|
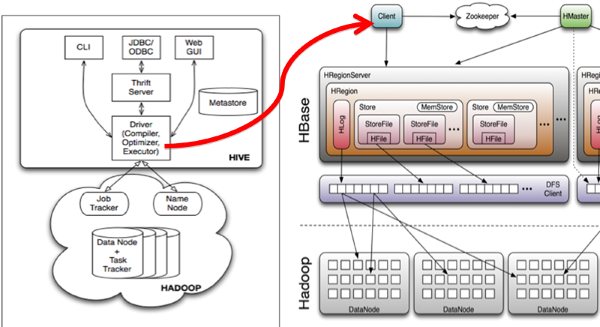
1. 简介 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。 Hive与HBase的整合功能的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive_hbase-handler.jar工具类, 大致意思如图所示:
2. Hive项目介绍
项目结构

Hive配置文件介绍
hive-env.sh 我们按数据元的存储方式不同安装。
3. 使用Derby数据库安装
什么是Derby安装方式
•Apache Derby是一个完全用java编写的数据库,所以可以跨平台,但需要在JVM中运行
•Derby是一个Open source的产品,基于Apache License 2.0分发
•即将元数据存储在Derby数据库中,也是Hive默认的安装方式
1 .Hadoop和Hbase都已经成功安装了Hadoop集群配置:http://blog.csdn.net/hguisu/article/details/723739 hbase安装配置:http://blog.csdn.net/hguisu/article/details/7244413 2. 下载hivehive目前最新的版本是0.12,我们先从http://mirror.bit.edu.cn/apache/hive/hive-0.12.0/ 上下载hive-0.12.0.tar.gz,但是请注意,此版本基于是基于hadoop1.3和hbase0.94的(如果安装hadoop2.X ,我们需要修改相应的内容) 3. 安装:tar zxvf hive-0.12.0.tar.gz cd hive-0.12.0
4. 替换jar包,与hbase0.96和hadoop2.2版本一致。
由于我们下载的hive是基于hadoop1.3和hbase0.94的,所以必须进行替换,因为我们的hbse0.96是基于hadoop2.2的,所以我们必须先解决hive的hadoop版本问题,目前我们从官网下载的hive都是用1.几的版本编译的,因此我们需要自己下载源码来用hadoop2.X的版本重新编译hive,这个过程也很简单,只需要如下步骤:
1. 先从http://svn.apache.org/repos/asf/hive/branches/branch-0.12 或者是http://svn.apache.org/repos/asf/hive/trunk 我们下载到/home/hadoop/branch-0.12下。
2. branch-0.12是使用ant编译,trunk下面是使用maven编译,如果未按照maven,需要从http://maven.apache.org/download.cgi 下载maven,或者使用yum install maven。然后解压出来并在PATH下把$maven_home/bin加入或者使用链接(ln -s /usr/local/bin/mvn $maven_home/bin ).然后就是使用mvn 命令。运行mvn -v就能知道maven是否配置成功
3. 配置好maven开始编译hive,我们cd到下载源码的branch-0.12 目录,然后运行mvn clean package -DskipTests -Phadoop-2开始编译
4.编译好后的新jar包是存放在各个模块下的target的,这些新jar包的名字都叫hive-***-0.13.0-SNAPSHOT.jar,***为hive下的模块名,我们需要运行命令将其拷贝到hive-0.12.0/lib下。
find /home/hadoop/branch-0.12 -name "hive*SNAPSHOT.jar"|xargs -i cp {} /home/hadoop/hive-0.12.0/lib。拷贝过去后我们比照着删除原lib下对应的0.12版本的jar包。
5. 接着我们同步hbase的版本,先cd到hive0.12.0/lib下,将hive-0.12.0/lib下hbase-0.94开头的那两个jar包删掉,然后从/home/hadoop/hbase-0.96.0-hadoop2/lib下hbase开头的包都拷贝过来
find /home/hadoop/hbase-0.96.0-hadoop/lib -name "hbase*.jar"|xargs -i cp {} ./
6. 基本的同步完成了,重点检查下zookeeper和protobuf的jar包是否和hbase保持一致,如果不一致,
拷贝protobuf.**.jar和zookeeper-3.4.5.jar到hive/lib下。
7.如果用mysql当原数据库,
别忘了找一个mysql的jdbcjar包mysql-connector-java-3.1.12-bin.jar也拷贝到hive-0.12.0/lib下
5. 配置hive
•进入hive-0.12/conf目录
•依据hive-env.sh.template,创建hive-env.sh文件
•cp hive-env.sh.template hive-env.sh
•修改hive-env.sh
•指定hive配置文件的路径
•export HIVE_CONF_DIR=/home/hadoop/hive-0.12/conf
•指定Hadoop路径
• HADOOP_HOME=/home/hadoop/hadoop-2.2.0
[html] view plaincopyprint?
