HadoopМЏШКЃЈЕк7ЦкЃЉ_EclipseПЊЗЂЛЗОГЩшжУ
ЪБМф:2014-11-02 11:46 РДдД:linux.it.net.cn зїеп:it
1ЁЂHadoopПЊЗЂЛЗОГМђНщ
1.1 HadoopМЏШКМђНщ
ЁЁЁЁJavaАцБОЃКjdk-6u31-linux-i586.bin
ЁЁЁЁLinuxЯЕЭГЃКCentOS6.0
ЁЁЁЁHadoopАцБОЃКhadoop-1.0.0.tar.gz
1.2 WindowsПЊЗЂМђНщ
ЁЁЁЁJavaАцБОЃКjdk-6u31-windows-i586.exe
ЁЁЁЁWinЯЕЭГЃКWindows 7 ЦьНЂАц
ЁЁЁЁEclipseШэМўЃКeclipse-jee-indigo-SR1-win32.zip | eclipse-jee-helios-SR2-win32.zip
ЁЁЁЁHadoopШэМўЃКhadoop-1.0.0.tar.gz
ЁЁЁЁHadoop Eclipse ВхМўЃКhadoop-eclipse-plugin-1.0.0.jar
ЁЁЁЁЯТдиЕижЗЃКhttp://download.csdn.net/detail/xia520pi/4113746
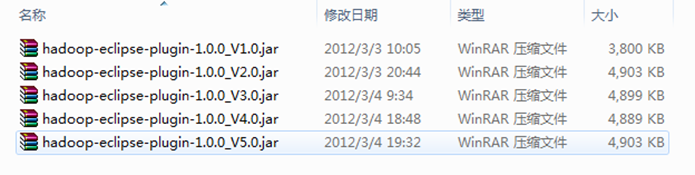
ЁЁЁЁБИзЂЃКЯТУцЪЧЭјЩЯЪеМЏЕФЪеМЏЕФ"hadoop-eclipse-plugin-1.0.0.jar"ЃЌГ§"АцБО2.0"ЪЧИљОн"V1.0"АДее"ГЃМћЮЪЬтFAQ_1"ИФЕФжЎЭтЃЌЪЃгрЕФ"V3.0"ЁЂ"V4.0"КЭ"V5.0"КЭ"V2.0"вЛбљЪЧБ№ШЫвбОХЊКУЕФЃЌЖјЧвЮввбОЖМВтЪдЙ§ЃЌУЛгаШЮКЮЮЪЬтЃЌПЩвдЗХаФЪЙгУЁЃЮвУЧетРябЁдёЕк"V5.0"ЪЙгУЁЃМЧЕУдкЪЙгУЪБжиаТУќУћЮЊ"hadoop-eclipse-plugin-1.0.0.jar"ЁЃ
2ЁЂHadoop EclipseМђНщКЭЪЙгУ
2.1 EclipseВхМўНщЩм
ЁЁЁЁHadoopЪЧвЛИіЧПДѓЕФВЂааПђМмЃЌЫќдЪаэШЮЮёдкЦфЗжВМЪНМЏШКЩЯВЂааДІРэЁЃЕЋЪЧБраДЁЂЕїЪдHadoopГЬађЖМгаКмДѓФбЖШЁЃе§вђЮЊШчДЫЃЌHadoopЕФПЊЗЂепПЊЗЂГіСЫHadoop EclipseВхМўЃЌЫќдкHadoopЕФПЊЗЂЛЗОГжаЧЖШыСЫEclipseЃЌДгЖјЪЕЯжСЫПЊЗЂЛЗОГЕФЭМаЮЛЏЃЌНЕЕЭСЫБрГЬФбЖШЁЃдкАВзАВхМўЃЌХфжУHadoopЕФЯрЙиаХЯЂжЎКѓЃЌШчЙћгУЛЇДДНЈHadoopГЬађЃЌВхМўЛсздЖЏЕМШыHadoopБрГЬНгПкЕФJARЮФМўЃЌетбљгУЛЇОЭПЩвддкEclipseЕФЭМаЮЛЏНчУцжаБраДЁЂЕїЪдЁЂдЫааHadoopГЬађЃЈАќРЈЕЅЛњГЬађКЭЗжВМЪНГЬађЃЉЃЌвВПЩвддкЦфжаВщПДздМКГЬађЕФЪЕЪБзДЬЌЁЂДэЮѓаХЯЂКЭдЫааНсЙћЃЌЛЙПЩвдВщПДЁЂЙмРэHDFSвдМАЮФМўЁЃзмЕиРДЫЕЃЌHadoop EclipseВхМўАВзАМђЕЅЃЌЪЙгУЗНБуЃЌЙІФмЧПДѓЃЌгШЦфЪЧдкHadoopБрГЬЗНУцЃЌЪЧHadoopШыУХКЭHadoopБрГЬБиВЛПЩЩйЕФЙЄОпЁЃ
2.2 HadoopЙЄзїФПТММђНщ
ЁЁЁЁЮЊСЫвдКѓЗНБуПЊЗЂЃЌЮвУЧАДееЯТУцАбПЊЗЂжагУЕНЕФШэМўАВзАдкДЫФПТМжаЃЌJDKАВзАГ§ЭтЃЌЮветРяАбJDKАВзАдкCХЬЕФФЌШЯАВзАТЗОЖЯТЃЌЯТУцЪЧЮвЕФЙЄзїФПТМЃК
ЯЕЭГДХХЬЃЈEЃКЃЉ
|---HadoopWorkPlat
|--- eclipse
|--- hadoop-1.0.0
|--- workplace
|---……
ЁЁЁЁАДееЩЯУцФПТМАбEclipseКЭHadoopНтбЙЕН"E:\HadoopWorkPlat"ЯТУцЃЌВЂДДНЈ"workplace"зїЮЊEclipseЕФЙЄзїПеМфЁЃ
ЁЁЁЁБИзЂЃКДѓМвПЩвдАДеездМКЕФЧщПіЃЌВЛвЛЖЈАДееЮвЕФНсЙЙРДЩшМЦЁЃ
2.3 аоИФЯЕЭГЙмРэдБУћзж
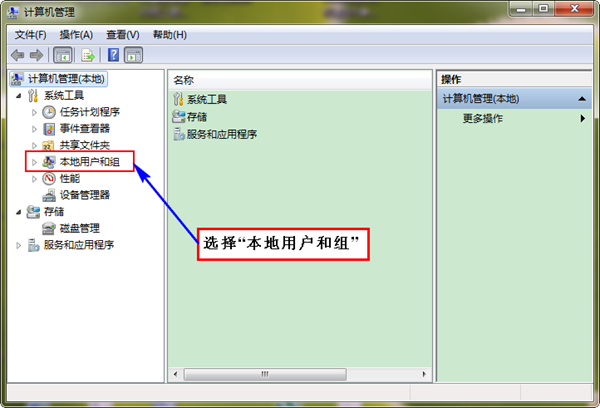
ЁЁЁЁОЙ§СНЬьЖрДЮЬНЫїЃЌЮЊСЫЪЙEclipseФме§ГЃЖдHadoopМЏШКЕФHDFSЩЯЕФЮФМўФмНјаааоИФКЭЩОГ§ЃЌЫљвдаоИФФуЙЄзїЪБЫљгУЕФWin7ЯЕЭГЙмРэдБУћзжЃЌФЌШЯвЛАуЮЊ"Administrator"ЃЌАбЫќаоИФЮЊ"hadoop"ЃЌДЫгУЛЇУћгыHadoopМЏШКЦеЭЈгУЛЇвЛжТЃЌДѓМвгІИУМЧЕУЮвУЧHadoopМЏШКжаЫљгаЕФЛњЦїЖМгавЛИіЦеЭЈгУЛЇ——hadoopЃЌЖјЧвHadoopдЫаавВЪЧгУетИігУЛЇНјааЕФЁЃЮЊСЫВЛжСгкЮЊШЈЯоПрФеЃЌЮвУЧПЩвдаоИФWin7ЩЯЯЕЭГЙмРэдБЕФаеУћЃЌетбљОЭБмУтГіЯжИУгУЛЇдкHadoopМЏШКЩЯУЛгаШЈЯоЕШЖМЬлЮЪЬтЃЌЛсЕМжТдкEclipseжаЖдHadoopМЏШКЕФHDFSДДНЈКЭЩОГ§ЮФМўЪмгАЯьЁЃ
ЁЁЁЁФуПЩвдзівЛЯТЪЕбщЃЌВщПДMaster.HadoopЛњЦїЩЯ"/usr/hadoop/logs"ЯТУцЕФШежОЁЃЗЂЯжШЈЯоВЛЙЛЃЌВЛФмНјаа"Write"ВйзїЃЌЭјЩЯгаМИжжНтОіЗНАИЃЌЕЋЪЧЖдHadoop1.0ВЛЦ№зїгУЃЌЯъЧщМћ"ГЃМћЮЪЬтFAQ_2"ЁЃЯТУцЮвУЧНјаааоИФЙмРэдБУћзжЁЃ
ЁЁЁЁЪзЯШ"гвЛї"зРУцЩЯЭМБъ"ЮвЕФЕчФд"ЃЌбЁдё"ЙмРэ"ЃЌЕЏГіНчУцШчЯТЃК
