
-
HadoopМвзхВњЦЗ
-
HadoopМвзхбЇЯАТЗЯпЭМ
1. HadoopМвзхВњЦЗ
НижЙЕН2013ФъЃЌИљОнclouderaЕФЭГМЦЃЌHadoopМвзхВњЦЗвбОДяЕН20ИіЃЁ
http://blog.cloudera.com/blog/2013/01/apache-hadoop-in-2013-the-state-of-the-platform/
НгЯТРДЃЌЮвАбет20ИіВњЦЗЃЌЗжГЩСЫ2РрЁЃ
-
ЕквЛРрЃЌЪЧЮввбОеЦЮеЕФ
-
ЕкЖўРрЃЌЪЧTODOзМБИМЬајбЇЯАЕФ
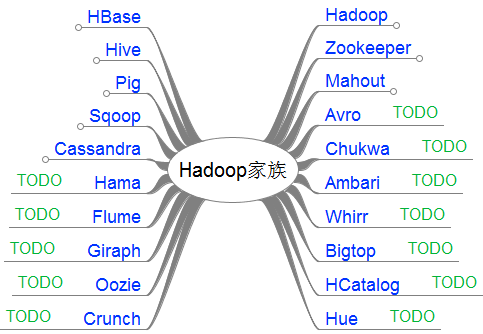
вЛОфЛАВњЦЗНщЩм:
-
Apache Hadoop: ЪЧApacheПЊдДзщжЏЕФвЛИіЗжВМЪНМЦЫуПЊдДПђМмЃЌЬсЙЉСЫвЛИіЗжВМЪНЮФМўЯЕЭГзгЯюФП(HDFS)КЭжЇГжMapReduceЗжВМЪНМЦЫуЕФШэМўМмЙЙЁЃ
-
Apache Hive: ЪЧЛљгкHadoopЕФвЛИіЪ§ОнВжПтЙЄОпЃЌПЩвдНЋНсЙЙЛЏЕФЪ§ОнЮФМўгГЩфЮЊвЛеХЪ§ОнПтБэЃЌЭЈЙ§РрSQLгяОфПьЫйЪЕЯжМђЕЅЕФMapReduceЭГМЦЃЌВЛБиПЊЗЂзЈУХЕФMapReduceгІгУЃЌЪЎЗжЪЪКЯЪ§ОнВжПтЕФЭГМЦЗжЮіЁЃ
-
Apache Pig: ЪЧвЛИіЛљгкHadoopЕФДѓЙцФЃЪ§ОнЗжЮіЙЄОпЃЌЫќЬсЙЉЕФSQL-LIKEгябдНаPig LatinЃЌИУгябдЕФБрвыЦїЛсАбРрSQLЕФЪ§ОнЗжЮіЧыЧѓзЊЛЛЮЊвЛЯЕСаОЙ§гХЛЏДІРэЕФMapReduceдЫЫуЁЃ
-
Apache HBase: ЪЧвЛИіИпПЩППадЁЂИпадФмЁЂУцЯђСаЁЂПЩЩьЫѕЕФЗжВМЪНДцДЂЯЕЭГЃЌРћгУHBaseММЪѕПЩдкСЎМлPC ServerЩЯДюНЈЦ№ДѓЙцФЃНсЙЙЛЏДцДЂМЏШКЁЃ
-
Apache Sqoop: ЪЧвЛИігУРДНЋHadoopКЭЙиЯЕаЭЪ§ОнПтжаЕФЪ§ОнЯрЛЅзЊвЦЕФЙЄОпЃЌПЩвдНЋвЛИіЙиЯЕаЭЪ§ОнПтЃЈMySQL ,Oracle ,PostgresЕШЃЉжаЕФЪ§ОнЕМНјЕНHadoopЕФHDFSжаЃЌвВПЩвдНЋHDFSЕФЪ§ОнЕМНјЕНЙиЯЕаЭЪ§ОнПтжаЁЃ
-
Apache Zookeeper: ЪЧвЛИіЮЊЗжВМЪНгІгУЫљЩшМЦЕФЗжВМЕФЁЂПЊдДЕФаЕїЗўЮёЃЌЫќжївЊЪЧгУРДНтОіЗжВМЪНгІгУжаОГЃгіЕНЕФвЛаЉЪ§ОнЙмРэЮЪЬтЃЌМђЛЏЗжВМЪНгІгУаЕїМАЦфЙмРэЕФФбЖШЃЌЬсЙЉИпадФмЕФЗжВМЪНЗўЮё
-
Apache Mahout:ЪЧЛљгкHadoopЕФЛњЦїбЇЯАКЭЪ§ОнЭкОђЕФвЛИіЗжВМЪНПђМмЁЃMahoutгУMapReduceЪЕЯжСЫВПЗжЪ§ОнЭкОђЫуЗЈЃЌНтОіСЫВЂааЭкОђЕФЮЪЬтЁЃ
-
Apache Cassandra:ЪЧвЛЬзПЊдДЗжВМЪНNoSQLЪ§ОнПтЯЕЭГЁЃЫќзюГѕгЩFacebookПЊЗЂЃЌгУгкДЂДцМђЕЅИёЪНЪ§ОнЃЌМЏGoogle BigTableЕФЪ§ОнФЃаЭгыAmazon DynamoЕФЭъШЋЗжВМЪНЕФМмЙЙгквЛЩэ
