sql 查询 某字段 重复次数 最多的记录
时间:2019-05-15 16:41 来源:linux.it.net.cn 作者:IT
需求 查询小时气象表中 同一日期、同一城市、同意检测站点 首要污染物出现出书最多的记录
第一步: 添加 排序字段
select StationID,RecordDate,CityID,Primary_Pollutant,ROW_NUMBER() over(partition by StationID,RecordDate,CityID order by count(0) desc ) as Numfrom T_AirHourly
group by StationID,RecordDate,CityID,Primary_Pollutant
第二步 子查询:在查询的基础上再次查询
select StationID,RecordDate,CityID,Primary_Pollutant from (
select StationID,RecordDate,CityID,Primary_Pollutant,ROW_NUMBER() over(partition by StationID,RecordDate,CityID order by count(0) desc ) as Numfrom T_AirHourly
group by StationID,RecordDate,CityID,Primary_Pollutant
)t where t.Num = 1
第三步 创建视图
create view V_Primary_Pollutant as
select StationID,RecordDate,CityID,Primary_Pollutant from (
select StationID,RecordDate,CityID,Primary_Pollutant,ROW_NUMBER() over(partition by StationID,RecordDate,CityID order by count(0) desc ) as Numfrom T_AirHourly
group by StationID,RecordDate,CityID,Primary_Pollutant
)t where t.Num = 1
结果:
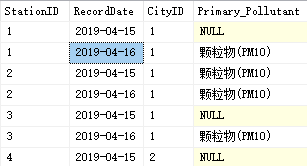
第五步: 统计一天中各种污染物的平均值
将视图作为独立模块 左连接查询 统计一天 各种污染物的平均值。
转载:
row_ number over函数的基本用法
https://xiaoxiaoher.iteye.com/blog/2428619
函数语法: ROW_NUMBER() OVER(PARTITION BY COLUMN ORDER BY COLUMN)
函数作用:从1开始,为按组排序的每条记录添加一个序列号 函数只能用于select和order by子句中 不能用在where子句
不分组排序
不进行分组时语法为ROW_NUMBER() OVER(ORDER BY COLUMN),如:
有一个表A就一个字段num,数据如下
num
10
20
30
查询语句为select row_number() over(order by num) as idx,num from A
结果如下
num idx
10 1
20 2
30 3
分组排序
分组的话ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2)表示根据COL1分组,在分组内部根据COL2排序,
而此函数的结果值就表示每组内部排序后的顺序编号(组内连续的惟一的)
表employee有数据如下
empid deptid salary
1 10 5500.00
2 10 4500.00
3 20 1900.00
4 20 4800.00
查询语句为:select *,row_number() over(partition by deptid order by salary desc) rank from employee
结果如下
empid deptid salary rank
1 10 5500.00 1
2 10 4500.00 2
4 20 4800.00 1
3 20 1900.00 2
比较
可以看到这个函数不分组时的作用oracle自带row_num也能完成,差别就是row_num从0开始。分组排序这个功能就比较强大
另外还有两个类似函数rank() over() 和dense_rank() over()
区别就是如果排序字段有重复值
row_number()函数还是1 2 3排下去
rank() over()则会出现 1 1 3
dense_rank() over() 则会出现 1 1 2
这三种情况 就是给的序号不一样
ROW_NUMBER() OVER()函数用法;(分组,排序),partition by
转载:https://www.cnblogs.com/alsf/p/6344197.html
http://www.cnblogs.com/BluceLee/p/8004716.html
1、row_number() over()排序功能:
(1) row_number() over()分组排序功能:
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where group by order by 的执行。
partition by 用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组,它和聚合函数不同的地方在于它能够返回一个分组中的多条记录,而聚合函数一般只有一个反映统计值的记录。
例如:employee,根据部门分组排序。
SELECT empno,WORKDEPT,SALARY, Row_Number() OVER (partition by workdept ORDER BY salary desc) rank FROM employee
--------------------------------------
000010 A00 152750 1
000110 A00 66500 2
000120 A00 49250 3
200010 A00 46500 4
200120 A00 39250 5
000020 B01 94250 1
000030 C01 98250 1
000130 C01 73800 2
(2)对查询结果进行排序:(无分组)
SELECT empno,WORKDEPT,SALARY, Row_Number() OVER (ORDER BY salary desc) rank FROM employee
--------------------------------------
000010 A00 152750 1
000030 C01 98250 2
000070 D21 96170 3
000020 B01 94250 4
000090 E11 89750 5
000100 E21 86150 6
000050 E01 80175 7
000130 C01 73800 8
000060 D11 72250 9
row_number() over()和rownum差不多,功能更强一点(可以在各个分组内从1开时排序).
2、rank() over()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内).
select workdept,salary,rank() over(partition by workdept order by salary) as dense_rank_order from emp order by workdept;
------------------
A00 39250 1
A00 46500 2
A00 49250 3
A00 66500 4
A00 152750 5
B01 94250 1
C01 68420 1
C01 68420 1
C01 73800 3
3、dense_rank() over()是连续排序,有两个第二名时仍然跟着第三名。相比之下row_number是没有重复值的 .
