|
��������֪��NameNode��Hadoopϵͳ�д��ڵ���������⣬������ڱ��߿����Ե�Hadoop��˵һֱ�Ǹ����ߡ���������һ��Ϊ�˽�������������ڵļ���solution��
1. Secondary NameNode
ԭ����Secondary NN�ᶨ�ڵĴ�NN�ж�ȡeditlog�����Լ��洢��Image���кϲ��γ��µ�metadata image
�ŵ㣺Hadoop����İ汾���Դ������ü���������Ҫ������Դ��������datanode����������
ȱ�㣺�ָ�ʱ���������в������ݶ�ʧ
2. Backup NameNode
ԭ����backup NNʵʱ�õ�editlog����NN崵����ֶ��л���Backup NN��
�ŵ㣺��hadoop0.21��ʼ�ṩ���ַ��������������ݵĶ�ʧ
ȱ�㣺��Ϊ��Ҫ��DataNode�еõ�Block��location��Ϣ�����л���Backup NN��ʱ��Ƚ�������������������
3. Avatar NameNode
ԭ��������Facebook�ṩ��һ��HA��������client����hadoop��editlog����NFS�У�Standby NN�ܹ�ʵʱ�õ�editlog��DataNode��Ҫͬʱ��Active NN��Standby NN report block��Ϣ��
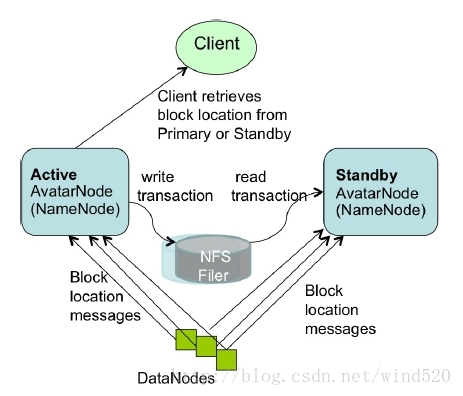
�ŵ㣺��Ϣ���ᶪʧ���ָ��죨�뼶��
ȱ�㣺Facebook����Hadoop0.2�����ģ������������鷳����Ҫ����Ļ�����Դ��NFS��Ϊ��һ�����㣨���������ʵͣ�
4. Hadoop2.0ֱ��֧��StandBy NN�����Facebook��Avatar��Ȼ�����˵�Ľ�
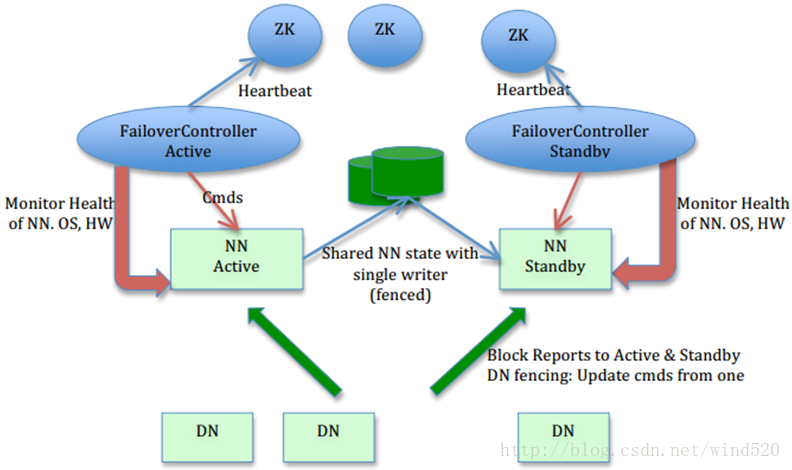
�ŵ㣺��Ϣ���ᶪʧ���ָ��죨�뼶���������
��ϸ����Hadoop NameNode��������������֮һ AvatarNode
����
ʵ��namenodeԪ���ݵı��ݣ����namenode����崻����¼�Ⱥ�����õ����⡣
����������
��namenode���ڷ�����崻���ʱ�����ǿ�������namenode���ݵ�Ԫ����Ѹ���ع��µ�namenode��Ͷ��ʹ�á�
1. Hadoop�����ṩ�˿�����secondarynamenode�ı����������ָ�namenode��Ԫ���ݵķ���������Ϊcheckpoint(��ÿ�� checkpoint��ʱ��secondarynamenode�Ż�ϲ���ͬ��namenode������)�����⣬secondarynamenode�ı������ݲ�����ʱ�̱�����namenodeͬ����Ҳ����˵��namenode崻���ʱ��secondarynamenode���ܻᶪʧһ��ʱ������ݣ���� ʱ��ȡ����checkpoint�����ڡ����ǿ��Լ�Сcheckpoint���������������ݵĶ�ʧ����������ÿ��checkpoint�ܺ����ܣ��������ַ���Ҳ���ܴӸ����Ͻ�����ݶ�ʧ�����⡣������������ϲ������������ݵĶ�ʧ�����ַ�����ֱ�Ӳ��迼�ǡ�
2. Hadoop�ṩ����һ�ַ�������NFS��һ�ּ�ʱ����namenodeԪ���ݵķ��������ö��dataĿ¼������NFSĿ¼������namenode�ڳ� �û�Ԫ���ݵ�ʱ��ͬʱд����Ŀ¼�����ַ����ϵ�һ�ַ������������ܱ������ݵĶ�ʧ������������ʱ������NFS�����ᶪʧ���ݵĿ����ԣ��Ͼ����ּ��ʺ�С ��С������Ȼ���Խ�����ݶ�ʧ�����⣬˵����������ԭ�����ǿ��е�
����Դ��
https://github.com/facebook/hadoop-20
����
����4̨
hadoop1-192.168.64.41 AvatarNode(primary)
hadoop2-192.168.64.42 AvataDataNode
hadoop3-192.168.64.43 AvataDataNode
hadoop4- 192.168.64.67 AvatarNode(standby)
�����Դ������
������Avatar����������صļ��ܡ�
1.���ȹ���Avatar��������Hadoop�ı����Ƕ�Dfs�ĵĵ��㱸�ݣ���������Mapred����ΪHadoop�����Ͳ����ڴ���jobtracker������ϵĻ��ơ�
2.AvatarNode�̳���Namenode�������Ƕ�Namenode���ģ�AvatarDataNodeͬ������ˡ���Avatar�����������Ƕ�����Hadoop�������������ơ�
3.��Avatar�����У�SecondaryNamenode��ְ���Ѱ�����Standby�ڵ��У��ʲ���Ҫ�ٶ�������һ��SecondaryNamenode��
4.AvatarNode������NFS��֧�֣�����ʵ�������ڵ��������־(editlog)�Ĺ�����
5.FB�ṩ��AvatarԴ������ʱ������ʵ��Primary��Standby֮����Զ��л������Խ�����Zookeeper��lease������ʵ���Զ��л���
6.Primary��Standby֮����л�ֻ������Standby�л���Primary������֧�ִ�Primary״̬�л���Standby״̬��
7.AvatarDataNode����ʹ��VIP��AvatarNodeͨ�ţ�����ֱ����Primary��Standbyͨ�ţ�����Ҫʹ��VIPƯ�Ʒ��������������ڵ���л������е�IP�任���⡣�й���Zookeeper�����ϣ��ٷ��ƽ���֮��İ汾������
����AvatarNode����ϸ�Ľ��ܣ���ο�http://blog.csdn.net/rzhzhz/article/details/7235789��
��������
1. ������hadoop��Ŀ¼��build.xml��ע�͵�996�к�1000�С����£�
<targetname="forrest.check"unless="forrest.home"depends="java5.check">
<!--fail message="'forrest.home' is not defined. Pleasepass-Dforrest.home=<base of Apache Forrest installation> to Antonthe command-line." /-->
</target>
<target name="java5.check" unless="java5.home">
<!--fail message="'java5.home' is not defined. Forrest requires Java 5. Please pass -Djava5.home=<base of Java5 distribution> to Ant onthe command-line." /-->
</target>
2. �ڸ�Ŀ¼������ant jar�����ڱ���package���Բο�build.xml�Ĵ��룩����hadoop��������jar������buildĿ¼�£�hadoop-0.20.3-dev-core.jar���� ������jar����hadoop��Ŀ¼���滻��ԭ�е�jar ������һ�䣬hadoop����ʱ���ȼ���buildĿ¼�µ�class�����Ե�ͨ���滻class��jar��ʱ���Ȱ�buildĿ¼��ʱ�Ƴ����� ��
3. ����src/contrib/highavailabilityĿ¼�±���Avatar��������jar������build/contrib/highavailabilityĿ¼��(hadoop-${version}-highavailability.jar)��������jar����libĿ¼�¡�
4. ��2,3���б���õ�jar���ַ�����Ⱥ�����л�������ӦĿ¼��
�ġ�����
1. ����hdfs-site.xml
<?xmlversion="1.0"?>
<?xml-stylesheettype="text/xsl"href="configuration.xsl"?>
<!-- Put site-specificproperty overrides in thisfile. -->
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/data/hadoop/hdfs/name</value>
<description>Determineswhereon the local filesystem the DFS name node shouldstore the name table. Ifthis is a comma-delimited list ofdirectories then the name tableis replicated in all of thedirectories, for redundancy
</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/data/hadoop/facebook_hadoop_data/hdfs/data</value>
</property>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:50011</value>
<description>Ĭ��Ϊ50010, ��datanode�ļ����˿�</description>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50076</value>
