|
问题导读: 1.如何配置各个节点之间无密码互通? 2.启动hadoop,看不到进程的原因是什么? 3.配置hadoop的步骤是什么? 4.有哪些配置文件需要修改? 5.如果没有配置文件,该如何找到该配置文件? 6.环境变量配置了,但是不生效的原因是什么? 7.如何查看hadoop2监控页面
首先说一下这个安装过程需要注意的地方
一、使用新建用户可能会遇到的问题
(1)权限问题:对于新手经常使用root,刚开始可以使用,但是如果想真正的学习,必须学会使用其他用户。也就是你需要学会新建用户,但是新建用户,并不是所有人都会的。具体可以参考ubuntu创建新用户并增加管理员权限,这里面使用adduser是最方便的。也就是说你需要通过这里,学会给Linux添加用户,并且赋权,上面那篇文章会对你有所帮助。
(2)使用新建用户,你遇到另外一个问题,就是文件所属权限,因为新建的文件,有的属于root用户,有的属于新建用户,例如下面情况,我们看到mv.sh是属于root用户,大部分属于aboutyun用户。所以当我们两个不同文件不能访问的时候,这个可能是原因之一。也是在这里,当你新建用户的时候,可能会遇到的新问题。

(3)上面我们只是提出了问题,但是根本没有解决方案,这里在提出解决方案,我们如何改变文件所属用户。
比如上图中,mv.sh属于root用户,那么我们怎么让他所属about云用户。可以是下面命令:
解释一下上面命令的含义:
------------------------------------------------------------------------------------------------------------------------------------------------------
1.sudo:如果不是root用户,不带上这个命令会经常遇到麻烦,所以需要养成习惯。至于sudo详细解释可以看下面。
2.chown-》change own的意思。即改变所属文件。对于他不了解的同学,可以查看:让你真正了解chmod和chown命令的用法
3.aboutyun:aboutyun代表aboutyun用户及aboutyun用户组
4.即是被授权的文件
------------------------------------------------------------------------------------------------------------------------------------------------------
上面是针对新手的一个解说,不是必须的,如果对Linux已经很熟悉,可以跳过上面步骤。下面我们开始首先要下载
360网盘: 编译包 访问密码 4e48
百度网盘:链接: 密码: r9kh
(下载包为hadoop2.2)
下载完毕,我们就需要解压
这里是解压到当前路径。
这里就开始动手了,下面也介绍一下整体的情况:
1、这里我们搭建一个由三台机器组成的集群:
172.16.77.15 aboutyun/123456 master
172.16.77.16 aboutyun/123456 slave1
172.16.77.17 aboutyun/123456 slave1
1.1 上面各列分别为IP、user/passwd、hostname
1.2 Hostname可以在/etc/hostname中修改,hostname,hosts的修改详细可以看ubuntu修改hostname
对于三台机器都需要修改:
下面是master的修改:通过命令
然后对你里面的内容修改:

下面修改hostname
修改为master即可

上面hosts基本都一样,只不过hostname有所差别。
2、打通master到slave节点的SSH无密码登陆
这里面打通无密码登录,很多新手遇到了问题,这里安装的时候,具体的操作,可以查阅其他资料:
Hadoop伪分布安装过程:Hadoop单机环境搭建指南(ubuntu)
CentOS6.4之图解SSH无验证双向登陆配置
这是个人总结的哦命令,相信对你有所帮助
个人常用知识总结
然后这里在展示一下,authorized_keys是什么样子的:

上面的原理,就是我把工钥放到里面,然后本台机器就可以ssh无密码登录了。如果想彼此无密码登录,那么就需要把彼此的工钥(*.pub)放到authorized_keys里面
然后我们进行下面步骤:
3.1 安装ssh
一般系统是默认安装了ssh命令的。如果没有,或者版本比较老,则可以重新安 装:
sudo apt-get install ssh
3.2设置local无密码登陆
具体步骤如下:
第一步:产生密钥
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
第二部:导入authorized_keys
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
第二部导入的目的是为了无密码等,这样输入如下命令:
就可以无密码登录了。
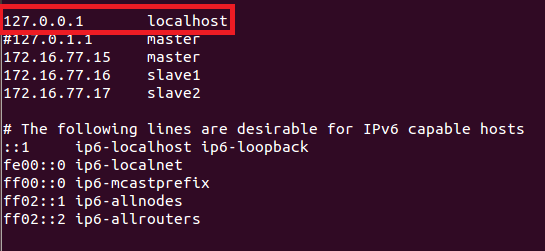
下面展示一下hosts的配置,及无密码登录的效果
locahost的配置
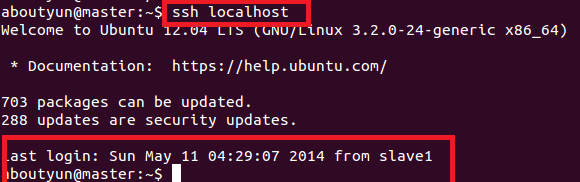
无密码登录效果:
3.3设置远程无密码登陆
进入master的.ssh目录
scp authorized_keys aboutyun@slave1:~/.ssh/authorized_keys_from_master
进入slave1的.ssh目录
cat authorized_keys_from_master >> authorized_keys
至此,可以在master上面ssh slave1进行无密码登陆了。
【注意】:以上操作在每台机器上面都要进行。
这里在强调一下原理:
------------------------------------------------------------------------
根据上面的资料相信你能得到互通,这里展现一下效果:
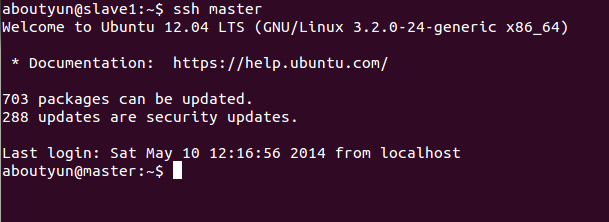
上面是slave1无密码登录master
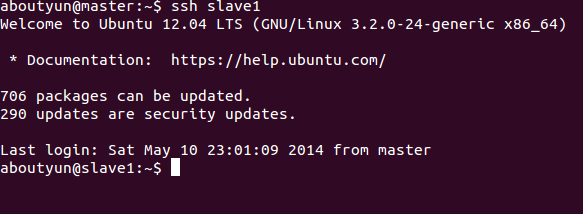
这里是master无密码登录slave1
------------------------------------------------------------------------
4、安装jdk
安装JDK还是比较简单的,这里
4.1、下载jdk
http://yunpan.cn/QiujtEVgRTJ4S 访问密码 b488
4.2、安装jdk(这里以.tar.gz版本,64位系统为例)
jdk的安装可以参考Hadoop伪分布安装过程:Hadoop单机环境搭建指南(ubuntu)
这里直接解压到了/usr/jdk1.7下面:

上面首先第一步:
至此,jkd安装完毕,下面配置环境变量
一、PATH配置
这里提供一个简单的方法:通过下面命令 1.export PATH=$PATH:/usr/java/jdk1.7.0_51/bin 通过cat命令,可以查看  2.为了保证生效执行下面命令 二、CLASSTH配置 上面只是配置了PATH,还需在配置CLASSTH export CLASSPATH=.:/usr/java/jdk1.7.0_51/jre/lib 执行配置完毕 如果不起作用,采用通过下面配置: java.sh配置 因为重启之后,很有会被还原,下面还需要配置java.sh 这里可以通过 cd /etc/profile.d vi java.sh 把下面两行放到java.sh export PATH=$PATH:/usr/java/jdk1.7.0_51/bin export CLASSPATH=.:/usr/java/jdk1.7.0_51/jre/lib 保存。这样就配置完毕了。
执行下面命令:
现在在执行 java -version就ok了