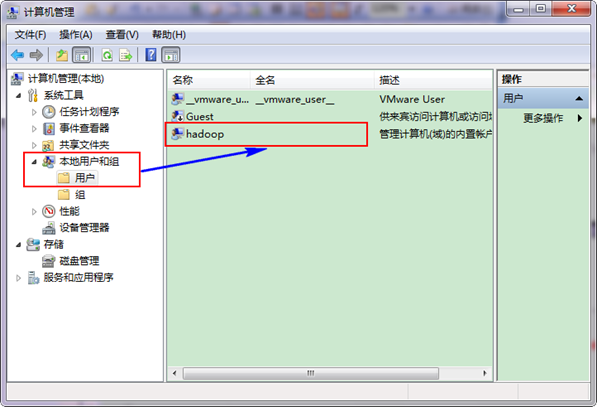
ЁЁЁЁНгзХбЁдё"БОЕигУЛЇКЭзщ"ЃЌеЙПЊ"гУЛЇ"ЃЌевЕНЯЕЭГЙмРэдБ"Administrator"ЃЌаоИФЦфЮЊ"hadoop"ЃЌВйзїНсЙћШчЯТЭМЃК
ЁЁЁЁзюКѓЃЌАбЕчФдНјаа"зЂЯњ"Лђеп"жиЦєЕчФд"ЃЌетбљВХФмЪЙЙмРэдБВХФмгУетИіУћзжЁЃ
2.4 EclipseВхМўПЊЗЂХфжУ
ЁЁЁЁЕквЛВНЃКАбЮвУЧЕФ"hadoop-eclipse-plugin-1.0.0.jar"ЗХЕНEclipseЕФФПТМЕФ"plugins"жаЃЌШЛКѓжиаТEclipseМДПЩЩњаЇЁЃ
ЯЕЭГДХХЬЃЈEЃКЃЉ
|---HadoopWorkPlat
|--- eclipse
|--- plugins
|--- hadoop-eclipse-plugin-1.0.0.jar
ЁЁЁЁЩЯУцЪЧЮвЕФ"hadoop-eclipse-plugin"ВхМўЗХжУЕФЕиЗНЁЃжиЦєEclipseШчЯТЭМЃК
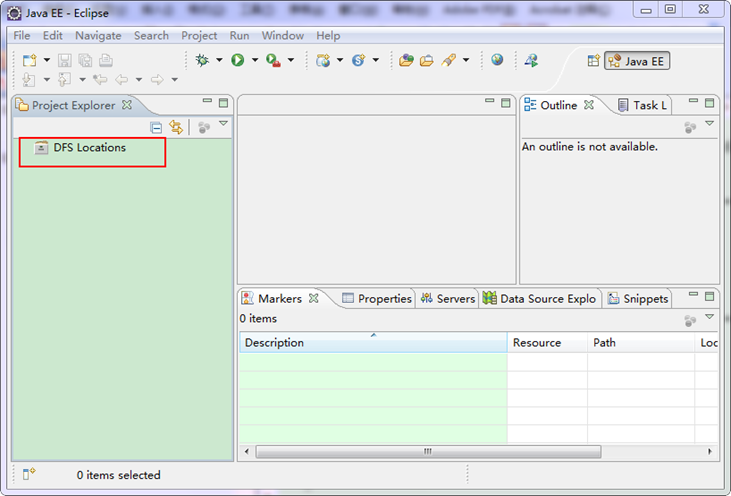
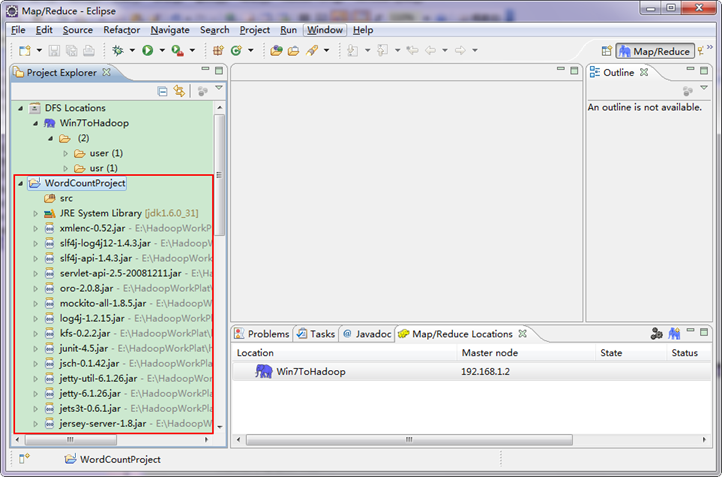
ЁЁЁЁЯИаФЕФФуДгЩЯЭМжазѓВр"Project Explorer"ЯТУцЗЂЯж"DFS Locations"ЃЌЫЕУїEclipseвбОЪЖБ№ИеВХЗХШыЕФHadoop EclipseВхМўСЫЁЃ
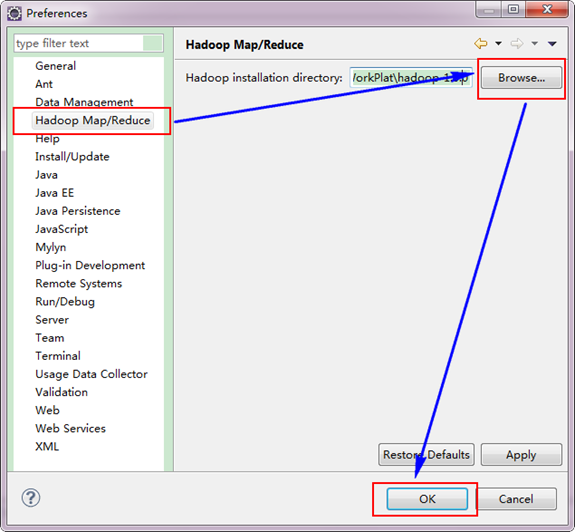
ЁЁЁЁЕкЖўВНЃКбЁдё"Window"ВЫЕЅЯТЕФ"Preference"ЃЌШЛКѓЕЏГівЛИіДАЬхЃЌдкДАЬхЕФзѓВрЃЌгавЛСабЁЯюЃЌРяУцЛсЖрГі"Hadoop Map/Reduce"бЁЯюЃЌЕуЛїДЫбЁЯюЃЌбЁдёHadoopЕФАВзАФПТМЃЈШчЮвЕФHadoopФПТМЃКE:\HadoopWorkPlat\hadoop-1.0.0ЃЉЁЃНсЙћШчЯТЭМЃК
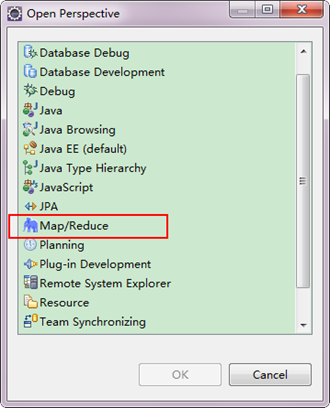
ЁЁЁЁЕкШ§ВНЃКЧаЛЛ"Map/Reduce"ЙЄзїФПТМЃЌгаСНжжЗНЗЈЃК
ЁЁЁЁ1ЃЉбЁдё"Window"ВЫЕЅЯТбЁдё"Open Perspective"ЃЌЕЏГівЛИіДАЬхЃЌДгжабЁдё"Map/Reduce"бЁЯюМДПЩНјааЧаЛЛЁЃ
ЁЁЁЁ2ЃЉдкEclipseШэМўЕФгвЩЯНЧЃЌЕуЛїЭМБъ" "жаЕФ"
"жаЕФ" "ЃЌЕуЛї"Other"бЁЯюЃЌвВПЩвдЕЏГіЩЯЭМЃЌДгжабЁдё"Map/Reduce"ЃЌШЛКѓЕуЛї"OK"МДПЩШЗЖЈЁЃ
"ЃЌЕуЛї"Other"бЁЯюЃЌвВПЩвдЕЏГіЩЯЭМЃЌДгжабЁдё"Map/Reduce"ЃЌШЛКѓЕуЛї"OK"МДПЩШЗЖЈЁЃ
ЁЁЁЁЧаЛЛЕН"Map/Reduce"ЙЄзїФПТМЯТЕФНчУцШчЯТЭМЫљЪОЁЃ
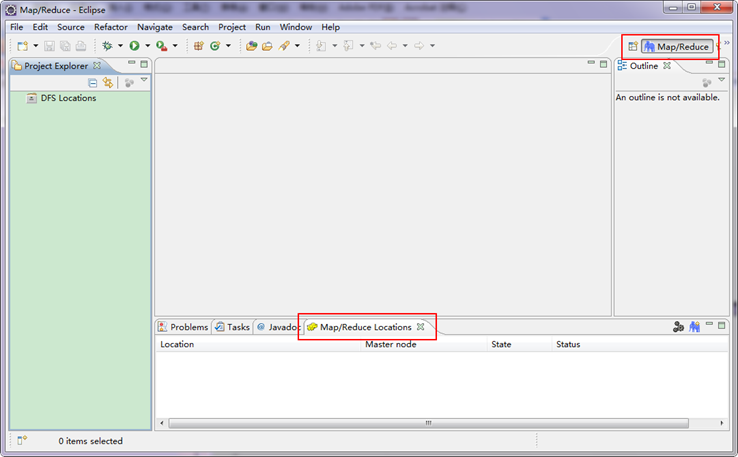
ЁЁЁЁЕкЫФВНЃКНЈСЂгыHadoopМЏШКЕФСЌНгЃЌдкEclipseШэМўЯТУцЕФ"Map/Reduce Locations"НјаагвЛїЃЌЕЏГівЛИібЁЯюЃЌбЁдё"New Hadoop Location"ЃЌШЛКѓЕЏГівЛИіДАЬхЁЃ

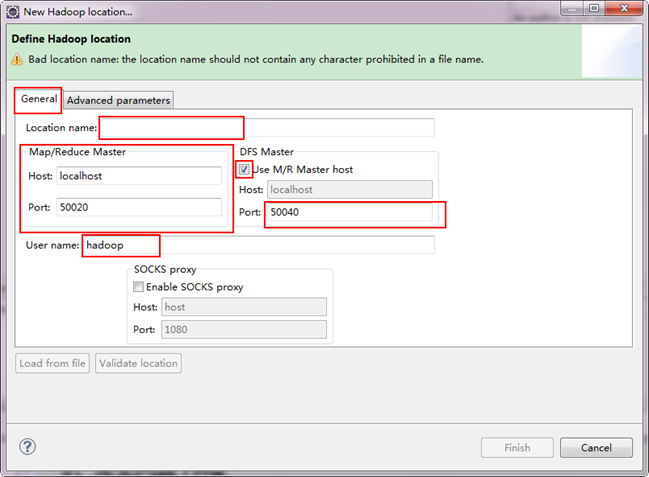
ЁЁЁЁзЂвтЩЯЭМжаЕФКьЩЋБъзЂЕФЕиЗНЃЌЪЧашвЊЮвУЧЙизЂЕФЕиЗНЁЃ
-
Location NameЃКПЩвдШЮвтЦфЃЌБъЪЖвЛИі"Map/Reduce Location"
-
Map/Reduce Master
HostЃК192.168.1.2ЃЈMaster.HadoopЕФIPЕижЗЃЉ
PortЃК9001
-
DFS Master
Use M/R Master hostЃКЧАУцЕФЙДЩЯЁЃЃЈвђЮЊЮвУЧЕФNameNodeКЭJobTrackerЖМдквЛИіЛњЦїЩЯЁЃЃЉ
PortЃК9000
-
User nameЃКhadoopЃЈФЌШЯЮЊWinЯЕЭГЙмРэдБУћзжЃЌвђЮЊЮвУЧжЎЧАИФСЫЫљвдетРяОЭБфГЩСЫhadoopЁЃЃЉ
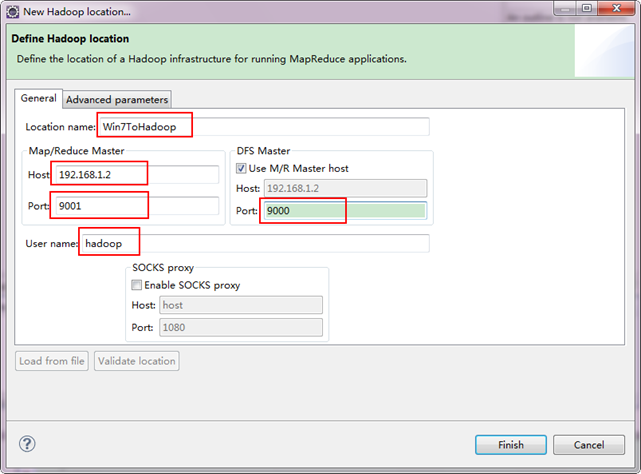
ЁЁЁЁБИзЂЃКетРяУцЕФHostЁЂPortЗжБ№ЮЊФудкmapred-site.xmlЁЂcore-site.xmlжаХфжУЕФЕижЗМАЖЫПкЁЃВЛЧхГўЕФПЩвдВЮПМ"HadoopМЏШК_Ек5Цк_HadoopАВзАХфжУ_V1.0"НјааВщПДЁЃ
ЁЁЁЁНгзХЕуЛї"Advanced parameters"ДгжаевМћ"hadoop.tmp.dir"ЃЌаоИФГЩЮЊЮвУЧHadoopМЏШКжаЩшжУЕФЕижЗЃЌЮвУЧЕФHadoopМЏШКЪЧ"/usr/hadoop/tmp"ЃЌетИіВЮЪ§дк"core-site.xml"НјааСЫХфжУЁЃ
ЁЁЁЁЕуЛї"finish"жЎКѓЃЌЛсЗЂЯжEclipseШэМўЯТУцЕФ"Map/Reduce Locations"ГіЯжвЛЬѕаХЯЂЃЌОЭЪЧЮвУЧИеВХНЈСЂЕФ"Map/Reduce Location"ЁЃ

ЁЁЁЁЕкЮхВНЃКВщПДHDFSЮФМўЯЕЭГЃЌВЂГЂЪдНЈСЂЮФМўМаКЭЩЯДЋЮФМўЁЃЕуЛїEclipseШэМўзѓВрЕФ"DFS Locations"ЯТУцЕФ"Win7ToHadoop"ЃЌОЭЛсеЙЪОГіHDFSЩЯЕФЮФМўНсЙЙЁЃ
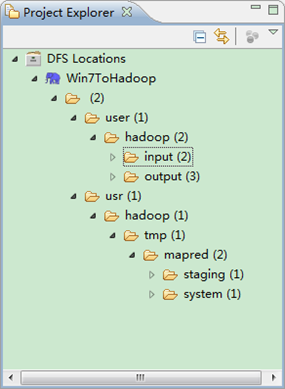