<description>Ĭ��Ϊ50075��Ϊdatanode��http server�˿�</description>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50021</value>
<description>Ĭ��Ϊ50020, Ϊdatanode��ipc server�˿�</description>
</property>
<property>
<name>dfs.http.address0</name>
<value>192.168.64.41:50070</value>
</property>
<property>
<name>dfs.http.address1</name>
<value>192.168.64.67:50070 </value>
</property>
<property>
<name>dfs.name.dir.shared0</name>
<value>/data/hadoop/share/shared0</value>
</property>
<property>
<name>dfs.name.dir.shared1</name>
<value>/data/hadoop/share/shared1</value>
</property>
<property>
<name>dfs.name.edits.dir.shared0</name>
<value>/data/hadoop/share/shared0</value>
</property>
<property>
<name>dfs.name.edits.dir.shared1</name>
<value>/data/hadoop/share/shared1</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>
Defaultblock replication. The actual number of replicationscan bespecified when the file is created. The default isused ifreplicationis not specified in create time
</description>
</property>
</configuration>
����˵����
1) dfs.name.dir.shared0
AvatarNode(Primary)Ԫ���ݴ洢Ŀ¼,ע�ⲻ�ܺ�dfs.name.dirĿ¼��ͬ
2) dfs.name.dir.shared1
AvatarNode(Standby)Ԫ���ݴ洢Ŀ¼,ע�ⲻ�ܺ�dfs.name.dirĿ¼��ͬ
3) dfs.name.edits.dir.shared0
AvatarNode(Primary) edits�ļ��洢Ŀ¼��Ĭ���� dfs.name.dir.shared0һ��
4) dfs.name.edits.dir.shared1
AvatarNode(Standby) edits�ļ��洢Ŀ¼��Ĭ���� dfs.name.dir.shared1һ��
5) dfs.http.address0
AvatarNode(Primary) HTTP�ļ�ص�ַ
6) dfs.http.address1
AvatarNode(Standby) HTTP�ļ�ص�ַ
7) dfs.namenode.dn-address0/dfs.namenode.dn-address1
��Ȼ��AvatarԴ���������漰������ʱ��δ�õ�
2. ����core-site.xml
<?xmlversion="1.0"?>
<?xml-stylesheettype="text/xsl"href="configuration.xsl"?>
<!-- Putsite-specificproperty overrides in this file. -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
<description>A baseforother temporary directories.
</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.64.41:9600</value>
<description>The name ofthedefault file system. Eitherthe literal string"local" or a host:port for DFS.
</description>
</property>
<property>
<name>fs.default.name0</name>
<value>hdfs://192.168.64.41:9600</value>
<description>The name ofthedefault file system. Eitherthe literal string"local" or a host:port for DFS.
</description>
</property>
<property>
<name>fs.default.name1</name>
<value>hdfs://192.168.64.67:9600</value>
<description>The name ofthedefault file system. Eitherthe literal string"local" or a host:port for DFS.
