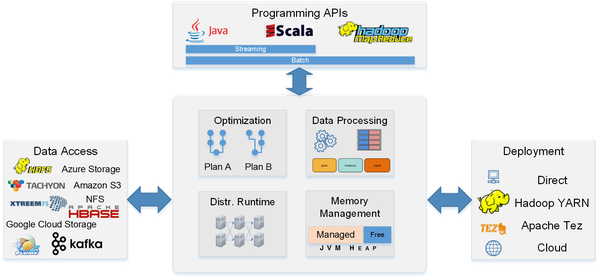
提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x 进化到目前的2.6版本。我把2012年后定义成后Hadoop平台时代,这不是说不用Hadoop,而是像NoSQL (Not Only SQL)那样,有其他的选型补充。我在知乎上也写过Hadoop的一些入门文章 如何学习Hadoop - 董飞的回答,为了给大家有个铺垫,简单讲一些相关开源组件。 背景篇
原理篇数据存储
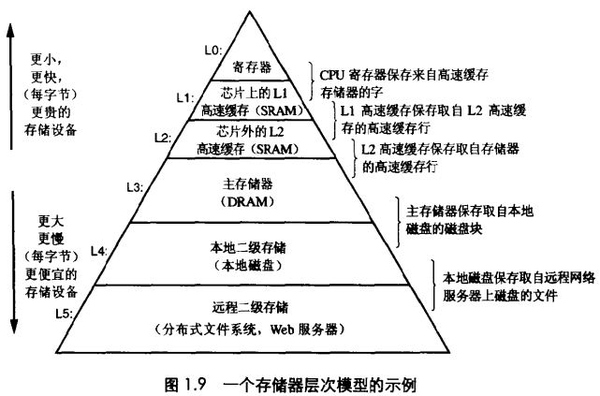
我们的目标是做一个可靠的,支持大规模扩展和容易维护的系统。计算机里面有个locality(局部性定律),如图所示。从下到上访问速度越来越快,但存储代价更大。 相对内存,磁盘和SSD就需要考虑数据的摆放, 因为性能会差异很大。磁盘好处是持久化,单位成本便宜,容易备份。但随着内存便宜,很多数据集合可以考虑直接放入内存并分布到各机器上,有些基于 key-value, Memcached用在缓存上。内存的持久化可以通过 (带电池的RAM),提前写入日志再定期做Snapshot或者在其他机器内存中复制。当重启时需要从磁盘或网络载入之前状态。其实写入磁盘就用在追加日 志上面 ,读的话就直接从内存。像VoltDB, MemSQL,RAMCloud 关系型又基于内存数据库,可以提供高性能,解决之前磁盘管理的麻烦。
HyperLogLog & Bloom Filter & CountMin Sketch 都是是应用于大数据的算法,大致思路是用一组相互独立的哈希函数依次处理输入。HyperLogLog 用来计算一个很大集合的基数(即合理总共有多少不相同的元素),对哈希值分块计数:对高位统计有多少连续的0;用低位的值当做数据块。 BloomFilter,在预处理阶段对输入算出所有哈希函数的值并做出标记。当查找一个特定的输入是否出现过,只需查找这一系列的哈希函数对应值上有没 有标记。对于BloomFilter,可能有False Positive,但不可能有False Negative。BloomFilter可看做查找一个数据有或者没有的数据结构(数据的频率是否大于1)。CountMin Sketch在BloomFilter的基础上更进一步,它可用来估算某一个输入的频率(不局限于大于1)。 CAP Theorem