select workdept,salary,dense_rank() over(partition by workdept order by salary) as dense_rank_order from emp order by workdept;
------------------
A00 39250 1
A00 46500 2
A00 49250 3
A00 66500 4
A00 152750 5
B01 94250 1
C01 68420 1
C01 68420 1
C01 73800 2
C01 98250 3
使用ROW_NUMBER删除重复数据
---假设表TAB中有a,b,c三列,可以使用下列语句删除a,b,c都相同的重复行。
DELETE FROM (select year,QUARTER,RESULTS,row_number() over(partition by YEAR,QUARTER,RESULTS order by YEAR,QUARTER,RESULTS) AS ROW_NO FROM SALE )
WHERE ROW_NO>1
(责任编辑:IT)
需求 查询小时气象表中 同一日期、同一城市、同意检测站点 首要污染物出现出书最多的记录第一步: 添加 排序字段 select StationID,RecordDate,CityID,Primary_Pollutant,ROW_NUMBER() over(partition by StationID,RecordDate,CityID order by count(0) desc ) as Numfrom T_AirHourly group by StationID,RecordDate,CityID,Primary_Pollutant 第二步 子查询:在查询的基础上再次查询 select StationID,RecordDate,CityID,Primary_Pollutant from ( select StationID,RecordDate,CityID,Primary_Pollutant,ROW_NUMBER() over(partition by StationID,RecordDate,CityID order by count(0) desc ) as Numfrom T_AirHourly group by StationID,RecordDate,CityID,Primary_Pollutant )t where t.Num = 1 第三步 创建视图 create view V_Primary_Pollutant as select StationID,RecordDate,CityID,Primary_Pollutant from ( select StationID,RecordDate,CityID,Primary_Pollutant,ROW_NUMBER() over(partition by StationID,RecordDate,CityID order by count(0) desc ) as Numfrom T_AirHourly group by StationID,RecordDate,CityID,Primary_Pollutant )t where t.Num = 1 结果:
第五步: 统计一天中各种污染物的平均值 将视图作为独立模块 左连接查询 统计一天 各种污染物的平均值。
转载: row_ number over函数的基本用法https://xiaoxiaoher.iteye.com/blog/2428619 函数语法: ROW_NUMBER() OVER(PARTITION BY COLUMN ORDER BY COLUMN) 函数作用:从1开始,为按组排序的每条记录添加一个序列号 函数只能用于select和order by子句中 不能用在where子句
不分组排序 不进行分组时语法为ROW_NUMBER() OVER(ORDER BY COLUMN),如: 有一个表A就一个字段num,数据如下 num 10 20 30 查询语句为select row_number() over(order by num) as idx,num from A 结果如下 num idx 10 1 20 2 30 3
分组排序 分组的话ROW_NUMBER() OVER(PARTITION BY COL1 ORDER BY COL2)表示根据COL1分组,在分组内部根据COL2排序, 而此函数的结果值就表示每组内部排序后的顺序编号(组内连续的惟一的) 表employee有数据如下 empid deptid salary 1 10 5500.00 2 10 4500.00 3 20 1900.00 4 20 4800.00 查询语句为:select *,row_number() over(partition by deptid order by salary desc) rank from employee 结果如下 empid deptid salary rank 1 10 5500.00 1 2 10 4500.00 2 4 20 4800.00 1 3 20 1900.00 2
比较 可以看到这个函数不分组时的作用oracle自带row_num也能完成,差别就是row_num从0开始。分组排序这个功能就比较强大 另外还有两个类似函数rank() over() 和dense_rank() over() 区别就是如果排序字段有重复值 row_number()函数还是1 2 3排下去 rank() over()则会出现 1 1 3 dense_rank() over() 则会出现 1 1 2 这三种情况 就是给的序号不一样
ROW_NUMBER() OVER()函数用法;(分组,排序),partition by转载:https://www.cnblogs.com/alsf/p/6344197.html http://www.cnblogs.com/BluceLee/p/8004716.html 1、row_number() over()排序功能: (1) row_number() over()分组排序功能: 在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where group by order by 的执行。 partition by 用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组,它和聚合函数不同的地方在于它能够返回一个分组中的多条记录,而聚合函数一般只有一个反映统计值的记录。 例如:employee,根据部门分组排序。 SELECT empno,WORKDEPT,SALARY, Row_Number() OVER (partition by workdept ORDER BY salary desc) rank FROM employee -------------------------------------- 000010 A00 152750 1 000110 A00 66500 2 000120 A00 49250 3 200010 A00 46500 4 200120 A00 39250 5 000020 B01 94250 1 000030 C01 98250 1 000130 C01 73800 2 (2)对查询结果进行排序:(无分组) SELECT empno,WORKDEPT,SALARY, Row_Number() OVER (ORDER BY salary desc) rank FROM employee -------------------------------------- 000010 A00 152750 1 000030 C01 98250 2 000070 D21 96170 3 000020 B01 94250 4 000090 E11 89750 5 000100 E21 86150 6 000050 E01 80175 7 000130 C01 73800 8 000060 D11 72250 9 row_number() over()和rownum差不多,功能更强一点(可以在各个分组内从1开时排序).
2、rank() over()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内). select workdept,salary,rank() over(partition by workdept order by salary) as dense_rank_order from emp order by workdept; ------------------ A00 39250 1 A00 46500 2 A00 49250 3 A00 66500 4 A00 152750 5 B01 94250 1 C01 68420 1 C01 68420 1 C01 73800 3 3、dense_rank() over()是连续排序,有两个第二名时仍然跟着第三名。相比之下row_number是没有重复值的 . select workdept,salary,dense_rank() over(partition by workdept order by salary) as dense_rank_order from emp order by workdept; ------------------ A00 39250 1 A00 46500 2 A00 49250 3 A00 66500 4 A00 152750 5 B01 94250 1 C01 68420 1 C01 68420 1 C01 73800 2 C01 98250 3
使用ROW_NUMBER删除重复数据 DELETE FROM (select year,QUARTER,RESULTS,row_number() over(partition by YEAR,QUARTER,RESULTS order by YEAR,QUARTER,RESULTS) AS ROW_NO FROM SALE ) WHERE ROW_NO>1 (责任编辑:IT) |