Redis集群监控方法
时间:2019-05-21 14:38 来源:linux.it.net.cn 作者:IT
1. 技术领域
提供一种Redis集群中各Redis节点的监控处理方法,能够采集Redis节点的资源信息、性能指标数据,集群内多个Redis节点服务运行状态监控。实现告警监控信息、资源和性能指标的采集与分析的监控方法。
2. 背景技术
2.1 Redis简介
Redis 是一种开源的内存中key-value数据结构存储系统,它可以用作数据库、缓存和消息中间件。它支持多种类型的数据结构,如字符串(strings), 散列(hashes), 列表(lists), 集合(sets),有序集合(sorted sets)与范围查询。Redis也可以被看成是一个数据结构服务器。Redis的所有数据都是保存在内存中,然后不定期的通过异步方式保存到磁盘上。
Redis可使用一个或多个Redis哨兵(Sentinel),和Redis的主节点(Master)、 多个从节点(Slave)组成一个集群。Sentinel来检测Redis的Master节点是否运行正常,并在Master节点发生故障时,将 Master的Slave提升为Master,并在老的Master重新加入到Sentinel的群集之后,会被重新配置,作为新Master的Slave。基于Redis的 Sentinel可实现集群的高可用管理功能。
2.2 Redis监控方法
Redis 监控最直接的方法就是在装有Redis的服务器上使用Redis服务提供的 INFO 命令,只需要执行下面一条命令:
./redis-cli -p 端口号info
会返回一个Redis节点的Server、Clients、Memory、Persistence、Stats、Replication、CPU、Keyspace 8个部分的结果信息。从INFO返回结果中得到相关信息,就可以达到监控一个Redis节点的目的。
如下结果返回的是一个Redis的Master节点的信息:
# Server
redis_version:2.8.8 # Redis 的版本
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:bf5d1747be5380f
redis_mode:standalone
os:Linux 2.6.32-220.7.1.el6.x86_64 x86_64
arch_bits:64
gcc_version:4.4.7 #gcc版本
process_id:49324 # 当前 Redis 服务器进程id
run_id:bbd7b17efcf108fdde285d8987e50392f6a38f48
tcp_port:6379
uptime_in_seconds:1739082 # 运行时间(秒)
uptime_in_days:20 # 运行时间(天)
# Clients
connected_clients:1 #连接的客户端数量
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0
# Memory
used_memory:821848 #Redis分配的内存总量
used_memory_human:802.59K
used_memory_rss:85532672 #Redis分配的内存总量(包括内存碎片)
used_memory_peak:178987632
used_memory_peak_human:170.70M #Redis所用内存的高峰值
used_memory_lua:33792
mem_fragmentation_ratio:104.07 #内存碎片比率
