SQL基础之GROUPING
时间:2019-01-06 00:10 来源:未知 作者:IT
1.grouping sets
记得前几天第一次接触grouping sets时,笔者的感觉是一脸懵逼。
后来一不小心看到msdn上对grouping sets的说明,顿时豁然开朗,其实grouping sets就是由多个group by联合起来,关系如下。
select A , B from table group by grouping sets(A, B) 等价于
select A , null as B from table group by A
union all
select null as A , B from table group by B
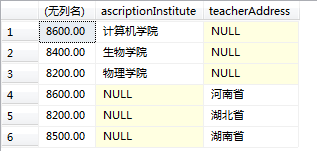
为了更好的理解我创建了teacher表,表数据如下,查询结果集中左边的为使用union all的group by字句,右边的为使用grouping sets的结果集。

select null as teacherAddress,MAX(teacherSalary),ascriptionInstitute from teacher group by ascriptionInstitute
union all
select teacherAddress,MAX(teacherSalary),NULL as ascriptionInstitute from teacher group by teacherAddress
select teacherAddress,MAX(teacherSalary),ascriptionInstitute from teacher group by GROUPING SETS (ascriptionInstitute,teacherAddress)


上面提到grouping sets是等价于带union all的group by子句,之所以是等价而不是等于,从两者结果集中的对比就可以一目了之,那就是它们的顺序不一样。这说明grouping sets并不只是group by的语法糖,这两者内部的执行过程应该是全然不同的,在百度过程中发现大多数答案都是这句话:“聚合是一次性从数据库中取出所有需要操作的数据,在内存中对数据库进行聚合操作并生成结果。而UNION ALL是多次扫描表,将返回的结果进行UNION操作。性能方面grouping sets能减少IO操作但会增加CPU占用时间”。我不理解的地方是一次性取出数据后,是如何在内存中进行聚合操作的?结果集虽然顺序不一样但数据是相同的,这说明依旧进行了联合操作而这个联合操作并不是多次扫描表,关键内部多次是如何扫描的我很好奇?对于性能我想知道为什么会这样子而不是看到现象。另外在grouping sets中如果将括号中的参数换个位置那么结果也将改变,这说明结果集中的顺序与参数的位置也有关,这让我更加好奇grouping sets的内部执行过程了。
select MAX(teacherSalary),ascriptionInstitute ,teacherAddress from teacher group by GROUPING SETS (ascriptionInstitute,teacherAddress)
select MAX(teacherSalary),ascriptionInstitute ,teacherAddress from teacher group by GROUPING SETS (teacherAddress,ascriptionInstitute)

2.grouping( )
grouping函数用来区分NULL值,这里NULL值有2种情况,一是原本表中的数据就为NULL,二是由rollup、cube、grouping sets生成的NULL值。
当为第一种情况中的空值时,grouping(NULL)返回0;当为第二种情况中的空值时,grouping(NULL)返回1。实例如下,从结果中可以看到第二个结果集中原本为null的数据由于grouping函数为1,故显示ROLLUP-NULL字符串。
select teacherAddress,ascriptionInstitute,COUNT(teacherId ) from teacher group by teacherAddress,ascriptionInstitute
select teacherAddress,ascriptionInstitute,COUNT(teacherId ) from teacher group by rollup(teacherAddress,ascriptionInstitute)
select ISNULL(teacherAddress,case when GROUPING(teacherAddress)=1 then 'ROLLUP-NULL' end) as teacherAddress,
ISNULL(ascriptionInstitute,case when GROUPING(ascriptionInstitute)=1 then 'ROLLUP-NULL' end) as ascriptionInstitute,
COUNT(teacherId )
from teacher group by rollup(teacherAddress,ascriptionInstitute)



3.grouping_id( )
grouping_id函数也是计算分组级别的函数,注意如果要使用grouping_id函数那必须得有group by字句,而且group by字句的中的列与grouping_id函数的参数必须相等。比如group by A,B,那么必须使用grouping_id(A,B)。下面用一个等效关系来说明grouping_id()与grouping()的联系,grouping_id(A, B)等效于grouping(A) + grouping(B),但要注意这里的+号不是算术相加,它表示的是二进制数据组合在一起,比如grouping(A)=1,grouping(B)=1,那么grouping_id(A, B)=11B,也就是十进制数3。原来的表数据执行下面的sql语句结果太多效果不明显,所以我改了下表数据,不过对比两个结果集效果很明显。
select ISNULL(teacherAddress,case when GROUPING(teacherAddress)=1 then 'ROLLUP-NULL' end) as teacherAddress,
ISNULL(ascriptionInstitute,case when GROUPING(ascriptionInstitute)=1 then 'ROLLUP-NULL' end) as ascriptionInstitute,
ISNULL(teacherSex,case when GROUPING(teacherSex)=1 then 'ROLLUP-NULL' end) as teacherSex,
COUNT(teacherId )
from teacher group by rollup(teacherAddress,ascriptionInstitute,teacherSex)
select ISNULL(teacherAddress,case when GROUPING(teacherAddress)=1 then 'ROLLUP-NULL' end) as teacherAddress,
ISNULL(ascriptionInstitute,case when GROUPING(ascriptionInstitute)=1 then 'ROLLUP-NULL' end) as ascriptionInstitute,
ISNULL(teacherSex,case when GROUPING(teacherSex)=1 then 'ROLLUP-NULL' end) as teacherSex,
COUNT(teacherId ) as '数量' ,
GROUPING_ID(teacherAddress,ascriptionInstitute,teacherSex)
from teacher group by rollup(teacherAddress,ascriptionInstitute,teacherSex)