 
hive-site.xml
[html] view plaincopyprint?
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- Hive Execution Parameters -->
<property>
<name>hive.exec.reducers.bytes.per.reducer</name>
<value>1000000000</value>
<description>size per reducer.The default is 1G, i.e if the input size is 10G, it will use 10 reducers.</description>
</property>
<property>
<name>hive.exec.reducers.max</name>
<value>999</value>
<description>max number of reducers will be used. If the one
specified in the configuration parameter mapred.reduce.tasks is
negative, hive will use this one as the max number of reducers when
automatically determine number of reducers.</description>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/hive/scratchdir</value>
<description>Scratch space for Hive jobs</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/tmp/${user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.PersistenceManagerFactoryClass</name>
<value>org.datanucleus.api.jdo.JDOPersistenceManagerFactory</value>
<description>class implementing the jdo persistence</description>
</property>
<property>
<name>javax.jdo.option.DetachAllOnCommit</name>
<value>true</value>
<description>detaches all objects from session so that they can be used after transaction is committed</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>APP</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>mine</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehousedir</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>
file:///home/hadoop/hive-0.12.0/lib/hive-ant-0.13.0-SNAPSHOT.jar,
file:///home/hadoop/hive-0.12.0/lib/protobuf-java-2.4.1.jar,
file:///home/hadoop/hive-0.12.0/lib/hbase-client-0.96.0-hadoop2.jar,
file:///home/hadoop/hive-0.12.0/lib/hbase-common-0.96.0-hadoop2.jar,
file:///home/hadoop/hive-0.12.0/lib/zookeeper-3.4.5.jar,
file:///home/hadoop/hive-0.12.0/lib/guava-11.0.2.jar
</value>
</property>
Hive使用Hadoop,这意味着你必须在PATH里面设置了hadoop路径,或者导出export HADOOP_HOME=<hadoop-install-dir>也可以。
另外,你必须在创建Hive库表前,在HDFS上创建/tmp和/hive/warehousedir(也称为hive.metastore.warehouse.dir的),并且将它们的权限设置为chmod g+w。完成这个操作的命令如下:
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp $ $HADOOP_HOME/bin/hadoop fs -mkdir /hive/warehousedir $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp $ $HADOOP_HOME/bin/hadoop fs -chmod g+w/hive/warehousedir 我同样发现设置HIVE_HOME是很重要的,但并非必须。 $ export HIVE_HOME=<hive-install-dir> 在Shell中使用Hive命令行(cli)模式: $ $HIVE_HOME/bin/hive 5. 启动hive1).单节点启动 #bin/hive -hiveconf hbase.master=master:490001 2) 集群启动: #bin/hive -hiveconf hbase.zookeeper.quorum=node1,node2,node3 如何hive-site.xml文件中没有配置hive.aux.jars.path,则可以按照如下方式启动。 bin/hive --auxpath /usr/local/hive/lib/hive-hbase-handler-0.96.0.jar, /usr/local/hive/lib/hbase-0.96.jar, /usr/local/hive/lib/zookeeper-3.3.2.jar -hiveconf hbase.zookeeper.quorum=node1,node2,node3 启动直接#bin/hive 也可以。6 测试hive
•建立测试表pokes
hive> CREATE TABLE pokes (foo INT, bar STRING);
OK Time taken: 1.842 seconds hive> show tables; OK pokes Time taken: 0.182 seconds, Fetched: 1 row(s)
•数据导入pokes
hive> LOAD DATA LOCAL INPATH './examples/files/kv1.txt' OVERWRITE INTO pokse
然后查看hadoop的文件:
bin/hadoop dfs -ls /hive/warehousedir
看到新增一个文件:
drwxr-xr-x - hadoop supergroup 0 09:06 /hive/warehousedir/pokes
注:使用derby存储方式时,运行hive会在当前目录生成一个derby文件和一个metastore_db目录。这种存储方式的弊端是在同一个目录下同时只能有一个hive客户端能使用数据库,否则报错。
4. 使用MYSQL数据库的方式安装
安装MySQL 我们直接修改hive-site.xml就可以啦。