mem_allocator:tcmalloc-2.0
# Persistence
loading:0
rdb_changes_since_last_save:0 #上次保存数据库之后,执行命令的次数
rdb_bgsave_in_progress:0 #后台进行中的 save 操作的数量
rdb_last_save_time:1410848500 #最后一次成功保存时间点
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
# Stats
total_connections_received:5705 #运行以来连接过的客户端的总数量
total_commands_processed:204013 #运行以来执行过的命令的总数量
instantaneous_ops_per_sec:0
rejected_connections:0
expired_keys:34401 #运行以来过期的 key 的数量
evicted_keys:0 #运行以来删除过的key的数量
keyspace_hits:2129 #命中key 的次数
keyspace_misses:3148 #没命中key 的次数
# Replication
role:master #当前实例的角色master还是slave
connected_slaves:0
master_repl_offset:0
# CPU
used_cpu_sys:1551.61
used_cpu_user:1083.37
used_cpu_sys_children:2.52
used_cpu_user_children:16.79
# Keyspace
db0:keys=3,expires=0,avg_ttl=0 #各个数据库key 的数量,以及带有生存期的 key 的数量
以上字符串就是这个Redis节点带有固定格式的一些字段属性和值。
同样通过INFO命令,对一个Sentinel节点返回的信息如下:
# Sentinel
sentinel_masters:3
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=common, status=ok,address=192.168.95.111:56379,slaves=1,sentinels=3
master1:name=resource1,status=ok,address=192.168.95.112:56379,slaves=1,sentinels=3
master2:name=resource2,status=ok,address=192.168.95.113:56379,slaves=1,sentinels=3
由返回信息可得知这个Sentinel目前管理了3个Master,并分别给出了Master的IP和端口,每个Master各有一个Slave。
3.技术方案描述
3.1 要解决的技术问题
通过在Redis服务器上执行INFO命令可以得到当前Redis节点的结果信息,但需要手工执行命令,结果信息可读性不强,不直观,不能达到自动监控的目的。 理想监控方案是在公司目前的监控产品中,集成Redis的集群监控方案,能够周期性、不间断的自动采集Redis各节点的数据信息,实时上报Redis节点的监控指标和状态,和Redis集群的服务状态信息。
3.2 整体思路
Redis的Sentinel作为Redis的高可用方案,可以实现Redis的Mater和Slave之间高可用和故障自动切换。以公司某监控产品环境中的用到的Redis为例,为公共数据部署一组Redis,包括一个Master和一个Slave。为资源数据部署两组Redis,每组内同样包括一个Master和一个Slave。这样通过6个Redis(Master/Slave)节点形成一个Redis集群服务方案。