技术篇
来自:http://thinkbig.teradata.com/leading_big_data_technologies/big-data-reference-architecture/ 根据不同的延迟要求(SLA),数据量存储大小, 更新量多少,分析需求,大数据处理的架构也需要做灵活的设计。上图就描述了在不同领域中大数据组件。 说大数据的技术还是要先提Google,Google 新三辆马车,Spanner, F1, Dremel Spanner:高可扩展、多版本、全球分布式外加同步复制特性的谷歌内部数据库,支持外部一致性的分布式事务;设计目标是横跨全球上百个数据中心,覆盖百万台服务器,包含万亿条行记录!(Google就是这么霸气^-^) F1: 构建于Spanner之上,在利用Spanner的丰富特性基础之上,还提供分布式SQL、事务一致性的二级索引等功能,在AdWords广告业务上成功代替了之前老旧的手工MySQL Shard方案。 Dremel: 一种用来分析信息的方法,它可以在数以千计的服务器上运行,类似使用SQL语言,能以极快的速度处理网络规模的海量数据(PB数量级),只需几秒钟时间就能完成。 Spark
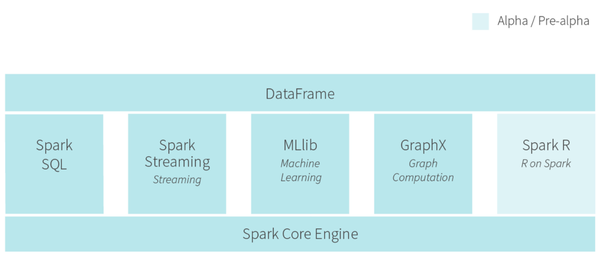
2014年最火的大数据技术Spark,有什么关于 Spark 的书推荐? - 董飞的回答 做了介绍。主要意图是基于内存计算做更快的数据分析。同时支持图计算,流式计算和批处理。Berkeley AMP Lab的核心成员出来成立公司Databricks开发Cloud产品。 Flink
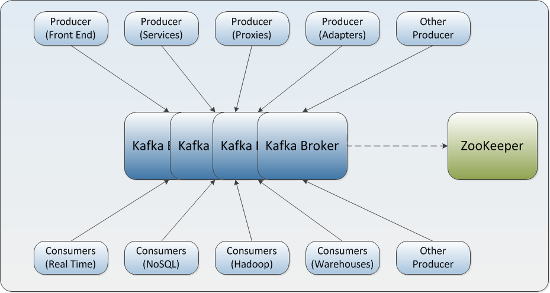
Kafka
Announcing the Confluent Platform 1.0 Kafka 描述为 LinkedIn 的“中枢神经系统”,管理从各个应用程序汇聚到此的信息流,这些数据经过处理后再被分发到各处。不同于传统的企业信息列队系统,Kafka 是以近乎实时的方式处理流经一个公司的所有数据,目前已经为 LinkedIn, Netflix, Uber 和 Verizon 建立了实时信息处理平台。Kafka 的优势就在于近乎实时性。 Storm
Samza
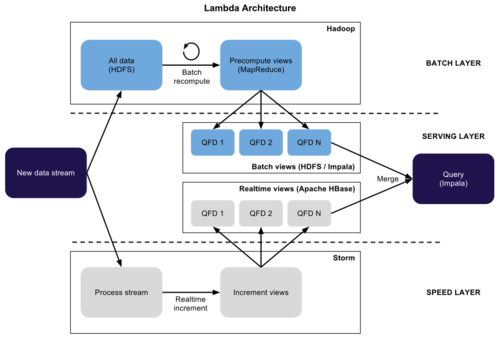
