|
writeable接口对java基本类型提供了封装,short和char除外。所有的封装包含get()和set()两个方法用于读取和设置值。
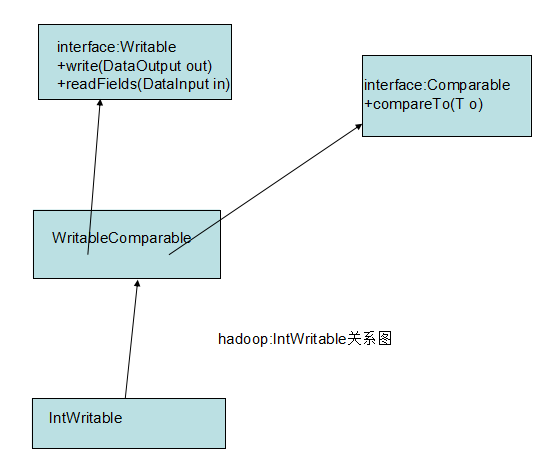
现在看一下IntWritable的源码
(1)IntWritable实现了接口Writable的2个方法:一个用于将其状态写入二进制格式的DataOutput流,另一个用于从二进制格式的DataInput流读取其态 write和readFields分别实现了把对象序列化和反序列化的功能,是Writable接口定义的两个方法 (2)IntWritable声明了变量value,并且实现了set,get方法 (3)声明内部类Comparator,并且实现WritableComparator接口中比较未被序列化的对象方法 (4)注册comparator
Hadoop自带一系列有用的Writable实现,可以满足绝大多数用途。但有时,我们需要编写自己的自定义实现。通过自定义Writable,我们能够完全控制二进制表示和排序顺序。Writable是MapReduce数据路径的核心,所以调整二进制表示对其性能有显著影响。现有的Hadoop Writable应用已得到很好的优化,但为了对付更复杂的结构,最好创建一个新的Writable类型,而不是使用已有的类型。
为了演示如何创建一个自定义Writable,我们编写了一个表示一对字符串的实现,名为TextPair
importjava.io.*;
此实现的第一部分直观易懂:有两个Text实例变量(first和second)和相关的构造函数、get方法和set方法。所有的Writable实现都必须有一个默认的构造函数,以便MapReduce框架能够对它们进行实例化,进而调用readFields()方法来填充它们的字段。 Writable实例是易变的、经常重用的,所以我们应该尽量避免在write()或readFields()方法中分配对象。
通过委托给每个Text对象本身,TextPair的write()方法依次序列化输出流中的每一个Text对象。同样,也通过委托给Text对象本身,readFields()反序列化输人流中的字节。DataOutput和DataInput接口有丰富的整套方法用于序列化和反序列化Java基本类型,所以在一般情况下,我们能够完全控制Writable对象的数据传输格式。 正如为Java写的任意值对象一样,我们会重写java.lang.Object的hashCode()方法,equals()方法和toString()方法。HashPartitioner使用hashCode()方法来选择reduce分区,所以应该确保写一个好的哈希函数来确保reduce函数的分区在大小上是相当的。 TextPair是WritableComparable的实现,所以它提供了compareTo()方法的实现,加入我们希望的顺序:它通过一个一个String逐个排序。请注意,TextPair不同于前面的TextArrayWritable类(除了它可以存储Text对象数之外),因为TextArrayWritable只是一个Writable,而不是WritableComparable。 实现一个快速的RawComparator 上例中所示代码能够有效工作,但还可以进一步优化。正如前面所述,在MapReduce中,TextPair被用作键时,它必须被反序列化为要调用的compareTo()方法的对象。是否可以通过查看其序列化表示的方式来比较两个TextPair对象。 事实证明,我们可以这样做,因为TextPair由两个Text对象连接而成,二进制Text对象表示是一个可变长度的整型,包含UTF-8表示的字符串中的字节数,后跟UTF-8字节本身。关键在于读取开始的长度。从而得知第一个Text对象的字节表示有多长,然后可以委托Text对象的RawComparator,然后利用第一或者第二个字符串的偏移量来调用它。下面例子给出了具体方法(注意,该代码嵌套在TextPair类中)。
静态代码块注册原始的comparator以便MapReduce每次看到TextPair类,就知道使用原始comparator作为其默认comparator。 自定义comparator 从TextPair可知,编写原始的cornparator比较费力,因为必须处理字节级别的细节。如果需要编写自己的实现,org.apache.hadoop.io包中Writable的某些前瞻性实现值得研究研究。WritableUtils的有效方法也比较非常方便。 如果可能,还应把自定义comparator写为RawComparators。这些comparator实现的排序顺序不同于默认comparator定义的自然排序顺序。下面的例子显示了TextPair的comparator,称为First Comparator。只考虑了一对Text对象中的第一个字符串。请注意,我们重写了compare()方法使其使用对象进行比较,所以两个compare()方法的语义是相同的。
?
?
(责任编辑:IT) |
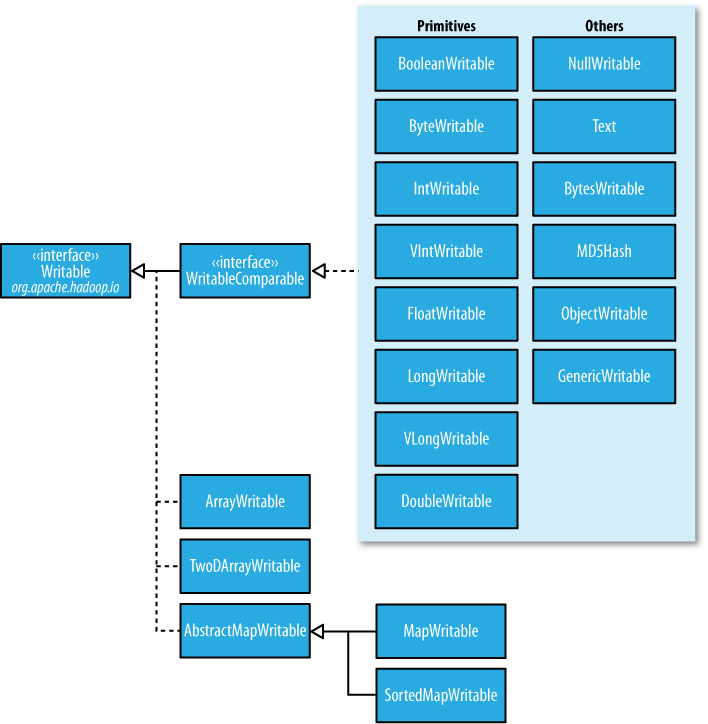 Writable的Java基本类封装
Writable的Java基本类封装