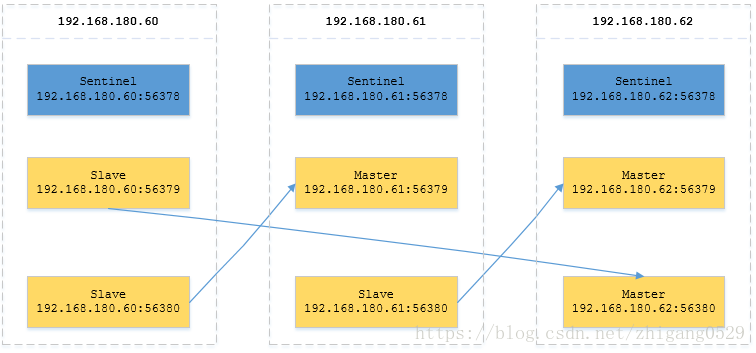
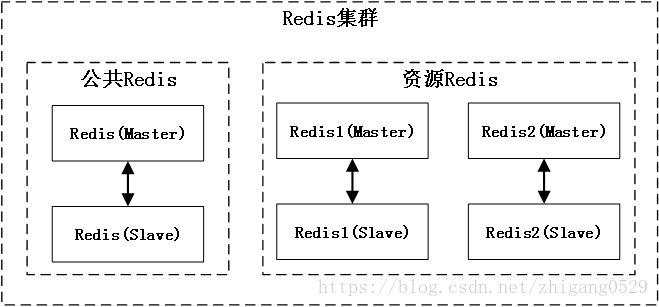 为了方便说明Redis集群,本次在三台服务器进行Redis集群的安装,其中每台服务器上各部署一个Master和Slave,考虑到防止设备宕机导致的高可用问题,不同服务器的Master和Slave形成Master/Slave关系。另外每台服务器上要各部署一个Sentinel,做为Redis的管理节点,实时监测Master和Slave的主备状态与切换, 如果Master所在的服务器宕机,Slave也能继续接替Master工作。
实际部署形成的Redis主备节点集群方案如下, Slave节点通过蓝色箭头指向Master节点做表示:
为了方便说明Redis集群,本次在三台服务器进行Redis集群的安装,其中每台服务器上各部署一个Master和Slave,考虑到防止设备宕机导致的高可用问题,不同服务器的Master和Slave形成Master/Slave关系。另外每台服务器上要各部署一个Sentinel,做为Redis的管理节点,实时监测Master和Slave的主备状态与切换, 如果Master所在的服务器宕机,Slave也能继续接替Master工作。
实际部署形成的Redis主备节点集群方案如下, Slave节点通过蓝色箭头指向Master节点做表示:
 3.3 实现方案
3.3.1 采用Java直接连接Redis节点取INFO信息
采用Java开发,在开发工程中引用开发包jedis-2.7.2.jar,进行代码开发。连接一个Redis节点的关键代码如下,例如连接一个IP是192.168.180.61,端口是56380的Redis节点:
Jedis jedis = new Jedis (“192.168.180.61”, 56380);
String info = jedis.info ();
如果这个IP和端口的Redis节点正常,则返回的info字符串,就可得到这个节点的所有信息,与在Redis服务器上通过INFO命令取节点信息是同样效果。
3.3.2采集Redis节点方法
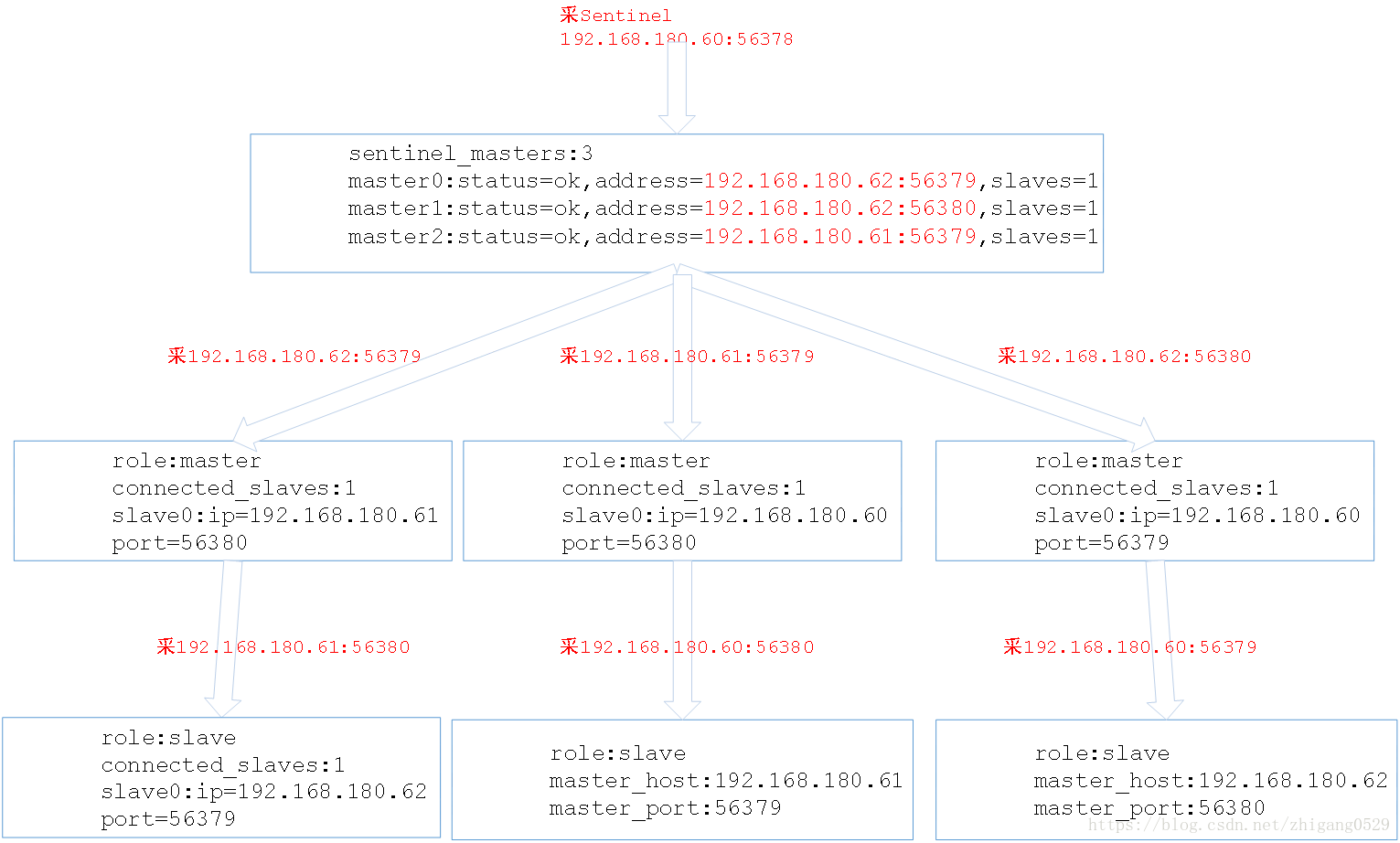
通过Sentinel节点采集,可采集Sentinel管理的Master节点信息。在确定了一个Sentinel节点的IP和端口的情况下,先采这个Sentinel节点的信息,可得到这个Sentinel管理的Master节点的IP和端口,有了多个Master节点的IP和端口,可再针对这些IP和端口进行采集。
例如采一个Sentinel节点,得到目前这个Sentinel管理的3个Master的IP和端口,再依次采用这3个Master的IP和端口的Redis信息,得到该Master的Slave节点信息。
如下图例展示了通过一个Sentinel可采到所有节点的过程:
3.3 实现方案
3.3.1 采用Java直接连接Redis节点取INFO信息
采用Java开发,在开发工程中引用开发包jedis-2.7.2.jar,进行代码开发。连接一个Redis节点的关键代码如下,例如连接一个IP是192.168.180.61,端口是56380的Redis节点:
Jedis jedis = new Jedis (“192.168.180.61”, 56380);
String info = jedis.info ();