ЁЁЁЁгвЛї"Win7ToHadoopàuseràhadoop"ПЩвдГЂЪдНЈСЂвЛИі"ЮФМўМа--xiapi"ЃЌШЛКѓгвЛїЫЂаТОЭФмВщПДЮвУЧИеВХНЈСЂЕФЮФМўМаЁЃ
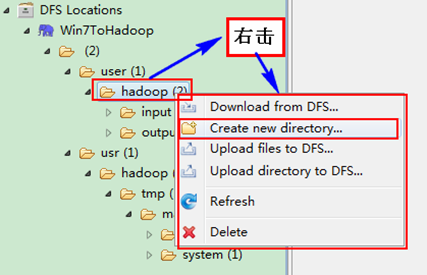
ЁЁЁЁДДНЈЭъжЎКѓЃЌВЂЫЂаТЃЌЯдЪОНсЙћШчЯТЃК
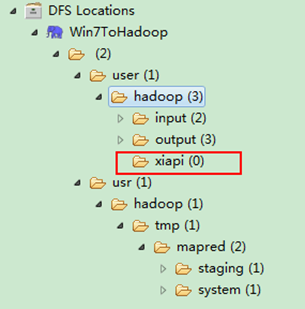
ЁЁЁЁгУSecureCRTдЖГЬЕЧТМ"Master.Hadoop"ЗўЮёЦїЃЌгУЯТУцУќСюВщПДЪЧЗёвбОНЈСЂвЛИі"xiapi"ЕФЮФМўМаЁЃ
hadoop fs -ls

ЁЁЁЁЕНДЫЮЊжЙЃЌЮвУЧЕФHadoop EclipseПЊЗЂЛЗОГвбОХфжУЭъБЯЃЌВЛОЁаЫЕФЭЌбЇПЩвдЩЯДЋЕуБОЕиЮФМўЕНHDFSЗжВМЪНЮФМўЩЯЃЌПЩвдЛЅЯрЖдБШвтМћЮФМўЪЧЗёвбОЩЯДЋГЩЙІЁЃ
3ЁЂEclipseдЫааWordCountГЬађ
3.1 ХфжУEclipseЕФJDK
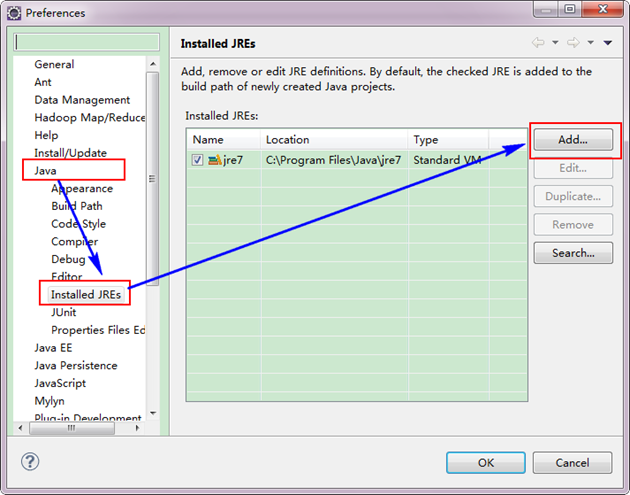
ЁЁЁЁШчЙћЕчФдЩЯВЛНіНіАВзАЕФJDK6.0ЃЌФЧУДвЊШЗЖЈвЛЯТEclipseЕФЦНЬЈЕФФЌШЯJDKЪЧЗё6.0ЁЃДг"Window"ВЫЕЅЯТбЁдё"Preference"ЃЌЕЏГівЛИіДАЬхЃЌДгДАЬхЕФзѓВревМћ"Java"ЃЌбЁдё"Installed JREs"ЃЌШЛКѓЬэМгJDK6.0ЁЃЯТУцЪЧЮвЕФФЌШЯбЁдёJREЁЃ
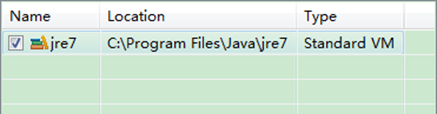
ЁЁЁЁЯТУцЪЧУЛгаЬэМгжЎЧАЕФЩшжУШчЯТЃК
ЁЁЁЁЯТУцЪЧЬэМгЭъJDK6.0жЎКѓНсЙћШчЯТЃК
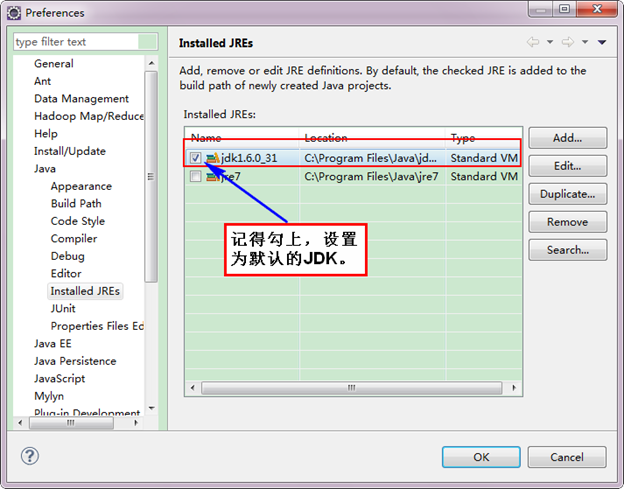
ЁЁЁЁНгзХЩшжУComplierЁЃ
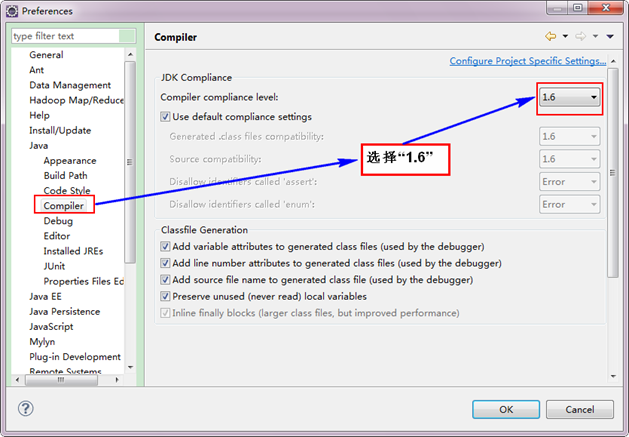
3.2 ЩшжУEclipseЕФБрТыЮЊUTF-8
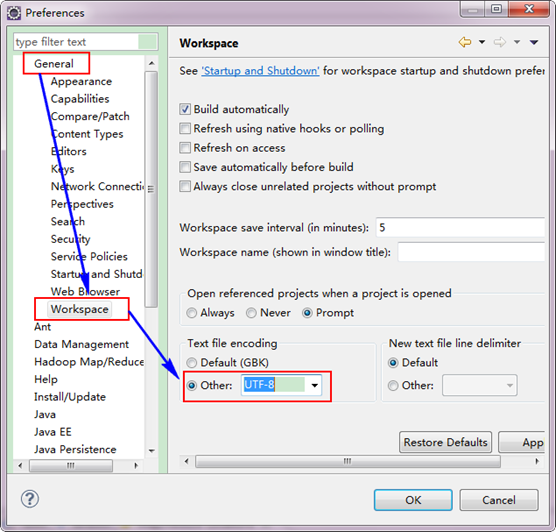
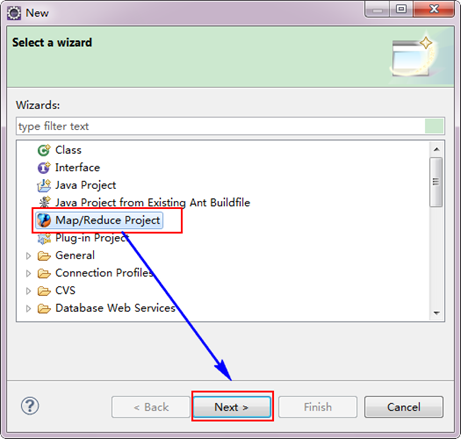
3.3 ДДНЈMapReduceЯюФП
ЁЁЁЁДг"File"ВЫЕЅЃЌбЁдё"Other"ЃЌевЕН"Map/Reduce Project"ЃЌШЛКѓбЁдёЫќЁЃ
ЁЁЁЁНгзХЃЌЬюаДMapReduceЙЄГЬЕФУћзжЮЊ"WordCountProject"ЃЌЕуЛї"finish"ЭъГЩЁЃ
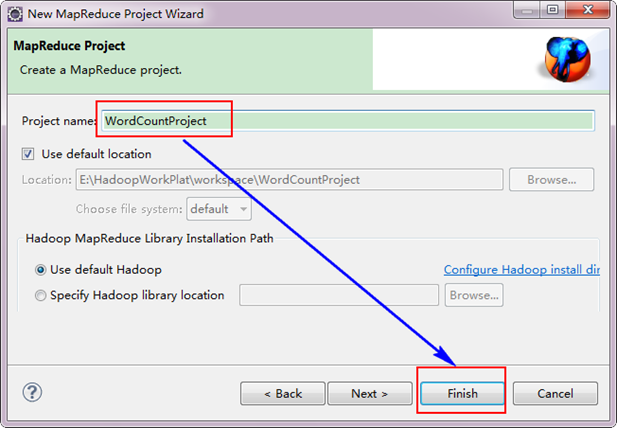
ЁЁЁЁФПЧАЮЊжЙЮвУЧвбОГЩЙІДДНЈСЫMapReduceЯюФПЃЌЮвУЧЗЂЯждкEclipseШэМўЕФзѓВрЖрСЫЮвУЧЕФИеВХНЈСЂЕФЯюФПЁЃ
3.4 ДДНЈWordCountРр
ЁЁЁЁбЁдё"WordCountProject"ЙЄГЬЃЌгвЛїЕЏГіВЫЕЅЃЌШЛКѓбЁдё"New"ЃЌНгзХбЁдё"Class"ЃЌШЛКѓЬюаДШчЯТаХЯЂЃК
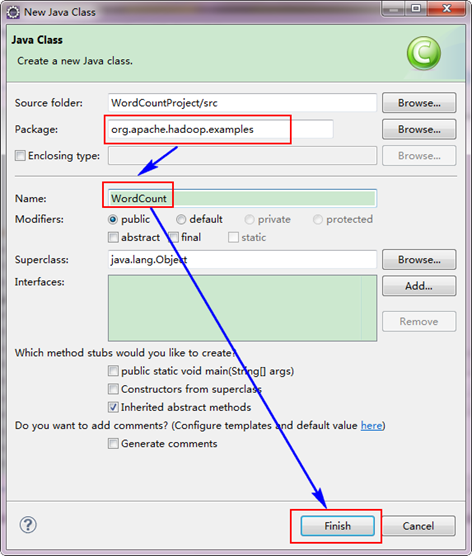
ЁЁЁЁвђЮЊЮвУЧжБНггУHadoop1.0.0здДјЕФWordCountГЬађЃЌЫљвдБЈУћашвЊКЭДњТыжаЕФвЛжТЮЊ"org.apache.hadoop.examples"ЃЌРрУћвВБиаывЛжТЮЊ"WordCount"ЁЃетИіДњТыЗХдкШчЯТЕФНсЙЙжаЁЃ
hadoop-1.0.0
|---src
|---examples
|---org
|---apache
|---hadoop
|---examples
ЁЁЁЁДгЩЯУцФПТМжаевМћ"WordCount.java"ЮФМўЃЌгУМЧЪТБОДђПЊЃЌШЛКѓАбДњТыИДжЦЕНИеВХНЈСЂЕФjavaЮФМўжаЁЃЕБШЛдДТыгааЉБфЖЏЃЌБфЖЏЕФКьЩЋвбОБъМЧГіЁЃ
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one); }
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "192.168.1.2:9001");
String[] ars=new String[]{"input","newout"};
String[] otherArgs = new GenericOptionsParser(conf, ars).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
ЁЁЁЁБИзЂЃКШчЙћВЛМг"conf.set("mapred.job.tracker", "192.168.1.2:9001");"ЃЌНЋЬсЪОФуЕФШЈЯоВЛЙЛЃЌЦфЪЕееГЩетбљЕФдвђЪЧИеВХЩшжУЕФ"Map/Reduce Location"ЦфжаЕФХфжУВЛЪЧЭъШЋЦ№зїгУЃЌЖјЪЧдкБОЕиЕФДХХЬЩЯНЈСЂСЫЮФМўЃЌВЂГЂЪддЫааЃЌЯдШЛЪЧВЛааЕФЁЃЮвУЧвЊШУEclipseЬсНЛзївЕЕНHadoopМЏШКЩЯЃЌЫљвдЮвУЧетРяЪжЖЏЬэМгJobдЫааЕижЗЁЃЯъЯИВЮПМ"ГЃМћЮЪЬтFAQ_3"ЁЃ
3.5 дЫааWordCountГЬађ
ЁЁЁЁбЁдё"Wordcount.java"ГЬађЃЌгвЛївЛДЮАДее"Run ASàRun on Hadoop"дЫааЁЃШЛКѓЛсЕЏГіШчЯТЭМЃЌАДееЯТЭМНјааВйзїЁЃ
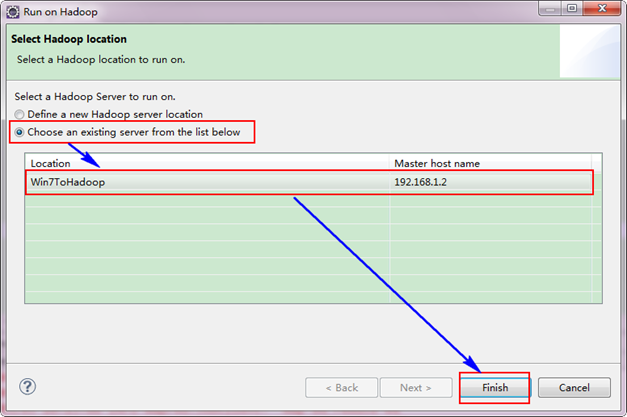
ЁЁЁЁдЫааНсЙћШчЯТЃК
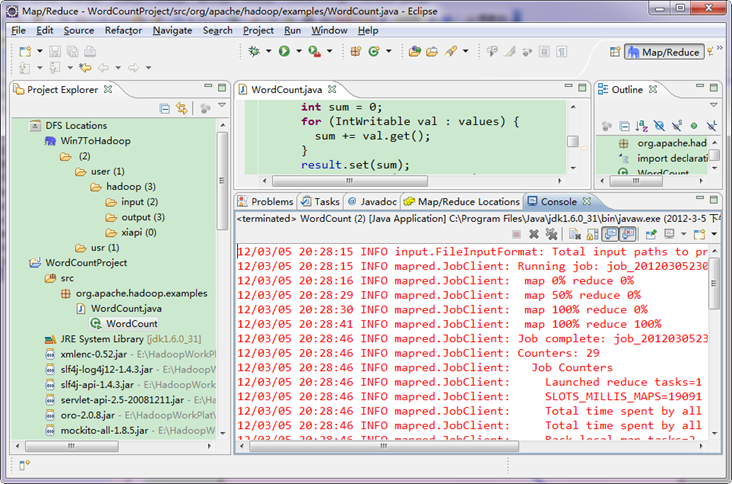
ЁЁЁЁДгЩЯЭМжаЮвУЧЕУжЊЮвУЧЕФГЬађвбОдЫааГЩЙІСЫЁЃ