修改hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.exec.scratchdir</name> <value>/hive/scratchdir</value> <description>Scratch space for Hive jobs</description> </property> <property> <name>hive.exec.local.scratchdir</name> <value>/tmp/${user.name}</value> <description>Local scratch space for Hive jobs</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.1.214:3306/hiveMeta?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hive</value> <description>password to use against metastore database</description> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/hive/warehousedir</value> <description>location of default database for the warehouse</description> </property> <property> <name>hive.aux.jars.path</name> <value> file:///home/hadoop/hive-0.12.0/lib/hive-ant-0.13.0-SNAPSHOT.jar, file:///home/hadoop/hive-0.12.0/lib/protobuf-java-2.4.1.jar, file:///home/hadoop/hive-0.12.0/lib/hbase-client-0.96.0-hadoop2.jar, file:///home/hadoop/hive-0.12.0/lib/hbase-common-0.96.0-hadoop2.jar, file:///home/hadoop/hive-0.12.0/lib/zookeeper-3.4.5.jar, file:///home/hadoop/hive-0.12.0/lib/guava-11.0.2.jar </value> </property>
jdbc:mysql://192.168.1.214:3306/hiveMeta?createDatabaseIfNotExist=true
其中hiveMeta是mysql的数据库名。createDatabaseIfNotExist没有就自动创建
本地mysql启动hive : |
|
$ build/dist/bin/hive --service hiveserver --help
usage: hiveserver
-h,--help Print help information
--hiveconf <property=value> Use value for given property
--maxWorkerThreads <arg> maximum number of worker threads,
default:2147483647
--minWorkerThreads <arg> minimum number of worker threads,
default:100
-p <port> Hive Server port number, default:10000
-v,--verbose Verbose mode
$ bin/hive --service hiveserver
|
下载php客户端包:
其实hive-0.12包中自带的php lib,经测试,该包报php语法错误。命名空间的名称竟然是空的。
我上传php客户端包:http://download.csdn.net/detail/hguisu/6913673(源下载http://download.csdn.net/detail/jiedushi/3409880)
php连接hive客户端代码
- <?php
- // php连接hive thrift依赖包路径
- ini_set('display_errors', 1);
- error_reporting(E_ALL);
- $GLOBALS['THRIFT_ROOT'] = dirname(__FILE__). "/";
- // load the required files for connecting to Hive
- require_once $GLOBALS['THRIFT_ROOT'] . 'packages/hive_service/ThriftHive.php';
- require_once $GLOBALS['THRIFT_ROOT'] . 'transport/TSocket.php';
- require_once $GLOBALS['THRIFT_ROOT'] . 'protocol/TBinaryProtocol.php';
- // Set up the transport/protocol/client
- $transport = new TSocket('192.168.1.214', 10000);
- $protocol = new TBinaryProtocol($transport);
- //$protocol = new TBinaryProtocolAccelerated($transport);
- $client = new ThriftHiveClient($protocol);
- $transport->open();
- // run queries, metadata calls etc
- $client->execute('show tables');
- var_dump($client->fetchAll());
- $transport->close();
- ?>
<?php
// php连接hive thrift依赖包路径
ini_set('display_errors', 1);
error_reporting(E_ALL);
$GLOBALS['THRIFT_ROOT'] = dirname(__FILE__). "/";
// load the required files for connecting to Hive
require_once $GLOBALS['THRIFT_ROOT'] . 'packages/hive_service/ThriftHive.php';
require_once $GLOBALS['THRIFT_ROOT'] . 'transport/TSocket.php';
require_once $GLOBALS['THRIFT_ROOT'] . 'protocol/TBinaryProtocol.php';
// Set up the transport/protocol/client
$transport = new TSocket('192.168.1.214', 10000);
$protocol = new TBinaryProtocol($transport);
//$protocol = new TBinaryProtocolAccelerated($transport);
$client = new ThriftHiveClient($protocol);
$transport->open();
// run queries, metadata calls etc
$client->execute('show tables');
var_dump($client->fetchAll());
$transport->close();
?>
打开浏览器浏览http://localhost/Thrift/test.php就可以看到查询结果了
(责任编辑:IT)