如果这个IP和端口的Redis节点正常,则返回的info字符串,就可得到这个节点的所有信息,与在Redis服务器上通过INFO命令取节点信息是同样效果。
3.3.2采集Redis节点方法
通过Sentinel节点采集,可采集Sentinel管理的Master节点信息。在确定了一个Sentinel节点的IP和端口的情况下,先采这个Sentinel节点的信息,可得到这个Sentinel管理的Master节点的IP和端口,有了多个Master节点的IP和端口,可再针对这些IP和端口进行采集。
例如采一个Sentinel节点,得到目前这个Sentinel管理的3个Master的IP和端口,再依次采用这3个Master的IP和端口的Redis信息,得到该Master的Slave节点信息。
如下图例展示了通过一个Sentinel可采到所有节点的过程:
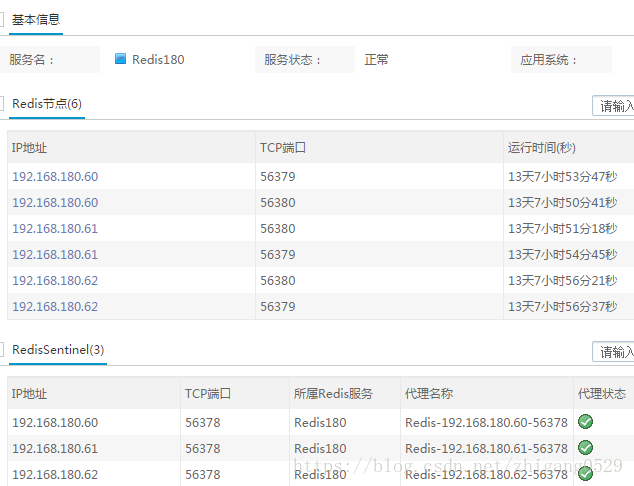
 这样至少通过一个Sentinel节点的IP和端口,就能把这个集群服务中的所有Master和Slave节点信息采集到,包括这个Sentinel节点本身。其它的Sentinel节点再分别通过IP和端口采集。
如下图展示是的当前这个名为Redis180的服务, 各个Redis节点的一个展示页面效果。
这样至少通过一个Sentinel节点的IP和端口,就能把这个集群服务中的所有Master和Slave节点信息采集到,包括这个Sentinel节点本身。其它的Sentinel节点再分别通过IP和端口采集。
如下图展示是的当前这个名为Redis180的服务, 各个Redis节点的一个展示页面效果。
 3.3.3从INFO字符串提取关键配置信息和性能指标
通过取一个Redis节点的INFO字符串信息中,是格式固定的字符串,通过提取关键指标值,将指标值进行分析处理,可做为Redis节点的资源配置信息或性能指标值。例如内存部分的字段信息:
used_memory: 4809536 #Redis使用的内存
used_memory_peak: 6589592 #Redis所用内存的高峰值
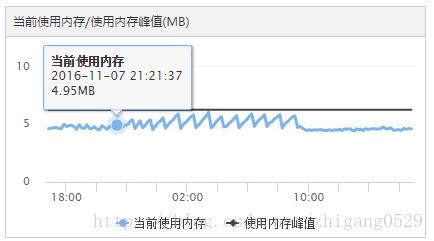
这两个指标给出的是当前这个Redis节点使用的内存量与高峰值的字节数。通过一个Redis节点的IP与端口,做为资源的唯一标识,把这两个指标数据归属到这个Redis资源上。数据在入库后,可通过界面查看这两个指标的展示情况:
3.3.3从INFO字符串提取关键配置信息和性能指标
通过取一个Redis节点的INFO字符串信息中,是格式固定的字符串,通过提取关键指标值,将指标值进行分析处理,可做为Redis节点的资源配置信息或性能指标值。例如内存部分的字段信息:
used_memory: 4809536 #Redis使用的内存
used_memory_peak: 6589592 #Redis所用内存的高峰值
这两个指标给出的是当前这个Redis节点使用的内存量与高峰值的字节数。通过一个Redis节点的IP与端口,做为资源的唯一标识,把这两个指标数据归属到这个Redis资源上。数据在入库后,可通过界面查看这两个指标的展示情况:
 3.3.4一个服务中通过Sentinel判断服务状态
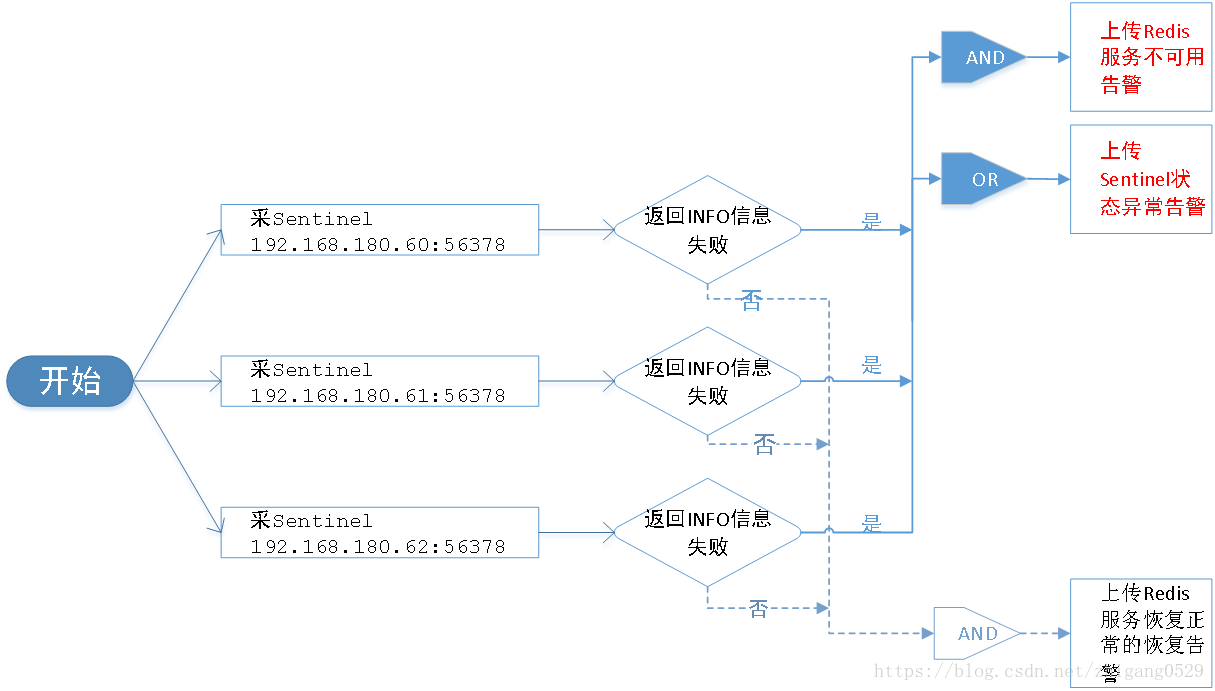
部署了多个Redis节点,包括多个Master,Slave,Sentinel节点成一个集群,通过Sentinel来管理各节点的运行状态。 Sentinel能够监控所管理的Master或Slave节点的运行状态和角色,所以可以通过Sentinel来判断一个Redis集群服务的运行状态。