3.6 ВщПДWordCountдЫааНсЙћ
ЁЁЁЁВщПДEclipseШэМўзѓВрЃЌгвЛї"DFS LocationsàWin7ToHadoopàuseràhadoop"ЃЌЕуЛїЫЂаТАДХЅ"Refresh"ЃЌЮвУЧИеВХГіЯжЕФЮФМўМа"newoutput"ЛсГіЯжЁЃМЧЕУ"newoutput"ЮФМўМаЪЧдЫааГЬађЪБздЖЏДДНЈЕФЃЌШчЙћвбОДцдкЯрЭЌЕФЕФЮФМўМаЃЌвЊУДГЬађЛЛИіаТЕФЪфГіЮФМўМаЃЌвЊУДЩОГ§HDFSЩЯЕФФЧИіжиУћЮФМўМаЃЌВЛШЛЛсГіДэЁЃ
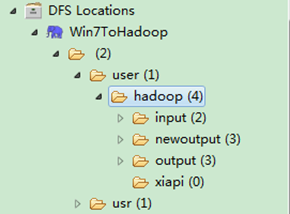
ЁЁЁЁДђПЊ"newoutput"ЮФМўМаЃЌДђПЊ"part-r-00000"ЮФМўЃЌПЩвдПДМћжДааКѓЕФНсЙћЁЃ
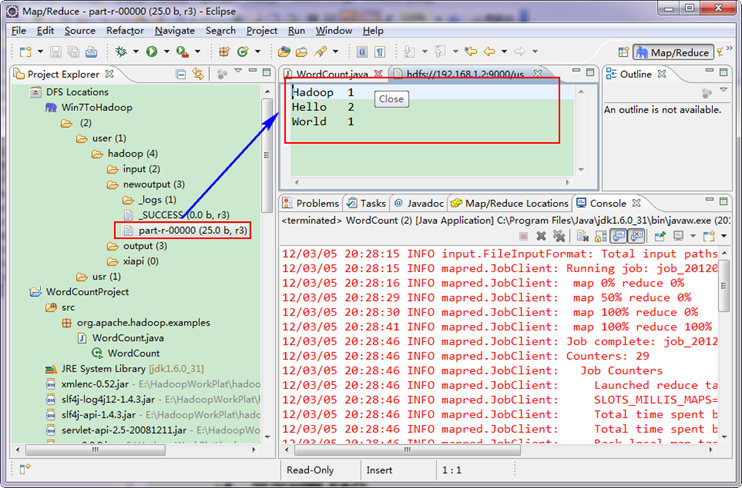
ЁЁЁЁЕНДЫЮЊжЙЃЌEclipseПЊЗЂЛЗОГЩшжУвбОЭъБЯЃЌВЂЧвГЩЙІдЫааWordcountГЬађЃЌЯТвЛВНЮвУЧеце§ПЊЪМHadoopжЎТУЁЃ
4ЁЂГЃМћЮЪЬтFAQ
4.1 "error: failure to login"ЮЪЬт
ЁЁЁЁЯТУцвдЭјЩЯевЕФ"hadoop-0.20.203.0"ЮЊР§ЃЌЮвдкЪЙгУ"V1.0"ЪБвВГіЯжетбљЕФЧщПіЃЌдвђОЭЪЧФЧИі"hadoop-eclipse-plugin-1.0.0_V1.0.jar"ЃЌЪЧжБНгАбдДТыБрвыЖјГЩЃЌЙЪЖјШБЩйЯргІЕФJarАќЁЃОпЬхЧщПіШчЯТ
ЁЁЁЁЯъЯИЕижЗЃКhttp://blog.csdn.net/chengfei112233/article/details/7252404
ЁЁЁЁдкЮвЪЕМљГЂЪджаЃЌЗЂЯжhadoop-0.20.203.0АцБОЕФИУАќШчЙћжБНгИДжЦЕНeclipseЕФВхМўФПТМжаЃЌдкСЌНгDFSЪБЛсГіЯжДэЮѓЃЌЬсЪОаХЯЂЮЊЃК "error: failure to login"ЁЃ
ЁЁЁЁЕЏГіЕФДэЮѓЬсЪОПђФкШнЮЊ"An internal error occurred during: "Connecting to DFS hadoop".org/apache/commons/configuration/Configuration". ОЙ§ВьПДEclipseЕФlogЃЌЗЂЯжЪЧШБЩйjarАќЕМжТЕФЁЃНјвЛВНВщевзЪСЯКѓЃЌЗЂЯжжБНгИДжЦhadoop-eclipse-plugin-0.20.203.0.jarЃЌИУАќжаlibФПТМЯТШБЩйСЫjarАќЁЃ
ЁЁЁЁОЙ§ЭјЩЯзЪСЯЫбМЏЃЌДЫДІИјГіе§ШЗЕФАВзАЗНЗЈЃК
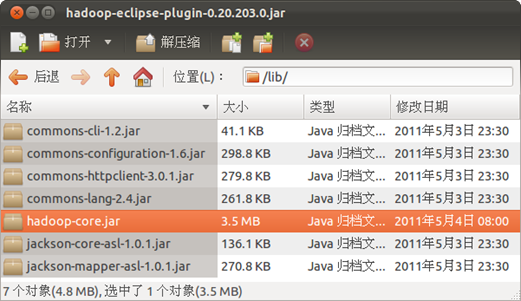
ЁЁЁЁЪзЯШвЊЖдhadoop-eclipse-plugin-0.20.203.0.jarНјаааоИФЁЃгУЙщЕЕЙмРэЦїДђПЊИУАќЃЌЗЂЯжжЛгаcommons-cli-1.2.jar КЭhadoop-core.jarСНИіАќЁЃНЋhadoop/libФПТМЯТЕФЃК
-
commons-configuration-1.6.jar ,
-
commons-httpclient-3.0.1.jar ,
-
commons-lang-2.4.jar ,
-
jackson-core-asl-1.0.1.jar
-
jackson-mapper-asl-1.0.1.jar
вЛЙВ5ИіАќИДжЦЕНhadoop-eclipse-plugin-0.20.203.0.jarЕФlibФПТМЯТЃЌШчЯТЭМЃК
ЁЁЁЁШЛКѓЃЌаоИФИУАќMETA-INFФПТМЯТЕФMANIFEST.MFЃЌНЋclasspathаоИФЮЊвЛЯТФкШнЃК
Bundle-ClassPath:classes/,lib/hadoop-core.jar,lib/commons-cli-1.2.jar,lib/commons-httpclient-3.0.1.jar,lib/jackson-core-asl-1.0.1.jar,lib/jackson-mapper-asl-1.0.1.jar,lib/commons-configuration-1.6.jar,lib/commons-lang-2.4.jar
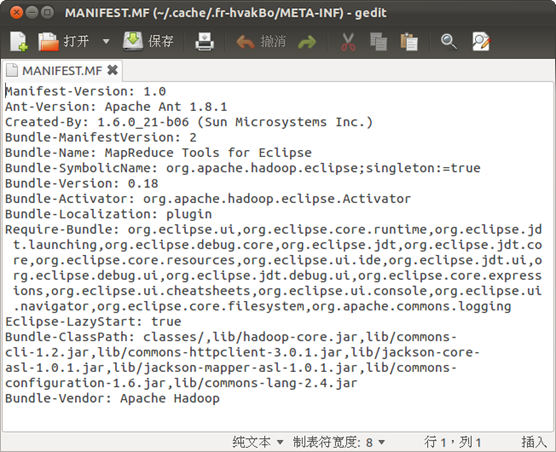
ЁЁЁЁетбљОЭЭъГЩСЫЖдhadoop-eclipse-plugin-0.20.203.0.jarЕФаоИФЁЃ
ЁЁЁЁзюКѓЃЌНЋhadoop-eclipse-plugin-0.20.203.0.jarИДжЦЕНEclipseЕФpluginsФПТМЯТЁЃ
ЁЁЁЁБИзЂЃКЩЯУцЕФВйзїЖд"hadoop-1.0.0"вЛбљЪЪгУЁЃ
4.2 "Permission denied"ЮЪЬт
ЁЁЁЁЭјЩЯЪдСЫКмЖрЃЌгаЬсЕН"hadoop fs -chmod 777 /user/hadoop "ЃЌгаЬсЕН"dfs.permissions ЕФХфжУЯюЃЌНЋvalueжЕИФЮЊ false"ЃЌгаЬсЕН"hadoop.job.ugi"ЃЌЕЋЪЧЭЈЭЈУЛгааЇЙћЁЃ
ЁЁЁЁВЮПМЮФЯзЃК
ЕижЗ1ЃКhttp://www.cnblogs.com/acmy/archive/2011/10/28/2227901.html
ЕижЗ2ЃКhttp://sunjun041640.blog.163.com/blog/static/25626832201061751825292/
ЁЁЁЁ ДэЮѓРраЭЃКorg.apache.hadoop.security.AccessControlException: org.apache.hadoop.security .AccessControlException: Permission denied: user=*********, access=WRITE, inode="hadoop": hadoop:supergroup:rwxr-xr-x