-
Apache Avro: ЪЧвЛИіЪ§ОнађСаЛЏЯЕЭГЃЌЩшМЦгУгкжЇГжЪ§ОнУмМЏаЭЃЌДѓХњСПЪ§ОнНЛЛЛЕФгІгУЁЃAvroЪЧаТЕФЪ§ОнађСаЛЏИёЪНгыДЋЪфЙЄОпЃЌНЋж№ВНШЁДњHadoopдгаЕФIPCЛњжЦ
-
Apache Ambari: ЪЧвЛжжЛљгкWebЕФЙЄОпЃЌжЇГжHadoopМЏШКЕФЙЉгІЁЂЙмРэКЭМрПиЁЃ
-
Apache Chukwa: ЪЧвЛИіПЊдДЕФгУгкМрПиДѓаЭЗжВМЪНЯЕЭГЕФЪ§ОнЪеМЏЯЕЭГЃЌЫќПЩвдНЋИїжжИїбљРраЭЕФЪ§ОнЪеМЏГЩЪЪКЯ Hadoop ДІРэЕФЮФМўБЃДцдк HDFS жаЙЉ Hadoop НјааИїжж MapReduce ВйзїЁЃ
-
Apache Hama: ЪЧвЛИіЛљгкHDFSЕФBSPЃЈBulk Synchronous Parallel)ВЂааМЦЫуПђМм, HamaПЩгУгкАќРЈЭМЁЂОиеѓКЭЭјТчЫуЗЈдкФкЕФДѓЙцФЃЁЂДѓЪ§ОнМЦЫуЁЃ
-
Apache Flume: ЪЧвЛИіЗжВМЕФЁЂПЩППЕФЁЂИпПЩгУЕФКЃСПШежООлКЯЕФЯЕЭГЃЌПЩгУгкШежОЪ§ОнЪеМЏЃЌШежОЪ§ОнДІРэЃЌШежОЪ§ОнДЋЪфЁЃ
-
Apache Giraph: ЪЧвЛИіПЩЩьЫѕЕФЗжВМЪНЕќДњЭМДІРэЯЕЭГЃЌ ЛљгкHadoopЦНЬЈЃЌСщИаРДзд BSP (bulk synchronous parallel) КЭ Google ЕФ PregelЁЃ
-
Apache Oozie: ЪЧвЛИіЙЄзїСїв§ЧцЗўЮёЦї, гУгкЙмРэКЭаЕїдЫаадкHadoopЦНЬЈЩЯЃЈHDFSЁЂPigКЭMapReduceЃЉЕФШЮЮёЁЃ
-
Apache Crunch: ЪЧЛљгкGoogleЕФFlumeJavaПтБраДЕФJavaПтЃЌгУгкДДНЈMapReduceГЬађЁЃгыHiveЃЌPigРрЫЦЃЌCrunchЬсЙЉСЫгУгкЪЕЯжШчСЌНгЪ§ОнЁЂжДааОлКЯКЭХХађМЧТМЕШГЃМћШЮЮёЕФФЃЪНПт
-
Apache Whirr: ЪЧвЛЬздЫаагкдЦЗўЮёЕФРрПтЃЈАќРЈHadoopЃЉЃЌПЩЬсЙЉИпЖШЕФЛЅВЙадЁЃWhirrбЇжЇГжAmazon EC2КЭRackspaceЕФЗўЮёЁЃ
-
Apache Bigtop: ЪЧвЛИіЖдHadoopМАЦфжмБпЩњЬЌНјааДђАќЃЌЗжЗЂКЭВтЪдЕФЙЄОпЁЃ
-
Apache HCatalog: ЪЧЛљгкHadoopЕФЪ§ОнБэКЭДцДЂЙмРэЃЌЪЕЯжжабыЕФдЊЪ§ОнКЭФЃЪНЙмРэЃЌПчдНHadoopКЭRDBMSЃЌРћгУPigКЭHiveЬсЙЉЙиЯЕЪгЭМЁЃ
-
Cloudera Hue: ЪЧвЛИіЛљгкWEBЕФМрПиКЭЙмРэЯЕЭГЃЌЪЕЯжЖдHDFSЃЌMapReduce/YARN, HBase, Hive, PigЕФwebЛЏВйзїКЭЙмРэЁЃ
2. HadoopМвзхбЇЯАТЗЯпЭМ
ЯТУцЮвНЋЗжБ№НщЩмИїИіВњЦЗЕФАВзАКЭЪЙгУЃЌвдЮвОбщзмНсЮвЕФбЇЯАТЗЯпЁЃ
Hadoop
Hive
Pig
Zookeeper
HBase
Mahout
Sqoop
Cassandra
(д№ШЮБрМЃКIT) |