判断一个集群服务方法:如果服务中所有的Sentinel节点无法取回INFO信息,则认为这个服务状态是异常的,并上报Redis服务不可用告警。
实现方法:
周期检查一个Redis服务中的所有Sentinel的IP和端口, 如果服务中的每个Sentinel的IP和端口都不能返回INFO信息,则认为这个服务异常不可用,并上传Redis服务状态异常不可用的告警。
2. 如果是单个Sentinel节点不能返回INFO信息,则上传这个Sentinel节点状态异常告警。
3. 当检查到所有Sentinel节点的IP和端口都可采,都能返回INFO信息,是认为Redis服务已正常,上传Redis服务恢复正常的恢复告警。
3.3.4一个服务中通过Sentinel判断服务状态
部署了多个Redis节点,包括多个Master,Slave,Sentinel节点成一个集群,通过Sentinel来管理各节点的运行状态。 Sentinel能够监控所管理的Master或Slave节点的运行状态和角色,所以可以通过Sentinel来判断一个Redis集群服务的运行状态。
判断一个集群服务方法:如果服务中所有的Sentinel节点无法取回INFO信息,则认为这个服务状态是异常的,并上报Redis服务不可用告警。
实现方法:
周期检查一个Redis服务中的所有Sentinel的IP和端口, 如果服务中的每个Sentinel的IP和端口都不能返回INFO信息,则认为这个服务异常不可用,并上传Redis服务状态异常不可用的告警。
2. 如果是单个Sentinel节点不能返回INFO信息,则上传这个Sentinel节点状态异常告警。
3. 当检查到所有Sentinel节点的IP和端口都可采,都能返回INFO信息,是认为Redis服务已正常,上传Redis服务恢复正常的恢复告警。
 4.本方案相对于现有方案的有益效果或者优点
实现了一种可视化的实时监控Redis集群中节点信息和服务运行状态的监控方法。
通过一个Sentinel节点就能一次性采集发现这个Sentinel管理的所有Redis节点信息。
为一组部署了Sentinel节点的Redis集群确定了一种通过多个Sentinel判断集群服务是否正常的方法。
4.本方案相对于现有方案的有益效果或者优点
实现了一种可视化的实时监控Redis集群中节点信息和服务运行状态的监控方法。
通过一个Sentinel节点就能一次性采集发现这个Sentinel管理的所有Redis节点信息。
为一组部署了Sentinel节点的Redis集群确定了一种通过多个Sentinel判断集群服务是否正常的方法。
(责任编辑:IT)
1. 技术领域
提供一种Redis集群中各Redis节点的监控处理方法,能够采集Redis节点的资源信息、性能指标数据,集群内多个Redis节点服务运行状态监控。实现告警监控信息、资源和性能指标的采集与分析的监控方法。
2. 背景技术
2.1 Redis简介
Redis 是一种开源的内存中key-value数据结构存储系统,它可以用作数据库、缓存和消息中间件。它支持多种类型的数据结构,如字符串(strings), 散列(hashes), 列表(lists), 集合(sets),有序集合(sorted sets)与范围查询。Redis也可以被看成是一个数据结构服务器。Redis的所有数据都是保存在内存中,然后不定期的通过异步方式保存到磁盘上。
Redis可使用一个或多个Redis哨兵(Sentinel),和Redis的主节点(Master)、 多个从节点(Slave)组成一个集群。Sentinel来检测Redis的Master节点是否运行正常,并在Master节点发生故障时,将 Master的Slave提升为Master,并在老的Master重新加入到Sentinel的群集之后,会被重新配置,作为新Master的Slave。基于Redis的 Sentinel可实现集群的高可用管理功能。