ЁЁЁЁ НтОіЗНАИЃК
ЁЁЁЁЁЁЁЁЮвЕФНтОіЗНАИжБНгАбЯЕЭГЙмРэдБЕФУћзжИФГЩФуЕФHadoopМЏШКдЫааhadoopЕФФЧИігУЛЇЁЃ
4.3 "Failed to set permissions of path"ЮЪЬт
ЁЁЁЁЁЁВЮПМЮФЯзЃКhttps://issues.apache.org/jira/browse/HADOOP-8089
ЁЁЁЁЁЁДэЮѓаХЯЂШчЯТЃК
ЁЁЁЁЁЁЁЁERROR security.UserGroupInformation: PriviledgedActionException as: hadoop cause:java.io.IOException Failed to set permissions of path:\usr\hadoop\tmp\mapred\staging\hadoop753422487\.staging to 0700 Exception in thread "main" java.io.IOException: Failed to set permissions of path: \usr\hadoop\tmp \mapred\staging\hadoop753422487\.staging to 0700
ЁЁЁЁЁЁНтОіЗНЗЈЃК
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "[server]:9001");
ЁЁЁЁ "[server]:9001"жаЕФ"[server]"ЮЊHadoopМЏШКMasterЕФIPЕижЗЁЃ
4.4 "hadoop mapredжДааФПТМЮФМўШЈ"ЯоЮЪЬт
ЁЁЁЁЁЁВЮПМЮФЯзЃКhttp://blog.csdn.net/azhao_dn/article/details/6921398
ЁЁЁЁЁЁДэЮѓаХЯЂШчЯТЃК
ЁЁЁЁЁЁjob Submission failed with exception 'java.io.IOException(The ownership/permissions on the staging directory /tmp/hadoop-hadoop-user1/mapred/staging/hadoop-user1/.staging is not as expected. It is owned by hadoop-user1 and permissions are rwxrwxrwx. The directory must be owned by the submitter hadoop-user1 or by hadoop-user1 and permissions must be rwx------)
ЁЁЁЁЁЁаоИФШЈЯоЃК

ЁЁЁЁетбљОЭФмНтОіЮЪЬтЁЃ
ЁЁЁЁЮФеТЯТдиЕижЗЃКhttp://files.cnblogs.com/xia520pi/HadoopCluster_Vol.7.rar
(д№ШЮБрМЃКIT)
1ЁЂHadoopПЊЗЂЛЗОГМђНщ1.1 HadoopМЏШКМђНщЁЁЁЁJavaАцБОЃКjdk-6u31-linux-i586.bin ЁЁЁЁLinuxЯЕЭГЃКCentOS6.0 ЁЁЁЁHadoopАцБОЃКhadoop-1.0.0.tar.gz 1.2 WindowsПЊЗЂМђНщЁЁЁЁJavaАцБОЃКjdk-6u31-windows-i586.exe ЁЁЁЁWinЯЕЭГЃКWindows 7 ЦьНЂАц ЁЁЁЁEclipseШэМўЃКeclipse-jee-indigo-SR1-win32.zip | eclipse-jee-helios-SR2-win32.zip ЁЁЁЁHadoopШэМўЃКhadoop-1.0.0.tar.gz ЁЁЁЁHadoop Eclipse ВхМўЃКhadoop-eclipse-plugin-1.0.0.jar ЁЁЁЁЯТдиЕижЗЃКhttp://download.csdn.net/detail/xia520pi/4113746 ЁЁЁЁБИзЂЃКЯТУцЪЧЭјЩЯЪеМЏЕФЪеМЏЕФ"hadoop-eclipse-plugin-1.0.0.jar"ЃЌГ§"АцБО2.0"ЪЧИљОн"V1.0"АДее"ГЃМћЮЪЬтFAQ_1"ИФЕФжЎЭтЃЌЪЃгрЕФ"V3.0"ЁЂ"V4.0"КЭ"V5.0"КЭ"V2.0"вЛбљЪЧБ№ШЫвбОХЊКУЕФЃЌЖјЧвЮввбОЖМВтЪдЙ§ЃЌУЛгаШЮКЮЮЪЬтЃЌПЩвдЗХаФЪЙгУЁЃЮвУЧетРябЁдёЕк"V5.0"ЪЙгУЁЃМЧЕУдкЪЙгУЪБжиаТУќУћЮЊ"hadoop-eclipse-plugin-1.0.0.jar"ЁЃ
2ЁЂHadoop EclipseМђНщКЭЪЙгУ2.1 EclipseВхМўНщЩмЁЁЁЁHadoopЪЧвЛИіЧПДѓЕФВЂааПђМмЃЌЫќдЪаэШЮЮёдкЦфЗжВМЪНМЏШКЩЯВЂааДІРэЁЃЕЋЪЧБраДЁЂЕїЪдHadoopГЬађЖМгаКмДѓФбЖШЁЃе§вђЮЊШчДЫЃЌHadoopЕФПЊЗЂепПЊЗЂГіСЫHadoop EclipseВхМўЃЌЫќдкHadoopЕФПЊЗЂЛЗОГжаЧЖШыСЫEclipseЃЌДгЖјЪЕЯжСЫПЊЗЂЛЗОГЕФЭМаЮЛЏЃЌНЕЕЭСЫБрГЬФбЖШЁЃдкАВзАВхМўЃЌХфжУHadoopЕФЯрЙиаХЯЂжЎКѓЃЌШчЙћгУЛЇДДНЈHadoopГЬађЃЌВхМўЛсздЖЏЕМШыHadoopБрГЬНгПкЕФJARЮФМўЃЌетбљгУЛЇОЭПЩвддкEclipseЕФЭМаЮЛЏНчУцжаБраДЁЂЕїЪдЁЂдЫааHadoopГЬађЃЈАќРЈЕЅЛњГЬађКЭЗжВМЪНГЬађЃЉЃЌвВПЩвддкЦфжаВщПДздМКГЬађЕФЪЕЪБзДЬЌЁЂДэЮѓаХЯЂКЭдЫааНсЙћЃЌЛЙПЩвдВщПДЁЂЙмРэHDFSвдМАЮФМўЁЃзмЕиРДЫЕЃЌHadoop EclipseВхМўАВзАМђЕЅЃЌЪЙгУЗНБуЃЌЙІФмЧПДѓЃЌгШЦфЪЧдкHadoopБрГЬЗНУцЃЌЪЧHadoopШыУХКЭHadoopБрГЬБиВЛПЩЩйЕФЙЄОпЁЃ 2.2 HadoopЙЄзїФПТММђНщЁЁЁЁЮЊСЫвдКѓЗНБуПЊЗЂЃЌЮвУЧАДееЯТУцАбПЊЗЂжагУЕНЕФШэМўАВзАдкДЫФПТМжаЃЌJDKАВзАГ§ЭтЃЌЮветРяАбJDKАВзАдкCХЬЕФФЌШЯАВзАТЗОЖЯТЃЌЯТУцЪЧЮвЕФЙЄзїФПТМЃК
