|
ЮФМўЖСШЁЦЪЮі ЮЊСЫСЫНтПЭЛЇЖЫМАгыжЎНЛЛЅЕФHDFSЁЂУћГЦНкЕуКЭЪ§ОнНкЕужЎМфЕФЪ§ОнСїЪЧдѕбљЕФЃЌЮвУЧПЩВЮПМЭМ3-1ЃЌЦфжаЯдЪОСЫдкЖСШЁЮФМўЪБвЛаЉЪТМўЕФжївЊЫГађЁЃ
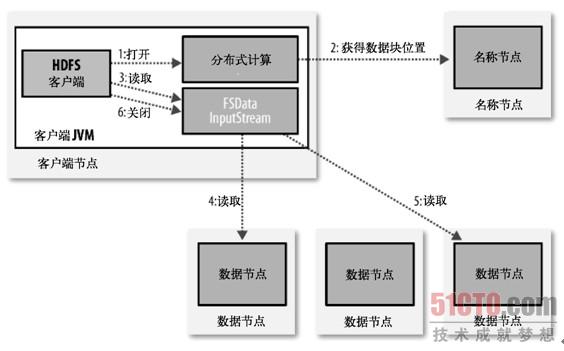
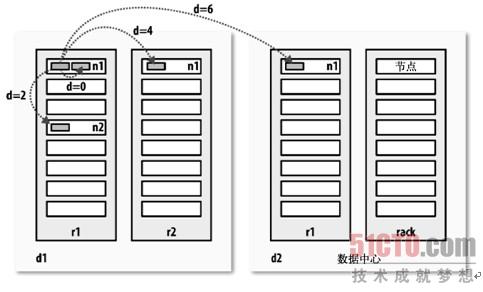
ПЭЛЇЖЫЭЈЙ§ЕїгУFileSystemЖдЯѓЕФopen()РДЖСШЁЯЃЭћДђПЊЕФЮФМўЃЌЖдгкHDFSРДЫЕЃЌетИіЖдЯѓЪЧЗжВМЪНЮФМўЯЕЭГ(ЭМ3-1жаЕФВНжш1)ЕФвЛИіЪЕР§ЁЃDistributedFileystemЭЈЙ§ЪЙгУRPCРДЕїгУУћГЦНкЕуЃЌвдШЗЖЈЮФМўПЊЭЗВПЗжЕФПщЕФЮЛжУ(ВНжш2)ЁЃЖдгкУПвЛИіПщЃЌУћГЦНкЕуЗЕЛиОпгаИУПщИББОЕФЪ§ОнНкЕуЕижЗЁЃДЫЭтЃЌетаЉЪ§ОнНкЕуИљОнЫќУЧгыПЭЛЇЖЫЕФОрРыРДХХађ(ИљОнЭјТчМЏШКЕФЭиЦЫЃЛВЮМћКѓЮФВЙГфВФСЯ"ЭјТчЭиЦЫгыHadoop")ЁЃШчЙћИУПЭЛЇЖЫБОЩэОЭЪЧвЛИіЪ§ОнНкЕу(БШШчдквЛИіMapReduceШЮЮёжа)ЃЌБуДгБОЕиЪ§ОнНкЕужаЖСШЁЁЃ Distributed FilesyStemЗЕЛивЛИіFSData InputStreamЖдЯѓ(вЛИіжЇГжЮФМўЖЈЮЛЕФЪфШыСї)ИјПЭЛЇЖЫЖСШЁЪ§ОнЁЃFSData InputStreamзЊЖјАќзАСЫвЛИіDFSInputStreamЖдЯѓЁЃ НгзХЃЌПЭЛЇЖЫЖдетИіЪфШыСїЕїгУread()(ВНжш3)ЁЃДцДЂзХЮФМўПЊЭЗВПЗжЕФПщЕФЪ§ОнНкЕуЕижЗЕФDFSInputStreamЫцМДгыетаЉПщзюНќЕФЪ§ОнНкЕуЯрСЌНгЁЃЭЈЙ§дкЪ§ОнСїжажиИДЕїгУread()ЃЌЪ§ОнЛсДгЪ§ОнНкЕуЗЕЛиПЭЛЇЖЫ(ВНжш4)ЁЃЕНДяПщЕФФЉЖЫЪБЃЌDFSInputStreamЛсЙиБегыЪ§ОнНкЕуМфЕФСЊЯЕЃЌШЛКѓЮЊЯТвЛИіПщевЕНзюМбЕФЪ§ОнНкЕу(ВНжш5)ЁЃПЭЛЇЖЫжЛашвЊЖСШЁвЛИіСЌајЕФСїЃЌетаЉЖдгкПЭЛЇЖЫРДЫЕЖМЪЧЭИУїЕФЁЃ ПЭЛЇЖЫДгСїжаЖСШЁЪ§ОнЪБЃЌПщЪЧАДееDFSInputStreamДђПЊгыЪ§ОнНкЕуЕФаТСЌНгЕФЫГађЖСШЁЕФЁЃЫќвВЛсЕїгУУћГЦНкЕуРДМьЫїЯТвЛзщашвЊЕФПщЕФЪ§ОнНкЕуЕФЮЛжУЁЃвЛЕЉПЭЛЇЖЫЭъГЩЖСШЁЃЌОЭЖдЮФМўЯЕЭГЪ§ОнЪфШыСїЕїгУclose()(ВНжш6)ЁЃ дкЖСШЁЕФЪБКђЃЌШчЙћПЭЛЇЖЫдкгыЪ§ОнНкЕуЭЈаХЪБгіЕНвЛИіДэЮѓЃЌФЧУДЫќОЭЛсШЅГЂЪдЖдетИіПщРДЫЕЯТвЛИізюНќЕФПщЁЃЫќвВЛсМЧзЁФЧИіЙЪеЯЕФЪ§ОнНкЕуЃЌвдБЃжЄВЛЛсдйЖджЎКѓЕФПщНјааЭНРЭЮовцЕФГЂЪдЁЃПЭЛЇЖЫвВЛсШЗШЯДгЪ§ОнНкЕуЗЂРДЕФЪ§ОнЕФаЃбщКЭЁЃШчЙћЗЂЯжвЛИіЫ№ЛЕЕФПщЃЌЫќОЭЛсдкПЭЛЇЖЫЪдЭМДгБ№ЕФЪ§ОнНкЕужаЖСШЁвЛИіПщЕФИББОжЎЧАБЈИцИјУћГЦНкЕуЁЃ етИіЩшМЦЕФвЛИіжиЕуЪЧЃЌПЭЛЇЖЫжБНгСЊЯЕЪ§ОнНкЕуШЅМьЫїЪ§ОнЃЌВЂБЛУћГЦНкЕужИв§ЕНУПИіПщжазюКУЕФЪ§ОнНкЕуЁЃвђЮЊЪ§ОнСїЖЏдкДЫМЏШКжаЪЧдкЫљгаЪ§ОнНкЕуЗжЩЂНјааЕФЃЌЫљвдетжжЩшМЦФмЪЙHDFSПЩРЉеЙЕНзюДѓЕФВЂЗЂПЭЛЇЖЫЪ§СПЁЃЭЌЪБЃЌУћГЦНкЕужЛВЛЙ§ЪЧЬсЙЉПщЮЛжУЧыЧѓ(ДцДЂдкФкДцжаЃЌвђЖјЗЧГЃИпаЇ)ЃЌВЛЪЧЬсЙЉЪ§ОнЁЃЗёдђШчЙћПЭЛЇЖЫЪ§СПдіГЄЃЌУћГЦНкЕуЛсПьЫйГЩЮЊвЛИі"ЦПОБ"ЁЃ ЭјТчЭиЦЫгыHadoop СНИіНкЕудквЛИіБОЕиЭјТчжаБЛГЦЮЊ"БЫДЫЕФНќСк"ЪЧЪВУДвтЫМЃПдкИпШнСПЪ§ОнДІРэжаЃЌЯожЦвђЫиЪЧЮвУЧдкНкЕуМфДЋЫЭЪ§ОнЕФЫйТЪ--ДјПэКмЯЁШБЁЃетИіЯыЗЈБуЪЧНЋСНИіНкЕуМфЕФДјПэзїЮЊОрРыЕФКтСПБъзМЁЃ КтСПНкЕуМфЕФДјПэЃЌЪЕМЪЩЯКмФбЪЕЯж(ЫќашвЊвЛИіЮШЖЈЕФМЏШКЃЌВЂЧвдкМЏШКжаГЩЖдЕФНкЕуЕФЪ§СПЕФдіГЄвЊЪЧНкЕуЪ§СПЕФЦНЗН)ЃЌВЛМАHadoopВЩгУвЛИіМђЕЅЕФЗНЗЈЃЌАбЭјТчПДзївЛПУЪїЃЌСНИіНкЕуМфЕФОрРыЪЧОрРыЫќУЧзюНќЕФЙВЭЌзцЯШЕФзмКЭЁЃИУЪїжаЕФЕШМЖЪЧУЛгаБЛдЄЯШЩшЖЈЕФЃЌЕЋЪЧЫќЖдгкЯрЕБгкЪ§ОнжааФЁЂПђМмКЭвЛжБдкдЫ ааЕФНкЕуЕФЕШМЖЪЧЙВЭЌЕФЁЃетИіЯыЗЈЪЧЃЌЖдгквдЯТУПИіГЁОАЃЌПЩгУДјПэвРДЮМѕЩйЃК ЯрЭЌНкЕужаЕФНјГЬ ЭЌвЛЛњМмЩЯЕФВЛЭЌНкЕу ЭЌвЛЪ§ОнжааФЕФВЛЭЌЛњМмЩЯЕФНкЕу ВЛЭЌЪ§ОнжааФЕФНкЕу Р§ШчЃЌМйЩшНкЕуn1дкЪ§ОнжааФd1жаЕФЛњМмr1ЩЯЁЃетБЛБэЪОГЩ/d1/r1/n1ЁЃРћгУетжжБъМЧЃЌетРяИјГіЫФжжУшЪіЕФОрРыЃК ОрРы(/d1/r1/n1, /d1/r1/n1)=0(ЯрЭЌНкЕужаЕФНјГЬ) ОрРы(/d1/r1/n1, /d1/r1/n2)=2(ЭЌвЛЛњМмЩЯЕФВЛЭЌНкЕу) ОрРы(/d1/r1/n1, /d1/r2/n3)=4(ЭЌвЛЪ§ОнжааФЕФВЛЭЌЛњМмЩЯЕФНкЕу) ОрРы(/d1/r1/n1, /d2/r3/n4)=6(ВЛЭЌЪ§ОнжааФЕФНкЕу) етдкЭМ3-2жагУЭМЪОаЮЪНБэДя(Ъ§бЇАЎКУепЛсзЂвтЕНетЪЧвЛИіОрРыЙЋжЦЕФР§зг)ЁЃ
|