2.2 Redis监控方法
Redis 监控最直接的方法就是在装有Redis的服务器上使用Redis服务提供的 INFO 命令,只需要执行下面一条命令:
./redis-cli -p 端口号info
会返回一个Redis节点的Server、Clients、Memory、Persistence、Stats、Replication、CPU、Keyspace 8个部分的结果信息。从INFO返回结果中得到相关信息,就可以达到监控一个Redis节点的目的。
如下结果返回的是一个Redis的Master节点的信息:
# Server
redis_version:2.8.8 # Redis 的版本
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:bf5d1747be5380f
redis_mode:standalone
os:Linux 2.6.32-220.7.1.el6.x86_64 x86_64
arch_bits:64
gcc_version:4.4.7 #gcc版本
process_id:49324 # 当前 Redis 服务器进程id
run_id:bbd7b17efcf108fdde285d8987e50392f6a38f48
tcp_port:6379
uptime_in_seconds:1739082 # 运行时间(秒)
uptime_in_days:20 # 运行时间(天)
# Clients
connected_clients:1 #连接的客户端数量
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0
# Memory
used_memory:821848 #Redis分配的内存总量
used_memory_human:802.59K
used_memory_rss:85532672 #Redis分配的内存总量(包括内存碎片)
used_memory_peak:178987632
used_memory_peak_human:170.70M #Redis所用内存的高峰值
used_memory_lua:33792
mem_fragmentation_ratio:104.07 #内存碎片比率
mem_allocator:tcmalloc-2.0
# Persistence
loading:0
rdb_changes_since_last_save:0 #上次保存数据库之后,执行命令的次数
rdb_bgsave_in_progress:0 #后台进行中的 save 操作的数量
rdb_last_save_time:1410848500 #最后一次成功保存时间点
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
# Stats
total_connections_received:5705 #运行以来连接过的客户端的总数量
total_commands_processed:204013 #运行以来执行过的命令的总数量
instantaneous_ops_per_sec:0
rejected_connections:0
expired_keys:34401 #运行以来过期的 key 的数量
evicted_keys:0 #运行以来删除过的key的数量
keyspace_hits:2129 #命中key 的次数