ЁЁЁЁАДееЩЯУцФПТМАбEclipseКЭHadoopНтбЙЕН"E:\HadoopWorkPlat"ЯТУцЃЌВЂДДНЈ"workplace"зїЮЊEclipseЕФЙЄзїПеМфЁЃ
ЁЁЁЁБИзЂЃКДѓМвПЩвдАДеездМКЕФЧщПіЃЌВЛвЛЖЈАДееЮвЕФНсЙЙРДЩшМЦЁЃ 2.3 аоИФЯЕЭГЙмРэдБУћзжЁЁЁЁОЙ§СНЬьЖрДЮЬНЫїЃЌЮЊСЫЪЙEclipseФме§ГЃЖдHadoopМЏШКЕФHDFSЩЯЕФЮФМўФмНјаааоИФКЭЩОГ§ЃЌЫљвдаоИФФуЙЄзїЪБЫљгУЕФWin7ЯЕЭГЙмРэдБУћзжЃЌФЌШЯвЛАуЮЊ"Administrator"ЃЌАбЫќаоИФЮЊ"hadoop"ЃЌДЫгУЛЇУћгыHadoopМЏШКЦеЭЈгУЛЇвЛжТЃЌДѓМвгІИУМЧЕУЮвУЧHadoopМЏШКжаЫљгаЕФЛњЦїЖМгавЛИіЦеЭЈгУЛЇ——hadoopЃЌЖјЧвHadoopдЫаавВЪЧгУетИігУЛЇНјааЕФЁЃЮЊСЫВЛжСгкЮЊШЈЯоПрФеЃЌЮвУЧПЩвдаоИФWin7ЩЯЯЕЭГЙмРэдБЕФаеУћЃЌетбљОЭБмУтГіЯжИУгУЛЇдкHadoopМЏШКЩЯУЛгаШЈЯоЕШЖМЬлЮЪЬтЃЌЛсЕМжТдкEclipseжаЖдHadoopМЏШКЕФHDFSДДНЈКЭЩОГ§ЮФМўЪмгАЯьЁЃ ЁЁЁЁФуПЩвдзівЛЯТЪЕбщЃЌВщПДMaster.HadoopЛњЦїЩЯ"/usr/hadoop/logs"ЯТУцЕФШежОЁЃЗЂЯжШЈЯоВЛЙЛЃЌВЛФмНјаа"Write"ВйзїЃЌЭјЩЯгаМИжжНтОіЗНАИЃЌЕЋЪЧЖдHadoop1.0ВЛЦ№зїгУЃЌЯъЧщМћ"ГЃМћЮЪЬтFAQ_2"ЁЃЯТУцЮвУЧНјаааоИФЙмРэдБУћзжЁЃ ЁЁЁЁЪзЯШ"гвЛї"зРУцЩЯЭМБъ"ЮвЕФЕчФд"ЃЌбЁдё"ЙмРэ"ЃЌЕЏГіНчУцШчЯТЃК
ЁЁЁЁНгзХбЁдё"БОЕигУЛЇКЭзщ"ЃЌеЙПЊ"гУЛЇ"ЃЌевЕНЯЕЭГЙмРэдБ"Administrator"ЃЌаоИФЦфЮЊ"hadoop"ЃЌВйзїНсЙћШчЯТЭМЃК
ЁЁЁЁзюКѓЃЌАбЕчФдНјаа"зЂЯњ"Лђеп"жиЦєЕчФд"ЃЌетбљВХФмЪЙЙмРэдБВХФмгУетИіУћзжЁЃ 2.4 EclipseВхМўПЊЗЂХфжУЁЁЁЁЕквЛВНЃКАбЮвУЧЕФ"hadoop-eclipse-plugin-1.0.0.jar"ЗХЕНEclipseЕФФПТМЕФ"plugins"жаЃЌШЛКѓжиаТEclipseМДПЩЩњаЇЁЃ
ЁЁЁЁЩЯУцЪЧЮвЕФ"hadoop-eclipse-plugin"ВхМўЗХжУЕФЕиЗНЁЃжиЦєEclipseШчЯТЭМЃК
ЁЁЁЁЯИаФЕФФуДгЩЯЭМжазѓВр"Project Explorer"ЯТУцЗЂЯж"DFS Locations"ЃЌЫЕУїEclipseвбОЪЖБ№ИеВХЗХШыЕФHadoop EclipseВхМўСЫЁЃ
ЁЁЁЁЕкЖўВНЃКбЁдё"Window"ВЫЕЅЯТЕФ"Preference"ЃЌШЛКѓЕЏГівЛИіДАЬхЃЌдкДАЬхЕФзѓВрЃЌгавЛСабЁЯюЃЌРяУцЛсЖрГі"Hadoop Map/Reduce"бЁЯюЃЌЕуЛїДЫбЁЯюЃЌбЁдёHadoopЕФАВзАФПТМЃЈШчЮвЕФHadoopФПТМЃКE:\HadoopWorkPlat\hadoop-1.0.0ЃЉЁЃНсЙћШчЯТЭМЃК
ЁЁЁЁЕкШ§ВНЃКЧаЛЛ"Map/Reduce"ЙЄзїФПТМЃЌгаСНжжЗНЗЈЃК ЁЁЁЁ1ЃЉбЁдё"Window"ВЫЕЅЯТбЁдё"Open Perspective"ЃЌЕЏГівЛИіДАЬхЃЌДгжабЁдё"Map/Reduce"бЁЯюМДПЩНјааЧаЛЛЁЃ
ЁЁЁЁ2ЃЉдкEclipseШэМўЕФгвЩЯНЧЃЌЕуЛїЭМБъ" ЁЁЁЁЧаЛЛЕН"Map/Reduce"ЙЄзїФПТМЯТЕФНчУцШчЯТЭМЫљЪОЁЃ
ЁЁЁЁЕкЫФВНЃКНЈСЂгыHadoopМЏШКЕФСЌНгЃЌдкEclipseШэМўЯТУцЕФ"Map/Reduce Locations"НјаагвЛїЃЌЕЏГівЛИібЁЯюЃЌбЁдё"New Hadoop Location"ЃЌШЛКѓЕЏГівЛИіДАЬхЁЃ
ЁЁЁЁзЂвтЩЯЭМжаЕФКьЩЋБъзЂЕФЕиЗНЃЌЪЧашвЊЮвУЧЙизЂЕФЕиЗНЁЃ
ЁЁЁЁБИзЂЃКетРяУцЕФHostЁЂPortЗжБ№ЮЊФудкmapred-site.xmlЁЂcore-site.xmlжаХфжУЕФЕижЗМАЖЫПкЁЃВЛЧхГўЕФПЩвдВЮПМ"HadoopМЏШК_Ек5Цк_HadoopАВзАХфжУ_V1.0"НјааВщПДЁЃ ЁЁЁЁНгзХЕуЛї"Advanced parameters"ДгжаевМћ"hadoop.tmp.dir"ЃЌаоИФГЩЮЊЮвУЧHadoopМЏШКжаЩшжУЕФЕижЗЃЌЮвУЧЕФHadoopМЏШКЪЧ"/usr/hadoop/tmp"ЃЌетИіВЮЪ§дк"core-site.xml"НјааСЫХфжУЁЃ
ЁЁЁЁЕуЛї"finish"жЎКѓЃЌЛсЗЂЯжEclipseШэМўЯТУцЕФ"Map/Reduce Locations"ГіЯжвЛЬѕаХЯЂЃЌОЭЪЧЮвУЧИеВХНЈСЂЕФ"Map/Reduce Location"ЁЃ
