集群安装完毕,该如何测试和使用集群-hadoop单机(伪分布)
时间:2014-10-25 14:25 来源:linux.it.net.cn 作者:it
集群安装完毕,该如何测试和使用集群:
运行hadoop首先进入hadoop所在目录,第一次执行要格式化文件系统bin/hadoop namenode –format
启动bin/start-all.sh
用jps命令查看进程,显示:
root@ubuntu:/usr/hadoop/hadoop-1# jps
6449 DataNode
6998 TaskTracker
33851 Jps
6200 NameNode
6765 JobTracker
6683 SecondaryNameNode
少一个都不对
还有就是使用web接口访问
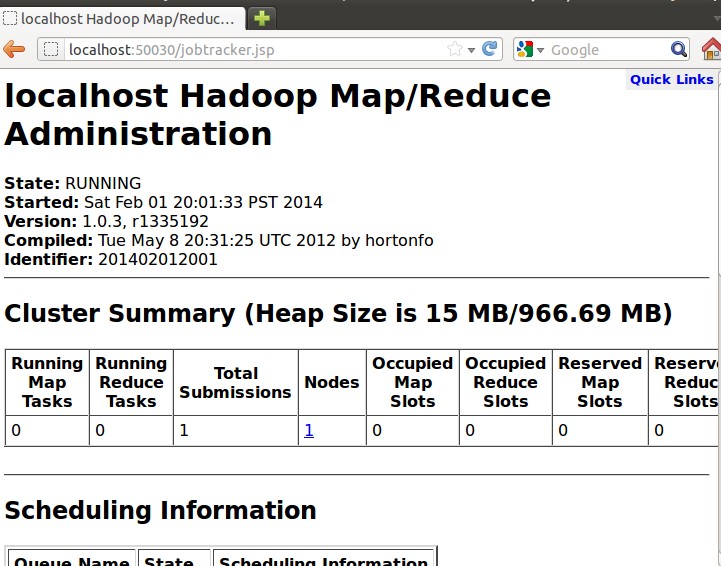
http://localhost:50030
可以查看JobTracker的运行状态
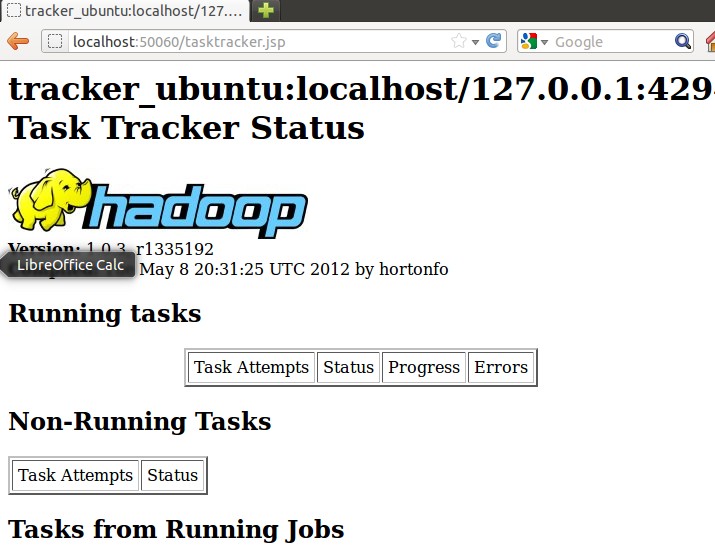
http://localhost:50060
可以查看TaskTracker的运行状态
http://localhost:50070
可以查看NameNode以及整个分布式文件系统的状态,浏览分布式文件系统中的文件以及log等。

运行测试实例wordcount
注意:1.注意wordcount大小写,这里都是小写
2.复制命令可能会出现命令不识别,尽量手写
copyFromLocal: Unknown command
Usage: java FsShell
[-ls <path>]
.......
[-help [cmd]]
这里使用附带jar包里的wordcount
(1)先在本地磁盘建立两个输入文件file01 和 file02:
$ echo "Hello World Bye World" > file01
$ echo "Hello Hadoop Goodbye Hadoop" > file02
(2)在hdfs 中建立一个input目录:
$ hadoop fs –mkdir input
(3)将file01 和 file02 拷贝到hdfs中:
$ hadoop fs –copyFromLocal file0* input
(4)执行wordcount:
$ hadoop jar hadoop-examples-1.2.0.jar wordcount input output
(5)完成之后,查看结果:
$ bin/hadoop fs -ls . 查看已有的文件列表
$ hadoop fs -cat output/part-r-00000 查看结果
结果为:可见把单词都统计了
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
(责任编辑:IT)
| 集群安装完毕,该如何测试和使用集群: 运行hadoop首先进入hadoop所在目录,第一次执行要格式化文件系统bin/hadoop namenode –format 启动bin/start-all.sh 用jps命令查看进程,显示: root@ubuntu:/usr/hadoop/hadoop-1# jps 6449 DataNode 6998 TaskTracker 33851 Jps 6200 NameNode 6765 JobTracker 6683 SecondaryNameNode 少一个都不对 还有就是使用web接口访问 http://localhost:50030 可以查看JobTracker的运行状态 http://localhost:50060 可以查看TaskTracker的运行状态 http://localhost:50070 可以查看NameNode以及整个分布式文件系统的状态,浏览分布式文件系统中的文件以及log等。 运行测试实例wordcount 注意:1.注意wordcount大小写,这里都是小写 2.复制命令可能会出现命令不识别,尽量手写 copyFromLocal: Unknown command Usage: java FsShell [-ls <path>] ....... [-help [cmd]] 这里使用附带jar包里的wordcount (1)先在本地磁盘建立两个输入文件file01 和 file02: $ echo "Hello World Bye World" > file01 $ echo "Hello Hadoop Goodbye Hadoop" > file02 (2)在hdfs 中建立一个input目录: $ hadoop fs –mkdir input (3)将file01 和 file02 拷贝到hdfs中: $ hadoop fs –copyFromLocal file0* input (4)执行wordcount: $ hadoop jar hadoop-examples-1.2.0.jar wordcount input output (5)完成之后,查看结果: $ bin/hadoop fs -ls . 查看已有的文件列表 $ hadoop fs -cat output/part-r-00000 查看结果 结果为:可见把单词都统计了 Bye 1 Goodbye 1 Hadoop 2 Hello 2 World 2 (责任编辑:IT) |