|
(7)安装并运行Hadoop 下载并将hadoop-1.1.2.tar.gz解压到当前用户目录下(/usr/local)。 tar -zxvf hadoop-1.1.2.tar.gz。然后将hadoop文件夹重命名为hadoop。 采用伪分布式hadoop配置 进入hadoop文件夹下的conf夹,修改配置文件。 1.指定jdk安装位置: Hadoop-env.sh: export JAVA_HOME=/usr/local/jdk 2.hadoop核心配置文件,配置HDFS地址和段口号。 core-site.xml
<configuration> 注意:这里hadoop是你的电脑主机名,根据自己的主机名来修改。 3.hdfs-site.xml,默认的配置方式是3,在单机版的hadoop中,将其改为1
<configuration> 4.配置MapReduce文件,配置JobTracker的地址和端口 mapred-site.xml
<configuration>
注意:这里hadoop是你的电脑主机名,根据自己的主机名来修改。
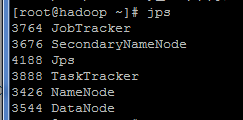
5.接下来,在启动hadoop前,需要格式化hadoop的HDFS。进入hadoop文件夹, 输入bin/hadoop namenode -format 格式化文件系统,接下来启动hadoop 输入命令,启动所有进程: bin/start-all.sh 可以通过jps命令来查看运行的进程,如果成功运行,那么将会有5个进程运行,如下图:
为了方便,也可以把/usr/local/hadoop/bin的路径添加到PATH下,那么久可以直接通过命令:start-all.sh来启动。 vi /etc/profile
export JAVA_HOME=/usr/local/jdk export HADOOP_HOME=/usr/local/hadoop export PATH=.:$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin
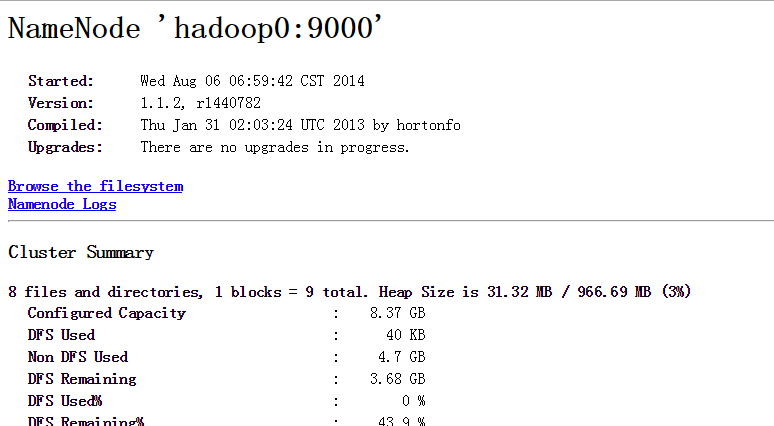
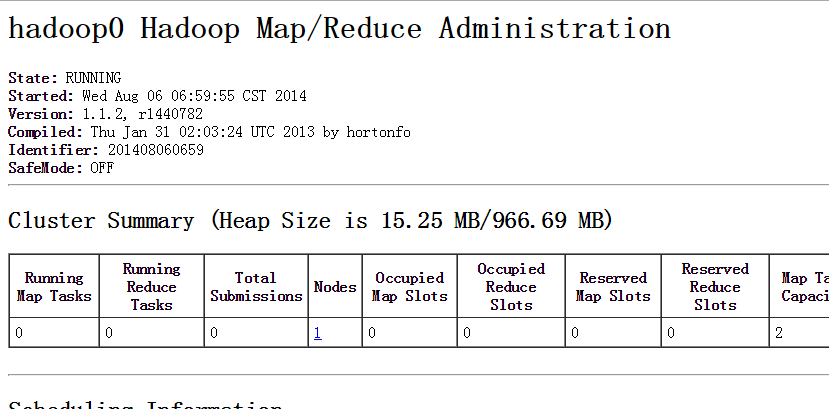
最后验证hadoop是否安装成功。 打开浏览器,分别输入网址: localhost:50030(mapreduce的web页面) localhost:50070(HDFS的web页面)
如果想在windows下访问这两个网址,那么就需要关闭CentOS的防火墙,否则访问不了。 命令:service iptables stop 使用:chkconfig iptables off,可以关闭防火墙的自动运行
备注:我也是刚起步学习hadoop,可能文章有一些不完整或错误的地方,还请大家多多指教,也希望能交流学习,互相促进提高。微笑 (责任编辑:IT) |