LinkedIn主推的流式计算框架。与其他类似的Spark,Storm做了几个比较。跟Kafka集成良好,作为主要的存储节点和中介。 Lambda architecture Nathan写了文章《如何去打败CAP理论》How to beat the CAP theorem,提出Lambda Architecture,主要思想是对一些延迟高但数据量大的还是采用批处理架构,但对于即时性实时数据使用流式处理框架,然后在之上搭建一个服务层去合并两边的数据流,这种系统能够平衡实时的高效和批处理的Scale,看了觉得脑洞大开,确实很有效,被很多公司采用在生产系统中。
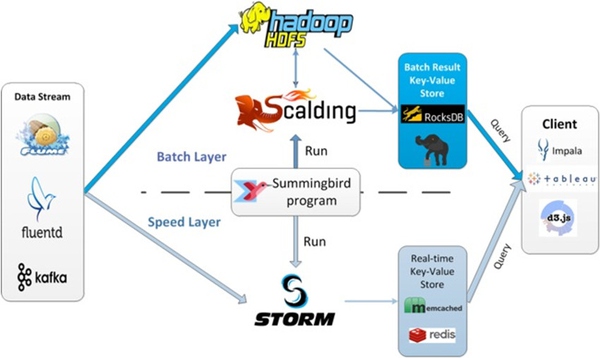
Lambda架构的问题要维护两套系统,Twitter开发了Summingbird来做到一次编程,多处运行。将批处理和流处理无缝连接,通过整合批处理与流处理来减少它们之间的转换开销。下图就解释了系统运行时。
NoSQL 数据传统上是用树形结构存储(层次结构),但很难表示多对多的关系,关系型数据库就是解决这个难题,最近几年发现关系型数据库也不灵了,新型NoSQL出现 如Cassandra,MongoDB,Couchbase。NoSQL 里面也分成这几类,文档型,图运算型,列存储,key-value型,不同系统解决不同问题。没一个one-size-fits-all 的方案。
Cassandra 大数据架构中,Cassandra的主要作用就是存储结构化数据。DataStax的Cassandra是一种面向列的数据库,它通过分布式架构提供高可用性及耐用性的服务。它实现了超大规模的集群,并提供一种称作“最终一致性”的一致性类型,这意味着在任何时刻,在不同服务器中的相同数据库条目可以有不同的值。 SQL on Hadoop 开源社区业出现了很多 SQL-on-Hadoop的项目,着眼跟一些商业的数据仓库系统竞争。包括Apache Hive, Spark SQL, Cloudera Impala, Hortonworks Stinger, Facebook Presto, Apache Tajo,Apache Drill。有些是基于Google Dremel设计。 Impala Cloudera公司主导开发的新型查询系统,它提供SQL语义,能够查询存储在Hadoop的HDFS和HBase中的PB级大数据,号称比Hive快5-10倍,但最近被Spark的风头给罩住了,大家还是更倾向于后者。 Drill Apache社区类似于Dremel的开源版本—Drill。一个专为互动分析大型数据集的分布式系统。 Druid 在大数据集之上做实时统计分析而设计的开源数据存储。这个系统集合了一个面向列存储的层,一个分布式、shared-nothing的架构,和一个高级的索引结构,来达成在秒级以内对十亿行级别的表进行任意的探索分析。 Berkeley Data Analytics Stack
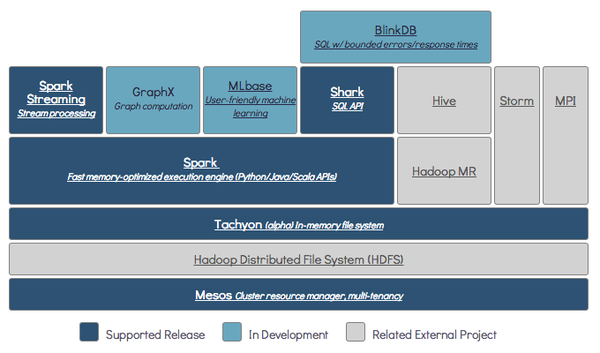
上面说道Spark,在Berkeley AMP lab 中有个更宏伟的蓝图,就是BDAS,里面有很多明星项目,除了Spark,还包括: Mesos:一个分布式环境的资源管理平台,它使得Hadoop、MPI、Spark作业在统一资源管理环境下执行。它对Hadoop2.0支持很好。Twitter,Coursera都在使用。 Tachyon:是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark和MapReduce那样。项目发起人李浩源说目前发展非常快,甚至比Spark当时还要惊人,已经成立创业公司Tachyon Nexus. BlinkDB:也很有意思,在海量数据上运行交互式 SQL 查询的大规模并行查询引擎。它允许用户通过权衡数据精度来提升查询响应时间,其数据的精度被控制在允许的误差范围内。 Cloudera
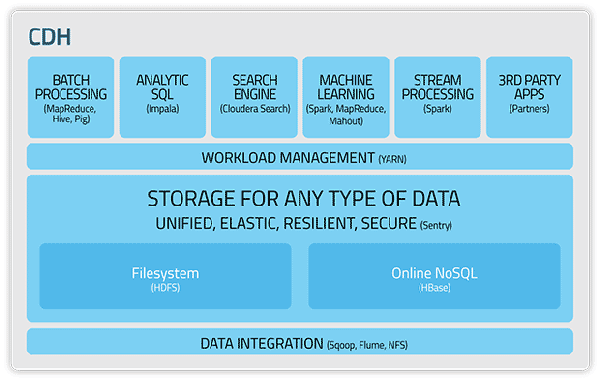
Hadoop老大哥提出的经典解决方案。 HDP (Hadoop Data Platform)
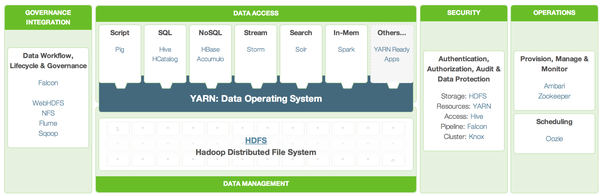
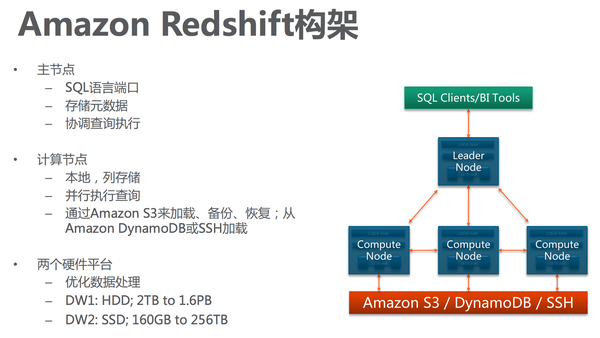
Hortonworks 提出的架构选型。 Redshift
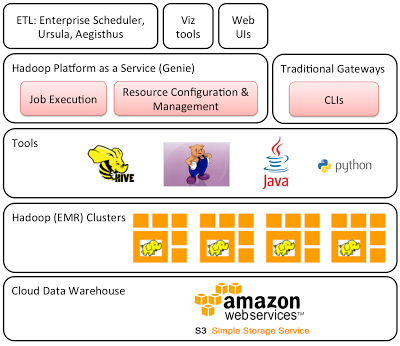
Netflix
完全基于AWS的数据处理解决方案。 Intel
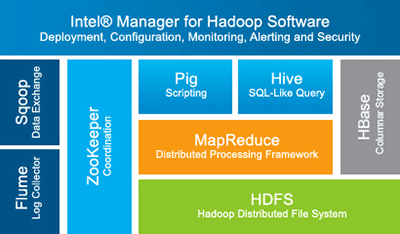
参考链接The Hadoop Ecosystem Table How to beat the CAP theorem Lambda Architecture Questioning the Lambda Architecture (责任编辑:IT) |