ЁЁЁЁЕкЮхВНЃКВщПДHDFSЮФМўЯЕЭГЃЌВЂГЂЪдНЈСЂЮФМўМаКЭЩЯДЋЮФМўЁЃЕуЛїEclipseШэМўзѓВрЕФ"DFS Locations"ЯТУцЕФ"Win7ToHadoop"ЃЌОЭЛсеЙЪОГіHDFSЩЯЕФЮФМўНсЙЙЁЃ
ЁЁЁЁгвЛї"Win7ToHadoopàuseràhadoop"ПЩвдГЂЪдНЈСЂвЛИі"ЮФМўМа--xiapi"ЃЌШЛКѓгвЛїЫЂаТОЭФмВщПДЮвУЧИеВХНЈСЂЕФЮФМўМаЁЃ
ЁЁЁЁДДНЈЭъжЎКѓЃЌВЂЫЂаТЃЌЯдЪОНсЙћШчЯТЃК
ЁЁЁЁгУSecureCRTдЖГЬЕЧТМ"Master.Hadoop"ЗўЮёЦїЃЌгУЯТУцУќСюВщПДЪЧЗёвбОНЈСЂвЛИі"xiapi"ЕФЮФМўМаЁЃ
ЁЁЁЁЕНДЫЮЊжЙЃЌЮвУЧЕФHadoop EclipseПЊЗЂЛЗОГвбОХфжУЭъБЯЃЌВЛОЁаЫЕФЭЌбЇПЩвдЩЯДЋЕуБОЕиЮФМўЕНHDFSЗжВМЪНЮФМўЩЯЃЌПЩвдЛЅЯрЖдБШвтМћЮФМўЪЧЗёвбОЩЯДЋГЩЙІЁЃ 3ЁЂEclipseдЫааWordCountГЬађ3.1 ХфжУEclipseЕФJDKЁЁЁЁШчЙћЕчФдЩЯВЛНіНіАВзАЕФJDK6.0ЃЌФЧУДвЊШЗЖЈвЛЯТEclipseЕФЦНЬЈЕФФЌШЯJDKЪЧЗё6.0ЁЃДг"Window"ВЫЕЅЯТбЁдё"Preference"ЃЌЕЏГівЛИіДАЬхЃЌДгДАЬхЕФзѓВревМћ"Java"ЃЌбЁдё"Installed JREs"ЃЌШЛКѓЬэМгJDK6.0ЁЃЯТУцЪЧЮвЕФФЌШЯбЁдёJREЁЃ
ЁЁЁЁЯТУцЪЧУЛгаЬэМгжЎЧАЕФЩшжУШчЯТЃК
ЁЁЁЁЯТУцЪЧЬэМгЭъJDK6.0жЎКѓНсЙћШчЯТЃК
ЁЁЁЁНгзХЩшжУComplierЁЃ
3.2 ЩшжУEclipseЕФБрТыЮЊUTF-8
3.3 ДДНЈMapReduceЯюФПЁЁЁЁДг"File"ВЫЕЅЃЌбЁдё"Other"ЃЌевЕН"Map/Reduce Project"ЃЌШЛКѓбЁдёЫќЁЃ
ЁЁЁЁНгзХЃЌЬюаДMapReduceЙЄГЬЕФУћзжЮЊ"WordCountProject"ЃЌЕуЛї"finish"ЭъГЩЁЃ
ЁЁЁЁФПЧАЮЊжЙЮвУЧвбОГЩЙІДДНЈСЫMapReduceЯюФПЃЌЮвУЧЗЂЯждкEclipseШэМўЕФзѓВрЖрСЫЮвУЧЕФИеВХНЈСЂЕФЯюФПЁЃ
3.4 ДДНЈWordCountРрЁЁЁЁбЁдё"WordCountProject"ЙЄГЬЃЌгвЛїЕЏГіВЫЕЅЃЌШЛКѓбЁдё"New"ЃЌНгзХбЁдё"Class"ЃЌШЛКѓЬюаДШчЯТаХЯЂЃК
ЁЁЁЁвђЮЊЮвУЧжБНггУHadoop1.0.0здДјЕФWordCountГЬађЃЌЫљвдБЈУћашвЊКЭДњТыжаЕФвЛжТЮЊ"org.apache.hadoop.examples"ЃЌРрУћвВБиаывЛжТЮЊ"WordCount"ЁЃетИіДњТыЗХдкШчЯТЕФНсЙЙжаЁЃ
ЁЁЁЁДгЩЯУцФПТМжаевМћ"WordCount.java"ЮФМўЃЌгУМЧЪТБОДђПЊЃЌШЛКѓАбДњТыИДжЦЕНИеВХНЈСЂЕФjavaЮФМўжаЁЃЕБШЛдДТыгааЉБфЖЏЃЌБфЖЏЕФКьЩЋвбОБъМЧГіЁЃ
ЁЁЁЁБИзЂЃКШчЙћВЛМг"conf.set("mapred.job.tracker", "192.168.1.2:9001");"ЃЌНЋЬсЪОФуЕФШЈЯоВЛЙЛЃЌЦфЪЕееГЩетбљЕФдвђЪЧИеВХЩшжУЕФ"Map/Reduce Location"ЦфжаЕФХфжУВЛЪЧЭъШЋЦ№зїгУЃЌЖјЪЧдкБОЕиЕФДХХЬЩЯНЈСЂСЫЮФМўЃЌВЂГЂЪддЫааЃЌЯдШЛЪЧВЛааЕФЁЃЮвУЧвЊШУEclipseЬсНЛзївЕЕНHadoopМЏШКЩЯЃЌЫљвдЮвУЧетРяЪжЖЏЬэМгJobдЫааЕижЗЁЃЯъЯИВЮПМ"ГЃМћЮЪЬтFAQ_3"ЁЃ 3.5 дЫааWordCountГЬађЁЁЁЁбЁдё"Wordcount.java"ГЬађЃЌгвЛївЛДЮАДее"Run ASàRun on Hadoop"дЫааЁЃШЛКѓЛсЕЏГіШчЯТЭМЃЌАДееЯТЭМНјааВйзїЁЃ
ЁЁЁЁдЫааНсЙћШчЯТЃК
ЁЁЁЁДгЩЯЭМжаЮвУЧЕУжЊЮвУЧЕФГЬађвбОдЫааГЩЙІСЫЁЃ 3.6 ВщПДWordCountдЫааНсЙћЁЁЁЁВщПДEclipseШэМўзѓВрЃЌгвЛї"DFS LocationsàWin7ToHadoopàuseràhadoop"ЃЌЕуЛїЫЂаТАДХЅ"Refresh"ЃЌЮвУЧИеВХГіЯжЕФЮФМўМа"newoutput"ЛсГіЯжЁЃМЧЕУ"newoutput"ЮФМўМаЪЧдЫааГЬађЪБздЖЏДДНЈЕФЃЌШчЙћвбОДцдкЯрЭЌЕФЕФЮФМўМаЃЌвЊУДГЬађЛЛИіаТЕФЪфГіЮФМўМаЃЌвЊУДЩОГ§HDFSЩЯЕФФЧИіжиУћЮФМўМаЃЌВЛШЛЛсГіДэЁЃ
ЁЁЁЁДђПЊ"newoutput"ЮФМўМаЃЌДђПЊ"part-r-00000"ЮФМўЃЌПЩвдПДМћжДааКѓЕФНсЙћЁЃ
