|
0. 服务说明 NameNode NameNode是HDFS的守护程序,负责记录文件是如何分割成数据块的,以及这些数据块被存储到哪些数据节点上。它的功能是对内存及I/O进行集中管理。 DataNode 集群中每个从服务器都运行一个DataNode后台程序,后台程序负责把HDFS数据块读写到本地文件系统。需要读写数据时,由NameNode告诉客户端去哪个DataNode进行具体的读写操作。 Secondary NameNode Secondary NameNode是一个用来监控HDFS状态的辅助后台程序,如果NameNode发生问题,可以使用Secondary NameNode作为备用的NameNode。 JobTracker JobTracker后台程序用来连接应用程序与Hadoop,用户应用提交到集群后,由JobTracker决定哪个文件处理哪个task执行,一旦某个task失败,JobTracker会自动开启这个task。 TaskTracker TaskTracker负责存储数据的DataNode相结合,位于从节点,负责各自的task。
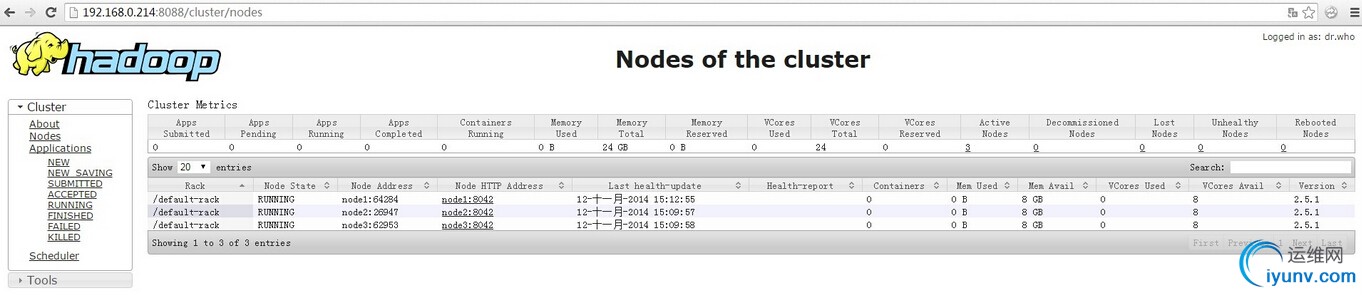
192.168.0.214 master 192.168.0.215 node1 192.168.0.217 node2 192.168.0.218 node3 系统: CentOS 7 x64 2. 安装前准备 修改所有机器的hosts 以及 hostname vi /etc/hosts 添加 192.168.0.214 master 192.168.0.215 node1 192.168.0.217 node2 192.168.0.218 node3 echo "hostname master" >> /etc/sysconfig/network 修改hostname 3. ssh 各机器无密码登陆 ssh-keygen -t rsa cd /root/.ssh/ cat id_rsa.pub >> authorized_keys chmod 600 authorized_keys 将所有机器的 id_rsa.pub 导入到 authorized_keys 中 上传到各服务器中 所有机器创建 hadoop 用户 并设置 hadoop 用户各机器无密码登陆 useradd hadoop 切换到hadoop 用户 并生成 密钥 su hadoop ssh-keygen -t rsa cd /home/hadoop/.ssh/ cat id_rsa.pub >> authorized_keys chmod 600 authorized_keys reboot 重启机器使所有准备工作生效 4. 安装jdk jdk-6u45-linux-x64-rpm.bin chmod 777 jdk-6u37-linux-x64-rpm.bin ./jdk-6u37-linux-x64-rpm.bin 安装完成以后...安装目录为 /usr/java/jdk1.6.0_45/ 接下来配置一下JDK的环境.. vi /etc/profile 在最下面增加下面三行: export JAVA_HOME=/usr/java/jdk1.6.0_45/ export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH export LASSPATH=.:/usr/java/jdk1.6.0_45/lib:/usr/java/jdk1.6.0_45/jre/lib:$CLASSPATH 使设置生效: source /etc/profile java -version 5. 