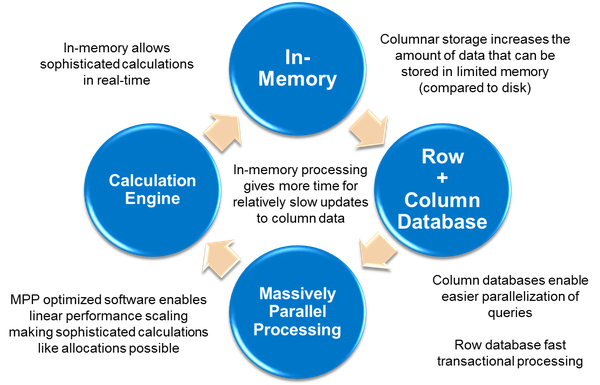
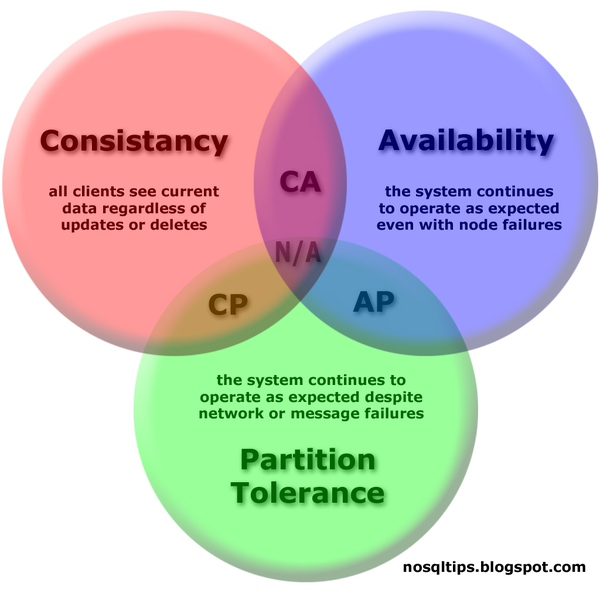 简单说是三个特性:一致性,可用性和网络分区,最多只能取其二。设计不同类型系统要多去权衡。分布式系统还有很多算法和高深理论,比如:Paxos算法(paxos分布式一致性算法--讲述诸葛亮的反穿越),Gossip协议(Cassandra学习笔记之Gossip协议),Quorum (分布式系统),时间逻辑,向量时钟(一致性算法之四: 时间戳和向量图),拜占庭将军问题,二阶段提交等,需要耐心研究。
简单说是三个特性:一致性,可用性和网络分区,最多只能取其二。设计不同类型系统要多去权衡。分布式系统还有很多算法和高深理论,比如:Paxos算法(paxos分布式一致性算法--讲述诸葛亮的反穿越),Gossip协议(Cassandra学习笔记之Gossip协议),Quorum (分布式系统),时间逻辑,向量时钟(一致性算法之四: 时间戳和向量图),拜占庭将军问题,二阶段提交等,需要耐心研究。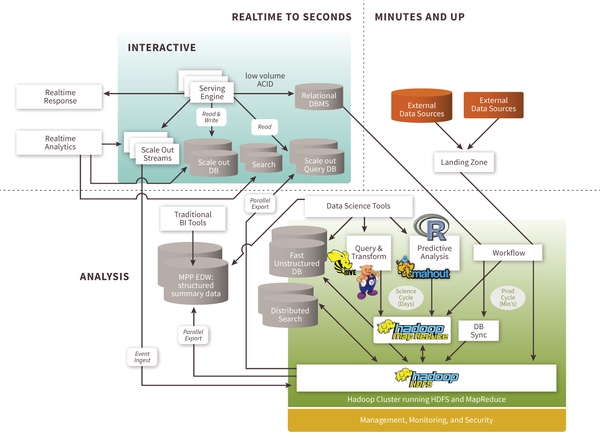
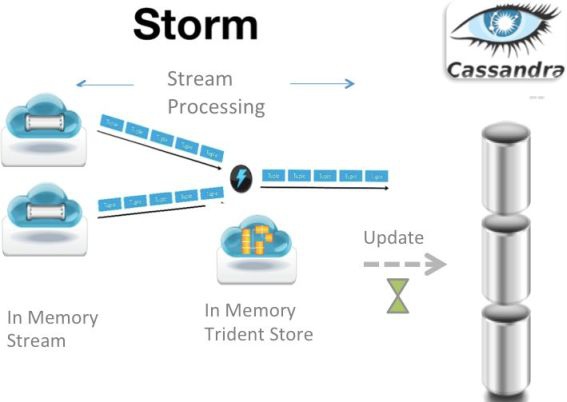 Handle Five Billion Sessions a Day in Real Time,Twitter的实时计算框架。所谓流处理框架,就是一种分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易。经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域。
Handle Five Billion Sessions a Day in Real Time,Twitter的实时计算框架。所谓流处理框架,就是一种分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易。经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域。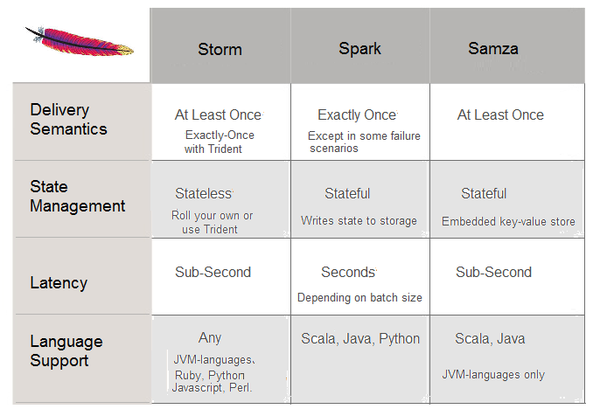
 Summingbird
Summingbird