|
1.HDFS的设计 HDFS设计的适合对象:超大文件(TB级别的文件)、流式数据访问(一次写入,多次读取)、商用硬件(廉价硬件) HDFS设计不适合的对象:低时间延迟的数据访问、大量的小文件、多用户写入,任意修改文件
2.HDFS的概念 1).数据块(Block) HDFS中Block的大小默认是64M,小于块大小的的文件并不占据整个块的全部空间(而是将文件大小作为块的大小.比如要存放的文件是1k,但是系统的Block默认是64MB,存放之后块的大小是1k,不是64MB.文件若是大于64MB,则分多快进行存储.) 使用Blocks的好处:
2)NameNode和DataNode HDFS 提供了两类节点
另外Client端代表用户通过NameNode和DataNode交互来访问整个文件系统 没有NameNode,文件系统将无法使用,所以提供两种对NameNode实现容错机制:
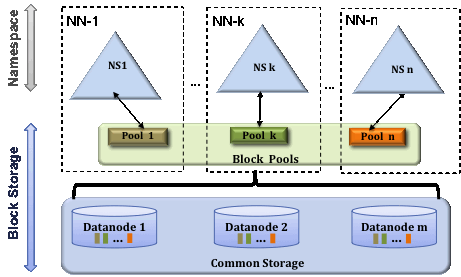
3).HDFS Federation
如下如所示:
4).Hadoop高可用性 Hadoop2.0.0版式本中,提供了一种机制可以使处于备用状态的Namenode中的数据与处于活动状态的Namenode中的数据同步,这种机制的实现必须需要这两个NameNode可访问在一个共享存储设备(比如:来自NAS上的NFS)上的目录。 1).当namespace被处于活动状态的NameNode修改时,这个修改操作被持久化的写入到共享目录里的一个编辑日志文件里,处于备用状态的NameNode不断的查看这个共享目录中的编辑日志文件,发现这个编辑日志文件有变化,就把它们拷贝到自己的namespace里。 2).活动状态的NameNode崩溃时,备用状态的NameNode代替崩溃的NameNode成为处于活动状态的NameNdoe,而在此之前处于备用状态的NameNode会确保它从共享目录中全部读取了编辑日志中的记录,这样就确保了在失效备援以前这两个NameNode中的namespace是完全同步的。 3).为提供快速的失效备援, 需要处于备份状态的NameNode结点有集群中块位置的最新信息,为了实现这一点,处于这两个NameNode管理的所有DataNodes,都需要向这两个NameNode发送块信息和心跳信息。 4).对正确操作高可用性的集群而言,至关重要的一点,是在任何时刻这两个NameNode只参有一个NameNode处于活动状态,否则namespace将会处于不一致状态,这将会导致数据丢失或其他不可知结果。
3.命令行接口 基本命令: 1).将本地数据拷贝:
2).将数据从hdfs上拷贝到本地硬盘并检查文件时候一致
3).HDFS文件列表 % hadoop fs -mkdir books % hadoop fs -ls .
结果当中各列分别表示: 文件模式、文件被复制的份数、文件拥有者、文件拥有者的group、文件大小,目录显示为0、、文件最后修改日期、文件最后修改时间、文件的绝对路径
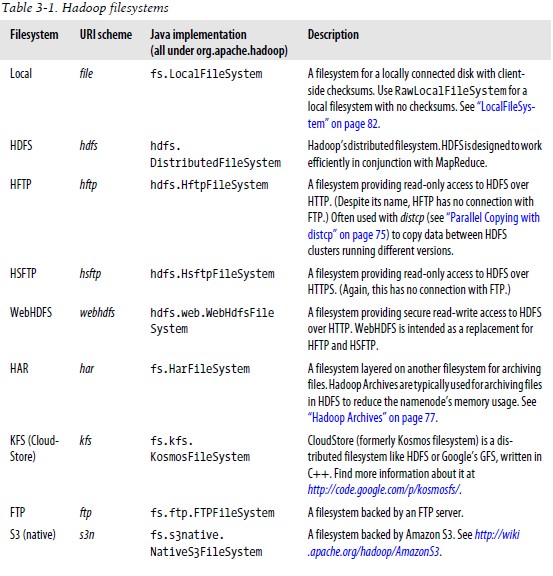
4.Hadoop文件系统 Hadoop有一个对文件系统的抽象,HDFS只是其中的一个实现。Java的抽象类org.apache.hadoop.fs.FileSystem代表了Hadoop中的文件系统,还有其他的几种实现(P48)
接口: Hadoop用Java写成,所有Hadoop文件的交互都通过Java api来完成。还有另外的与Hadoop文件系统交互的库:Thrift、C、FUSE、WebDAV等
5.Java接口 1).从Hadoop URL中读取数据 使用java.net.URL对象打开数据流,进而从中读取数据:
InputStream in = null;
try { in = new URL("hdfs://host/path").openStream(); // process in } finally { IOUtils.closeStream(in); } }
代码示例: 下面展示了程序以标准输出方式显示Hadoop文件系统中的文件,这里采用的方法通过FsUrlStreamHandlerFactory实例调用URL中的setURLStreamHandlerFactory方法,这个操作对一个jvm只能使用一次,我们可以在静态块中调用。
public class URLCat {
public static void main(String[] args) throws Exception {
2).通过FileSystem API读取数据 FileSystem是一个通用文件系统API,其中其对象的open方法返回的是FSDataInputStream对象,此对象支持随机访问。 Configuration对象封装了客户端或服务器的配置,通过设置配置文件读取类路径来实现 public class FileSystemCat {public static void main(String[] args) throws Exception { String uri = args[0]; Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create(uri), conf); InputStream in = null; try { in = fs.open(new Path(uri)); IOUtils.copyBytes(in, System.out, 4096, false); } finally { IOUtils.closeStream(in); } } } 运行结果:
Seekable接口支持在文件中找到指定位置,其中seek()可以移到文件中任意一个绝对位置,skip()则只能相对于当前位置定位到另一个新位置,seek()是一个方法是一个相对高开销的操作,需要慎重使用。
public interface Seekable {
void seek(long pos) throws IOException; long getPos() throws IOException; }public class FileSystemDoubleCat { public static void main(String[] args) throws Exception { String uri = args[0]; Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create(uri), conf); FSDataInputStream in = null; try { in = fs.open(new Path(uri)); IOUtils.copyBytes(in, System.out, 4096, false); in.seek(0); // go back to the start of the file IOUtils.copyBytes(in, System.out, 4096, false); } finally { IOUtils.closeStream(in); } } }
运行结果:
在下面代码中,read()方法最多读取length bytes。Position是相对offset的偏移,buffer存放读取的数据。readFully()方法读取length bytes的数据到buffer中,第二个readFully则是读取buffer.length bytes的数据到buffer中。以下的方法均不会改变offset的值。
public interface PositionedReadable {
public void readFully(long position, byte[] buffer, int offset, int length)
public void readFully(long position, byte[] buffer) throws IOException;
3).写入数据 FileSystem类创建文件的方法create 参数为指定的一个Path对象 public FSDataOutputStream create(Path f) throws IOException;
package org.apache.hadoop.util;
public interface Progressable {
public void progress(); }
新建文件方法append(),在一个已有的文件末尾追加数据 public FSDataOutputStream append(Path f) throws IOException;
程序实例:将本地文件复制到Hadoop文件系统 public class FileCopyWithProgress {public static void main(String[] args) throws Exception { String localSrc = args[0]; String dst = args[1]; InputStream in = new BufferedInputStream(new FileInputStream(localSrc)); Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create(dst), conf); OutputStream out = fs.create(new Path(dst), new Progressable() { public void progress() { System.out.print("."); } }); IOUtils.copyBytes(in, out, 4096, true); } } 执行结果:
package org.apache.hadoop.fs;
public class FSDataOutputStream extends DataOutputStream implements Syncable { 4).目录 创建目录方法mkdir()方法,如果目录创建成功返回true public boolean mkdirs(Path f) throws IOException;
5).查询文件系统 文件元数据:FileStatus,FileSystem的getFilesStatus()方法用于获取文件或目录的FileStatus对象
示例代码:
public class ListStatus { public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path[] paths = new Path[args.length]; for (int i = 0; i < paths.length; i++) {
paths[i] = new Path(args[i]);
}
FileStatus[] status = fs.listStatus(paths);
Path[] listedPaths = FileUtil.stat2Paths(status); for (Path p : listedPaths) {
System.out.println(p);
}
}
}
执行结果:
文件模式,为了处理一批文件,Hadoop提供了"通配操作",并提供了globStatus()方法,其返回与路径相匹配的所有文件的FileStatus对象数组,并按照路径排序 public FileStatus[] globStatus(Path pathPattern) throws IOException; public FileStatus[] globStatus(Path pathPattern, PathFilter filter) throws OException; 下面列出通配及其含义:
PathFilter对象,为了弥补通配符不够准确的功能,Hadoop的FileSystem在listStatus()和globStatus()提供了可选的PathFilter对象,使我们能够通过编程方式控制通配符
package org.apache.hadoop.fs; public interface PathFilter { boolean accept(Path path);
}
程序实例:用于排除匹配正则表达式路径的PathFilter
public class RegexExcludePathFilter implements PathFilter {
public RegexExcludePathFilter(String regex) {
public boolean accept(Path path) { 过滤方法调用:
fs.globStatus(new Path("/2007/*/*"), new RegexExcludeFilter("^.*/2007/12/31$"));
6).删除数据 使用FileSystem的delete()方法可以永久删除文件或目录,其中如果f是一个文件或者空目录recursive的值就会被忽略。当一个目录不为空的时候:recursive为true时,目录将连同内部的内容都会被删除,否则抛出IOException异常。 public boolean delete(Path f, boolean recursive) throws IOException;
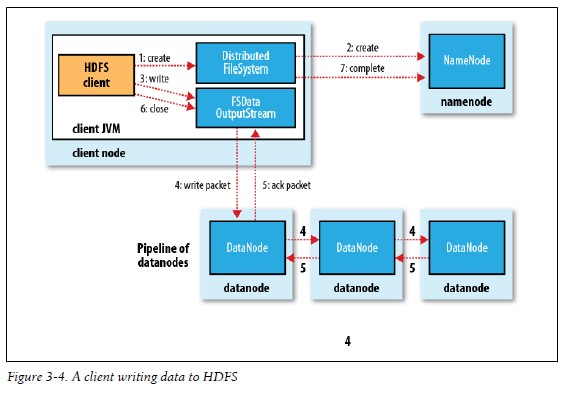
6.数据流 1).文件读取剖析 下图显示了在读取文件时一些事件的主要顺序:
步骤如下
关于容错处理问题: 在读取期间,如果client与datanode通信的时候如果发生错误的话,它会尝试读取下个紧接着的含有那个block的datanode。Client会记住发生错误datanode,这样它就不必在读取以后的块的时候再尝试这个datanode了。Client也验证从datanode传递过来的数据的checksum。如果错误的block被发现,它将在尝试从另一个datanode读取数据前把这个信息报告给namenode。 这个设计的一个重要方面是:客户端联系datanodes直接接收数据,并且客户端被namenode导向包含每块数据的最佳datanode。这样的设计可以使HDFS扩展而适应大量的客户端,因为数据传输线路是通过集群中的所有datanode的,namenode只需要相应块的位置查询服务即可(而namenode是将块的位置信息存放在内存中的,这样效率就非常高),namenode不需要提供数据服务,因为数据服务随着客户端的增加将很快成为瓶颈。
关于网络拓扑与Hadoop Hadoop计算路径是按照如下方式进行的:
下面是一个例子:
2).文件写入剖析 下图显示了在写入文件时一些事件的主要顺序:
关于写入数据的时候datanode发生错误的处理 发现错误之后,首先关闭流水线,然后将没有被确认的数据放到数据队列的开头,当前的块被赋予一个新的标识,这信息将发给namenode,以便在损坏的数据节点恢复之后删除这个没有被完成的块。然后从流水线中移除损坏的datanode。之后将这个块剩下的数据写入到剩下的两个节点中。Namenode注意到这个块的信息还没有被复制完成,他就在其他一个datanode上安排复制。接下来的block写入操作就和往常一样了。 尽管可能在写入数据的时候多个节点都出现故障,但是只要默认的一个节点(dfs.replication.min)被写入了,那么这个操作就会完成。因为数据块将会在集群间复制,直到复制完定义好的次数(dfs.replication,默认3份)
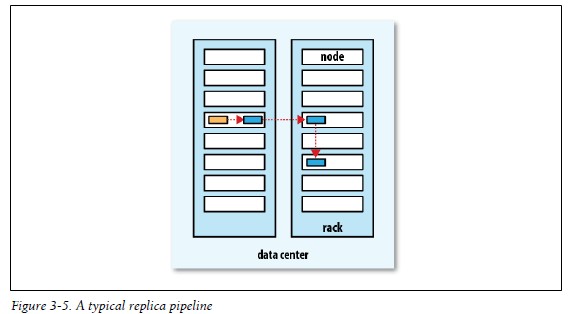
关于副本的布局
如下图:
3).一致模型 文件系统的一致性模型描述了读写文件过程中的数据可见性。HDFS去掉了一些POSIX对性能的要求,所以一些操作可能与你的预想不大一致 A.在文件被创建之后,希望它在文件系统的名字空间中是可见的
Path p = new Path("p");
fs.create(p);
assertThat(fs.exists(p), is(true));
Path p = new Path("p");
OutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.flush();
assertThat(fs.getFileStatus(p).getLen(), is(0L));
C.当超过一个block的数据被写入之后,第一个block对reader将是可见的,接下来的也是一样:当前正在写的block总是不可见的,已经被写入的block是可见的
D.HDFS通过FSDataOutputStream的sync()方法提供了一种强制使所有buffer同步到datanode方法。当sync()成功返回之后,HDFS保证sync之前的数据被持久化并且对所有reader可见。下面操作有点像unix系统的fsync系统调用,该调用提供一个文件描述符的缓冲数据。
Path p = new Path("p");
FSDataOutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.flush();
out.sync();
assertThat(fs.getFileStatus(p).getLen(), is(((long) "content".length())));
同步之后看到具体文件内容:
FileOutputStream out = new FileOutputStream(localFile);
out.write("content".getBytes("UTF-8"));
out.flush(); // flush to operating system out.getFD().sync(); // sync to disk assertThat(localFile.length(), is(((long) "content".length())));
E.在HDFS文件关闭文件还隐藏着执行sync()方法
Path p = new Path("p");
OutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.close();
assertThat(fs.getFileStatus(p).getLen(), is(((long) "content".length())));
7.通过distcp并行复制 Hadoop提供了一个非常有用的工具——distcp,来在Hadoop文件系统之间拷贝大量数据。 1).distcp的一个典型用途就是在两个HDFS集群之间传递数据。如果两个集群运行着相同版本的Hadoop,就非常适合使用hdfs方案: % hadoop distcp hdfs://namenode1/foo hdfs://namenode2/bar
2).使用-overwrite或者-update选项改变了以前源路径和目标路径的使用方式 % hadoop distcp -update hdfs://namenode1/foo hdfs://namenode2/bar/foo
3).如果想在运行不同版本的HDFS集群之间拷贝使用HDFS协议运行distcp的话会产生错误。因为不同系统的RPC系统不兼容。为了补救,可以使用基于HTTP协议的HFTP从源文件中读取数据。但job就必须在拷贝的目标机器上运行,以便HDFS的rpc版本兼容。上面的例子可以写成下面的样子: % hadoop distcp hftp://namenode1:50070/foo hdfs://namenode2/bar 注意:必须在uri中指定namenod的web端口号。这个端口的默认值是50070,由dfs.http.address属性值来决定。
4).保持HDFS集群的均衡 可以使用均衡器工具---balance命令
8.Hadoop存档 为了解决Hadoop存储小文件低效问题,Hadoop提供了Hadoop Archive(HAR)文件打包工具 HAR是使用archive工具打包一些文件创建的。Archive工具运行一个MapReduce job来并行处理输入文件。所以需要在一个运行MapReduce的集群上使用它。
运行archive命令:
运行上述命令之后,产生的.har文件信息如下:
上面的结果显示了HAR文件的组成部分:两个索引文件以及部分文件的集合,对本例来说part文件只有一个。Part文件包含了原始文件的内容,index用来索引这些数据。 下面的命令以递归的方式列出了存档文件中的部分文件
以下两个指令相同
删除HAR文件指令
HAR的不足: 1).创建的是归档文件,没有压缩功能,所以不会节省空间 2).归档文件创建之后不能被修改,若要添加、删除文件的话,需要重新建立归档文件
3).虽然HAR文件可以作为MapReduce的输入,但是InputFormat不支持将多个文件打包到一个MapReduce split中。所以处理大量的小文件,即使是在har文件中,都将是低效的。 |