安装hadoop 查找最新版本 http://apache.fayea.com/apache-mirror/hadoop/common hadoop-2.5.1.tar.gz tar zxvf hadoop-2.5.1.tar.gz -C /opt/ cd /opt/ mv hadoop-2.5.1/ hadoop chown -R hadoop:hadoop hadoop/ 在master 创建 文件夹 mkdir -p /opt/hadoop/dfs/name mkdir -p /opt/hadoop/dfs/data mkdir -p /opt/hadoop/dfs/tmp 修改hadoop 配置文件 cd /opt/hadoop/etc/hadoop mv mapred-site.xml.template mapred-site.xml 修改 hadoop-env.sh vi hadoop-env.sh 修改JAVA_HOME值 export JAVA_HOME=${JAVA_HOME} 修改为 export JAVA_HOME=/usr/java/jdk1.6.0_45 修改 yarn-env.sh vi yarn-env.sh 修改JAVA_HOME值 # export JAVA_HOME=/home/y/libexec/jdk1.6.0/ 修改为 export JAVA_HOME=/usr/java/jdk1.6.0_45 修改 slaves vi slaves 添加所有节点 node1 node2 node3 修改 core-site.xml vi core-site.xml 在 <configuration> </configuration> 中间增加如下配置 <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/opt/hadoop/dfs/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> </configuration> 修改hdfs-site.xml vi hdfs-site.xml 在 <configuration> </configuration> 中间增加如下配置 <configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/opt/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/opt/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration> 修改 mapred-site.xml vi mapred-site.xml 在 <configuration> </configuration> 中间增加如下配置 <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration> 修改 yarn-site.xml vi yarn-site.xml 在 <configuration> </configuration> 中间增加如下配置 <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> </configuration> 所有配置完毕以后,将 hadoop 整个目录 全部复制到其他的节点中 scp -r hadoop node1:/opt/ chown -R hadoop:hadoop hadoop/ 初始化并启动hadoop hdfs namenode -format 在master启动hdfs 会自动连接到其他节点启动 /opt/hadoop/sbin/start-dfs.sh 输入jps 可查看启动的进程 [root@master ~]# jps 2614 Jps 2007 NameNode 2183 SecondaryNameNode [root@node1 ~]# jps 2004 Jps 1932 DataNode 在master启动yarn 会自动连接到其他节点启动 启动yarn /opt/hadoop/sbin/start-yarn.sh [root@master ~]# jps 2614 Jps 2007 NameNode 2347 ResourceManager 2183 SecondaryNameNode [root@node1 ~]# jps 2144 Jps 2039 NodeManager 1932 DataNode 至此 hadoop 群集已经配置完成 浏览器访问 http://192.168.0.214:8088/ 查看群集情况 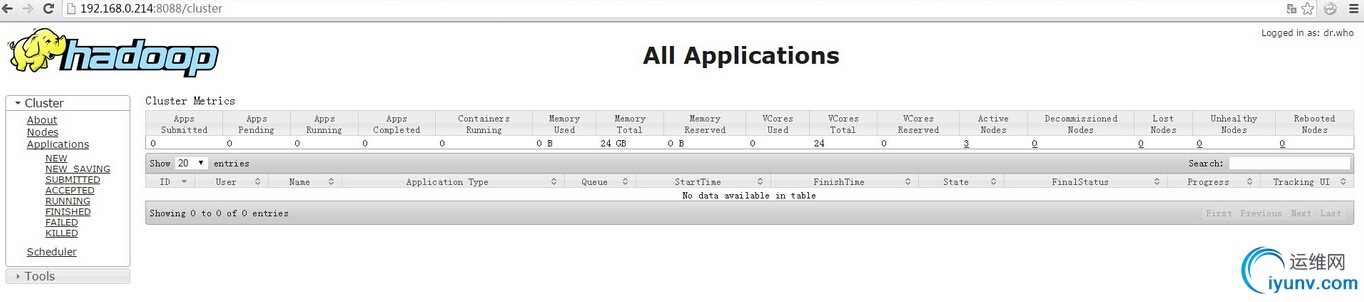
 (责任编辑:IT) |