ЁЁЁЁЕНДЫЮЊжЙЃЌEclipseПЊЗЂЛЗОГЩшжУвбОЭъБЯЃЌВЂЧвГЩЙІдЫааWordcountГЬађЃЌЯТвЛВНЮвУЧеце§ПЊЪМHadoopжЎТУЁЃ 4ЁЂГЃМћЮЪЬтFAQ4.1 "error: failure to login"ЮЪЬтЁЁЁЁЯТУцвдЭјЩЯевЕФ"hadoop-0.20.203.0"ЮЊР§ЃЌЮвдкЪЙгУ"V1.0"ЪБвВГіЯжетбљЕФЧщПіЃЌдвђОЭЪЧФЧИі"hadoop-eclipse-plugin-1.0.0_V1.0.jar"ЃЌЪЧжБНгАбдДТыБрвыЖјГЩЃЌЙЪЖјШБЩйЯргІЕФJarАќЁЃОпЬхЧщПіШчЯТ ЁЁЁЁЯъЯИЕижЗЃКhttp://blog.csdn.net/chengfei112233/article/details/7252404 ЁЁЁЁдкЮвЪЕМљГЂЪджаЃЌЗЂЯжhadoop-0.20.203.0АцБОЕФИУАќШчЙћжБНгИДжЦЕНeclipseЕФВхМўФПТМжаЃЌдкСЌНгDFSЪБЛсГіЯжДэЮѓЃЌЬсЪОаХЯЂЮЊЃК "error: failure to login"ЁЃ ЁЁЁЁЕЏГіЕФДэЮѓЬсЪОПђФкШнЮЊ"An internal error occurred during: "Connecting to DFS hadoop".org/apache/commons/configuration/Configuration". ОЙ§ВьПДEclipseЕФlogЃЌЗЂЯжЪЧШБЩйjarАќЕМжТЕФЁЃНјвЛВНВщевзЪСЯКѓЃЌЗЂЯжжБНгИДжЦhadoop-eclipse-plugin-0.20.203.0.jarЃЌИУАќжаlibФПТМЯТШБЩйСЫjarАќЁЃ ЁЁЁЁОЙ§ЭјЩЯзЪСЯЫбМЏЃЌДЫДІИјГіе§ШЗЕФАВзАЗНЗЈЃК ЁЁЁЁЪзЯШвЊЖдhadoop-eclipse-plugin-0.20.203.0.jarНјаааоИФЁЃгУЙщЕЕЙмРэЦїДђПЊИУАќЃЌЗЂЯжжЛгаcommons-cli-1.2.jar КЭhadoop-core.jarСНИіАќЁЃНЋhadoop/libФПТМЯТЕФЃК
вЛЙВ5ИіАќИДжЦЕНhadoop-eclipse-plugin-0.20.203.0.jarЕФlibФПТМЯТЃЌШчЯТЭМЃК
ЁЁЁЁШЛКѓЃЌаоИФИУАќMETA-INFФПТМЯТЕФMANIFEST.MFЃЌНЋclasspathаоИФЮЊвЛЯТФкШнЃК
ЁЁЁЁетбљОЭЭъГЩСЫЖдhadoop-eclipse-plugin-0.20.203.0.jarЕФаоИФЁЃ ЁЁЁЁзюКѓЃЌНЋhadoop-eclipse-plugin-0.20.203.0.jarИДжЦЕНEclipseЕФpluginsФПТМЯТЁЃ ЁЁЁЁБИзЂЃКЩЯУцЕФВйзїЖд"hadoop-1.0.0"вЛбљЪЪгУЁЃ 4.2 "Permission denied"ЮЪЬтЁЁЁЁЭјЩЯЪдСЫКмЖрЃЌгаЬсЕН"hadoop fs -chmod 777 /user/hadoop "ЃЌгаЬсЕН"dfs.permissions ЕФХфжУЯюЃЌНЋvalueжЕИФЮЊ false"ЃЌгаЬсЕН"hadoop.job.ugi"ЃЌЕЋЪЧЭЈЭЈУЛгааЇЙћЁЃ ЁЁЁЁВЮПМЮФЯзЃК ЕижЗ1ЃКhttp://www.cnblogs.com/acmy/archive/2011/10/28/2227901.html ЕижЗ2ЃКhttp://sunjun041640.blog.163.com/blog/static/25626832201061751825292/ ЁЁЁЁ ДэЮѓРраЭЃКorg.apache.hadoop.security.AccessControlException: org.apache.hadoop.security .AccessControlException: Permission denied: user=*********, access=WRITE, inode="hadoop": hadoop:supergroup:rwxr-xr-x ЁЁЁЁ НтОіЗНАИЃК ЁЁЁЁЁЁЁЁЮвЕФНтОіЗНАИжБНгАбЯЕЭГЙмРэдБЕФУћзжИФГЩФуЕФHadoopМЏШКдЫааhadoopЕФФЧИігУЛЇЁЃ 4.3 "Failed to set permissions of path"ЮЪЬтЁЁЁЁЁЁВЮПМЮФЯзЃКhttps://issues.apache.org/jira/browse/HADOOP-8089 ЁЁЁЁЁЁДэЮѓаХЯЂШчЯТЃК ЁЁЁЁЁЁЁЁERROR security.UserGroupInformation: PriviledgedActionException as: hadoop cause:java.io.IOException Failed to set permissions of path:\usr\hadoop\tmp\mapred\staging\hadoop753422487\.staging to 0700 Exception in thread "main" java.io.IOException: Failed to set permissions of path: \usr\hadoop\tmp \mapred\staging\hadoop753422487\.staging to 0700 ЁЁЁЁЁЁНтОіЗНЗЈЃК
ЁЁЁЁ "[server]:9001"жаЕФ"[server]"ЮЊHadoopМЏШКMasterЕФIPЕижЗЁЃ 4.4 "hadoop mapredжДааФПТМЮФМўШЈ"ЯоЮЪЬтЁЁЁЁЁЁВЮПМЮФЯзЃКhttp://blog.csdn.net/azhao_dn/article/details/6921398 ЁЁЁЁЁЁДэЮѓаХЯЂШчЯТЃК ЁЁЁЁЁЁjob Submission failed with exception 'java.io.IOException(The ownership/permissions on the staging directory /tmp/hadoop-hadoop-user1/mapred/staging/hadoop-user1/.staging is not as expected. It is owned by hadoop-user1 and permissions are rwxrwxrwx. The directory must be owned by the submitter hadoop-user1 or by hadoop-user1 and permissions must be rwx------) ЁЁЁЁЁЁаоИФШЈЯоЃК
ЁЁЁЁетбљОЭФмНтОіЮЪЬтЁЃ
(д№ШЮБрМЃКIT) |