(责任编辑:IT)
1.grouping sets 记得前几天第一次接触grouping sets时,笔者的感觉是一脸懵逼。 后来一不小心看到msdn上对grouping sets的说明,顿时豁然开朗,其实grouping sets就是由多个group by联合起来,关系如下。 select A , B from table group by grouping sets(A, B) 等价于 select A , null as B from table group by A union all select null as A , B from table group by B 为了更好的理解我创建了teacher表,表数据如下,查询结果集中左边的为使用union all的group by字句,右边的为使用grouping sets的结果集。
select null as teacherAddress,MAX(teacherSalary),ascriptionInstitute from teacher group by ascriptionInstitute union all select teacherAddress,MAX(teacherSalary),NULL as ascriptionInstitute from teacher group by teacherAddress select teacherAddress,MAX(teacherSalary),ascriptionInstitute from teacher group by GROUPING SETS (ascriptionInstitute,teacherAddress)
上面提到grouping sets是等价于带union all的group by子句,之所以是等价而不是等于,从两者结果集中的对比就可以一目了之,那就是它们的顺序不一样。这说明grouping sets并不只是group by的语法糖,这两者内部的执行过程应该是全然不同的,在百度过程中发现大多数答案都是这句话:“聚合是一次性从数据库中取出所有需要操作的数据,在内存中对数据库进行聚合操作并生成结果。而UNION ALL是多次扫描表,将返回的结果进行UNION操作。性能方面grouping sets能减少IO操作但会增加CPU占用时间”。我不理解的地方是一次性取出数据后,是如何在内存中进行聚合操作的?结果集虽然顺序不一样但数据是相同的,这说明依旧进行了联合操作而这个联合操作并不是多次扫描表,关键内部多次是如何扫描的我很好奇?对于性能我想知道为什么会这样子而不是看到现象。另外在grouping sets中如果将括号中的参数换个位置那么结果也将改变,这说明结果集中的顺序与参数的位置也有关,这让我更加好奇grouping sets的内部执行过程了。 select MAX(teacherSalary),ascriptionInstitute ,teacherAddress from teacher group by GROUPING SETS (ascriptionInstitute,teacherAddress) select MAX(teacherSalary),ascriptionInstitute ,teacherAddress from teacher group by GROUPING SETS (teacherAddress,ascriptionInstitute)
2.grouping( ) grouping函数用来区分NULL值,这里NULL值有2种情况,一是原本表中的数据就为NULL,二是由rollup、cube、grouping sets生成的NULL值。 当为第一种情况中的空值时,grouping(NULL)返回0;当为第二种情况中的空值时,grouping(NULL)返回1。实例如下,从结果中可以看到第二个结果集中原本为null的数据由于grouping函数为1,故显示ROLLUP-NULL字符串。 select teacherAddress,ascriptionInstitute,COUNT(teacherId ) from teacher group by teacherAddress,ascriptionInstitute select teacherAddress,ascriptionInstitute,COUNT(teacherId ) from teacher group by rollup(teacherAddress,ascriptionInstitute) select ISNULL(teacherAddress,case when GROUPING(teacherAddress)=1 then 'ROLLUP-NULL' end) as teacherAddress, ISNULL(ascriptionInstitute,case when GROUPING(ascriptionInstitute)=1 then 'ROLLUP-NULL' end) as ascriptionInstitute, COUNT(teacherId ) from teacher group by rollup(teacherAddress,ascriptionInstitute)
3.grouping_id( ) grouping_id函数也是计算分组级别的函数,注意如果要使用grouping_id函数那必须得有group by字句,而且group by字句的中的列与grouping_id函数的参数必须相等。比如group by A,B,那么必须使用grouping_id(A,B)。下面用一个等效关系来说明grouping_id()与grouping()的联系,grouping_id(A, B)等效于grouping(A) + grouping(B),但要注意这里的+号不是算术相加,它表示的是二进制数据组合在一起,比如grouping(A)=1,grouping(B)=1,那么grouping_id(A, B)=11B,也就是十进制数3。原来的表数据执行下面的sql语句结果太多效果不明显,所以我改了下表数据,不过对比两个结果集效果很明显。 select ISNULL(teacherAddress,case when GROUPING(teacherAddress)=1 then 'ROLLUP-NULL' end) as teacherAddress, ISNULL(ascriptionInstitute,case when GROUPING(ascriptionInstitute)=1 then 'ROLLUP-NULL' end) as ascriptionInstitute, ISNULL(teacherSex,case when GROUPING(teacherSex)=1 then 'ROLLUP-NULL' end) as teacherSex, COUNT(teacherId ) from teacher group by rollup(teacherAddress,ascriptionInstitute,teacherSex) select ISNULL(teacherAddress,case when GROUPING(teacherAddress)=1 then 'ROLLUP-NULL' end) as teacherAddress, ISNULL(ascriptionInstitute,case when GROUPING(ascriptionInstitute)=1 then 'ROLLUP-NULL' end) as ascriptionInstitute, ISNULL(teacherSex,case when GROUPING(teacherSex)=1 then 'ROLLUP-NULL' end) as teacherSex, COUNT(teacherId ) as '数量' , GROUPING_ID(teacherAddress,ascriptionInstitute,teacherSex) from teacher group by rollup(teacherAddress,ascriptionInstitute,teacherSex)
(责任编辑:IT) |