【注意】每台机器执行相同操作,最后将java安装在相同路径下
三、关闭每台机器的防火墙
ufw disable (重启生效)
第三部分 Hadoop 2.2安装过程
一、需要注意的问题
hadoop2.2的配置还是比较简单的,但是可能会遇到各种各样的问题。最常讲的就是看不到进程。
看不到进程大致有两个原因:
1.你的配置文件有问题。
对于配置文件,主机名,空格之类的这些都不要带上。仔细检查
2.Linux的权限不正确。
最常出问题的是core-site.xml,与hdfs-site.xml。
core-site.xml
说一下上面参数的含义,这里是hadoop的临时文件目录,file的含义是使用本地目录。也就是使用的是Linux的目录,一定确保下面目录
的权限所属为你创建的用户。并且这里面我也要会变通,aboutyun,为我创建的用户名,如果你创建了zhangsan或则lisi,那么这个目录就会变为
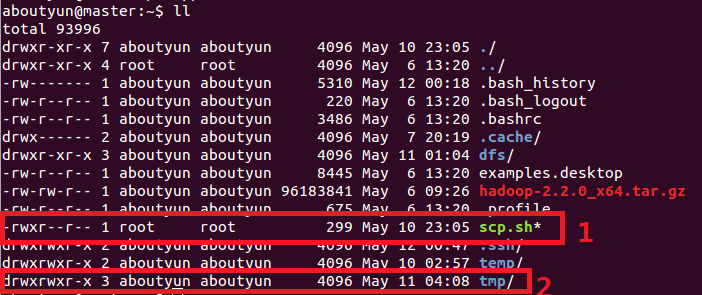
这里不熟悉,是因为对Linux的不熟悉的原因。这里在来张图:
注意:1和2对比。如果你所创建的tmp属于root,那么你会看不到进程。
 hdfs-site.xml
同样也是:要注意下面,你是需要改成自己的用户名的
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/aboutyun/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/aboutyun/dfs/data</value>
</property>
上面讲完,我们开始配置
hadoop集群中每个机器上面的配置基本相同,所以我们先在master上面进行配置部署,然后再复制到其他节点。所以这里的安装过程相当于在每台机器上面都要执行。
【注意】:master和slaves安装的hadoop路径要完全一样,用户和组也要完全一致
1、 解压文件
将第一部分中下载的
解压到/usr路径下
并且重命名,效果如下

2、 hadoop配置过程
配置之前,需要在master本地文件系统创建以下文件夹:
~/dfs/name
~/dfs/data
~/tmp
这里文件权限:创建完毕,你会看到红线部分,注意所属用户及用户组。如果不再新建的用户组下面,可以使用下面命令来修改:让你真正了解chmod和chown命令的用法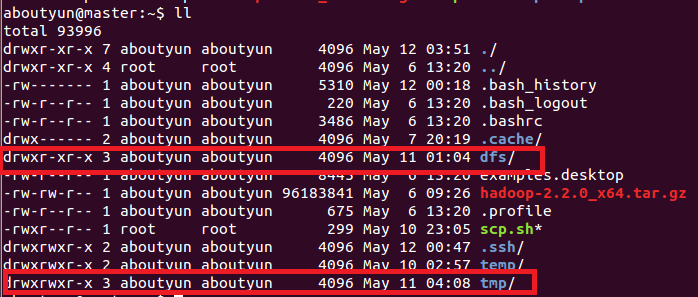
这里要涉及到的配置文件有7个:
~/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
~/hadoop-2.2.0/etc/hadoop/yarn-env.sh
~/hadoop-2.2.0/etc/hadoop/slaves
~/hadoop-2.2.0/etc/hadoop/core-site.xml
~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
以上文件默认不存在的,可以复制相应的template文件获得。下面举例:

配置文件1:hadoop-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/jdk1.7)
配置文件2:yarn-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/jdk1.7)
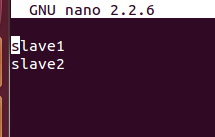
配置文件3:slaves (这个文件里面保存所有slave节点)
写入以下内容:
配置文件4:core-site.xml
配置文件5:hdfs-site.xml
配置文件6:mapred-site.xml
配置文件7:yarn-site.xml
3、复制到其他节点
上面配置完毕,我们基本上完成了90%了剩下就是复制。我们可以把整个hadoop复制过去:使用如下命令:
这里记得先复制到home/aboutyun下面,然后在转移到/usr下面。
后面我们会经常遇到问题,经常修改配置文件,所以修改完一个配置文件后,其他节点都需要修改,这里附上脚本操作方便:
4.配置环境变量
第一步:
第二步:添加如下内容:记得如果你的路径改变了,你也许需要做相应的改变。

4、启动验证
4.1 启动hadoop
格式化namenode:
或则使用下面命令:
启动hdfs:
此时在master上面运行的进程有:
namenodesecondarynamenode
slave节点上面运行的进程有:datanode
启动yarn:
我们看到如下效果:
master有如下进程:
 slave1有如下进程 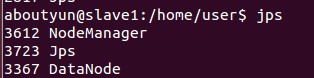
此时hadoop集群已全部配置完成!!!
【注意】:而且所有的配置文件<name>和<value>节点处不要有空格,否则会报错!
然后我们输入:(这里有的同学没有配置hosts,所以输出master访问不到,如果访问不到输入ip地址即可)
如何修改hosts: win7 进入下面路径: 找打hosts  然后打开,进行如下配置即可看到  看到下图: 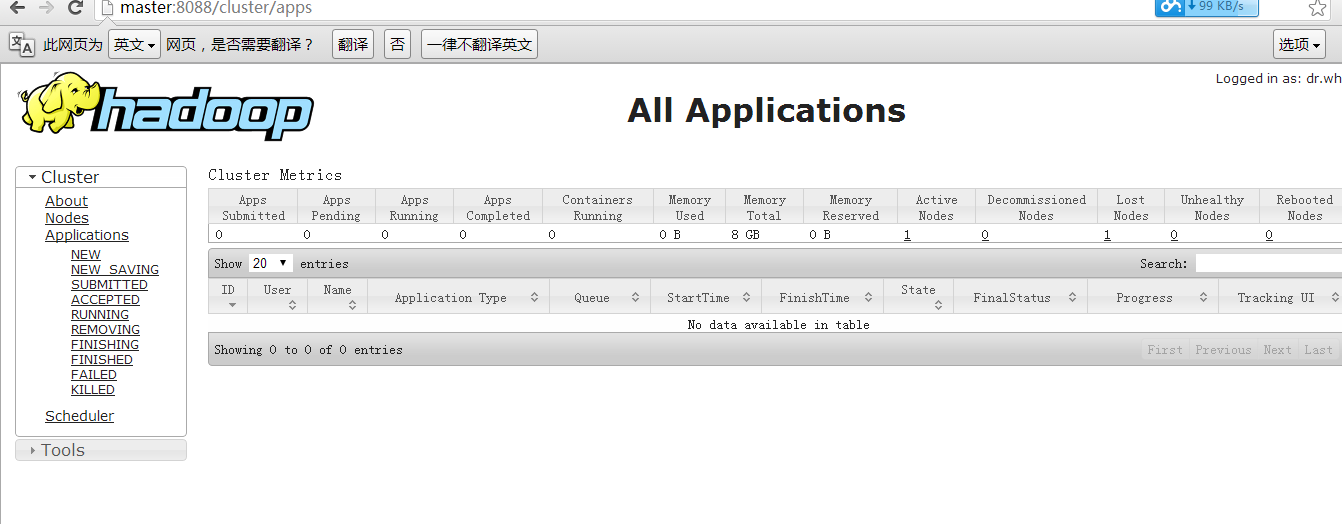 到此全部完毕。 (责任编辑:IT) |