keyspace_misses:3148 #没命中key 的次数
# Replication
role:master #当前实例的角色master还是slave
connected_slaves:0
master_repl_offset:0
# CPU
used_cpu_sys:1551.61
used_cpu_user:1083.37
used_cpu_sys_children:2.52
used_cpu_user_children:16.79
# Keyspace
db0:keys=3,expires=0,avg_ttl=0 #各个数据库key 的数量,以及带有生存期的 key 的数量
以上字符串就是这个Redis节点带有固定格式的一些字段属性和值。
同样通过INFO命令,对一个Sentinel节点返回的信息如下:
# Sentinel
sentinel_masters:3
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
master0:name=common, status=ok,address=192.168.95.111:56379,slaves=1,sentinels=3
master1:name=resource1,status=ok,address=192.168.95.112:56379,slaves=1,sentinels=3
master2:name=resource2,status=ok,address=192.168.95.113:56379,slaves=1,sentinels=3
由返回信息可得知这个Sentinel目前管理了3个Master,并分别给出了Master的IP和端口,每个Master各有一个Slave。
3.技术方案描述
3.1 要解决的技术问题
通过在Redis服务器上执行INFO命令可以得到当前Redis节点的结果信息,但需要手工执行命令,结果信息可读性不强,不直观,不能达到自动监控的目的。 理想监控方案是在公司目前的监控产品中,集成Redis的集群监控方案,能够周期性、不间断的自动采集Redis各节点的数据信息,实时上报Redis节点的监控指标和状态,和Redis集群的服务状态信息。
3.2 整体思路
Redis的Sentinel作为Redis的高可用方案,可以实现Redis的Mater和Slave之间高可用和故障自动切换。以公司某监控产品环境中的用到的Redis为例,为公共数据部署一组Redis,包括一个Master和一个Slave。为资源数据部署两组Redis,每组内同样包括一个Master和一个Slave。这样通过6个Redis(Master/Slave)节点形成一个Redis集群服务方案。
为了方便说明Redis集群,本次在三台服务器进行Redis集群的安装,其中每台服务器上各部署一个Master和Slave,考虑到防止设备宕机导致的高可用问题,不同服务器的Master和Slave形成Master/Slave关系。另外每台服务器上要各部署一个Sentinel,做为Redis的管理节点,实时监测Master和Slave的主备状态与切换, 如果Master所在的服务器宕机,Slave也能继续接替Master工作。
实际部署形成的Redis主备节点集群方案如下, Slave节点通过蓝色箭头指向Master节点做表示:
3.3 实现方案
3.3.1 采用Java直接连接Redis节点取INFO信息
采用Java开发,在开发工程中引用开发包jedis-2.7.2.jar,进行代码开发。连接一个Redis节点的关键代码如下,例如连接一个IP是192.168.180.61,端口是56380的Redis节点:
Jedis jedis = new Jedis (“192.168.180.61”, 56380);
String info = jedis.info ();
如果这个IP和端口的Redis节点正常,则返回的info字符串,就可得到这个节点的所有信息,与在Redis服务器上通过INFO命令取节点信息是同样效果。
3.3.2采集Redis节点方法
通过Sentinel节点采集,可采集Sentinel管理的Master节点信息。在确定了一个Sentinel节点的IP和端口的情况下,先采这个Sentinel节点的信息,可得到这个Sentinel管理的Master节点的IP和端口,有了多个Master节点的IP和端口,可再针对这些IP和端口进行采集。
例如采一个Sentinel节点,得到目前这个Sentinel管理的3个Master的IP和端口,再依次采用这3个Master的IP和端口的Redis信息,得到该Master的Slave节点信息。
如下图例展示了通过一个Sentinel可采到所有节点的过程:
这样至少通过一个Sentinel节点的IP和端口,就能把这个集群服务中的所有Master和Slave节点信息采集到,包括这个Sentinel节点本身。其它的Sentinel节点再分别通过IP和端口采集。
如下图展示是的当前这个名为Redis180的服务, 各个Redis节点的一个展示页面效果。
3.3.3从INFO字符串提取关键配置信息和性能指标
通过取一个Redis节点的INFO字符串信息中,是格式固定的字符串,通过提取关键指标值,将指标值进行分析处理,可做为Redis节点的资源配置信息或性能指标值。例如内存部分的字段信息:
used_memory: 4809536 #Redis使用的内存
used_memory_peak: 6589592 #Redis所用内存的高峰值
这两个指标给出的是当前这个Redis节点使用的内存量与高峰值的字节数。通过一个Redis节点的IP与端口,做为资源的唯一标识,把这两个指标数据归属到这个Redis资源上。数据在入库后,可通过界面查看这两个指标的展示情况:
3.3.4一个服务中通过Sentinel判断服务状态
部署了多个Redis节点,包括多个Master,Slave,Sentinel节点成一个集群,通过Sentinel来管理各节点的运行状态。 Sentinel能够监控所管理的Master或Slave节点的运行状态和角色,所以可以通过Sentinel来判断一个Redis集群服务的运行状态。
判断一个集群服务方法:如果服务中所有的Sentinel节点无法取回INFO信息,则认为这个服务状态是异常的,并上报Redis服务不可用告警。
实现方法:
周期检查一个Redis服务中的所有Sentinel的IP和端口, 如果服务中的每个Sentinel的IP和端口都不能返回INFO信息,则认为这个服务异常不可用,并上传Redis服务状态异常不可用的告警。
2. 如果是单个Sentinel节点不能返回INFO信息,则上传这个Sentinel节点状态异常告警。
3. 当检查到所有Sentinel节点的IP和端口都可采,都能返回INFO信息,是认为Redis服务已正常,上传Redis服务恢复正常的恢复告警。
4.本方案相对于现有方案的有益效果或者优点
实现了一种可视化的实时监控Redis集群中节点信息和服务运行状态的监控方法。
通过一个Sentinel节点就能一次性采集发现这个Sentinel管理的所有Redis节点信息。
为一组部署了Sentinel节点的Redis集群确定了一种通过多个Sentinel判断集群服务是否正常的方法。
(责任编辑:IT) |