</description>
</property>
</configuration>
����˵����
1) fs.default.name
��ǰAvatarNode IP��ַ�Ͷ˿ںţ���Primary��Standby������Ϊ���Ե�IP��ַ�Ͷ˿ںš�
2) fs.default.name0
AvatarNode(Primary) IP��ַ�Ͷ˿ں�
3) fs.default.name1
AvatarNode(Standby) IP��ַ�Ͷ˿ں�
3. ��Ϊ���漰��mapred����mapred-site.xml�������ģ�Ϊԭ�м�Ⱥ���ü��ɡ�
4. �ַ��ĺ�������ļ�����Ⱥ�ڵ㲢��Primary��Standby�ڵ��Ͻ����������ļ�����ӦĿ¼��
5. ����NFS��ʵ��Primary��Standby shared0Ŀ¼�����ݹ������й�NFS��������ο�http://blog.csdn.net/rzhzhz/article/details/7056732
6. ��ʽ��Primary��Standby��������Բ���hadoop�����ĸ�ʽ�����Ҳ���Բ���AvatarNode�ĸ�ʽ�����bin/hadooporg.apache.hadoop.hdfs.AvatarShell -format��������ʱshared1Ŀ¼����Ϊ�գ��˴��е���ࡣ�������hadoop�����ĸ�ʽ��������Primary�ϸ�ʽ�����Ұ�nameĿ¼�µ��ļ����Ƶ�shared0Ŀ¼�¡�Ȼ������Standby�ϸ���shared0Ŀ¼�µ��ļ���shared1Ŀ¼�¡�
�塢����
1. ���ڲ��漰jobtracker�ĵ��㣬����������ֻ����hdfs����̡߳�Primary��Standby����namenode���˴�Standby����SecondaryNamenode��ְ�𣩺�3��AvatarDataNode���ݽڵ㡣
2. ��Primary�ڵ�hadoop��Ŀ¼������AvatarNode��Primary��
bin/hadooporg.apache.hadoop.hdfs.server.namenode.AvatarNode–zero
3. ��Standby�ڵ�hadoop��Ŀ¼������AvatarNode��Standby��
bin/hadooporg.apache.hadoop.hdfs.server.namenode.AvatarNode-one–standby
4. ���������ݽڵ�hadoop��Ŀ¼������AvatarDataNode
bin/hadooporg.apache.hadoop.hdfs.server.datanode.AvatarDataNode
5. �����������
bin/hadoop org.apache.hadoop.hdfs.server.namenode.AvatarNode������� ѡ������
[-standby] | [-sync] |[-zero] | [-one] | [-format] | [-upgrade] | [-rollback] |[-finalize] | [-importCheckpoint]
##�鿴��ǰAvatarNode��״̬
1) bin/hadoop org.apache.hadoop.hdfs.AvatarShell –showAvatar
##primary �ѵ�ǰStandby�ڵ�����Primary�ڵ�
2) bin/hadooporg.apache.hadoop.hdfs.AvatarShell -setAvatar
3) bin/hadooporg.apache.hadoop.hdfs.AvatarShell -setAvatar standby
��Ⱥ����
1. ���ʼ�Ⱥ��webҳ
(Primary)http://hadoop1-virtual-machine:50070
(Standby)http://hadoop5-virtual-machine:50070
�ɼ����е�AvatarDataNode����ע�ᵽ����namenode��Primary��������״̬����Standby����Safemode״̬��ֻ�ɶ�����д����ͨ��AvatarShell����鿴��ǰAvatarNode��״̬��Primary��Standby����
2. �洢������ݵ���Ⱥ����Ⱥ����������
3. Kill��Primary�ڵ��AvatartNode�̣߳���Standby�ѵ�ǰ����ΪPrirmary,���ݲ�δ��ʧ����Ⱥ������������ʱweb�˲������������ļ�ϵͳ��ͨ��shell����ɲ鿴��Ⱥ���ݣ���������Avatar��ת�����ƣ�ֻ����Standbyת����Primary����һ�ι��Ϻ�,��Standby����ΪPrimary�Ľڵ㲢�������½���ΪStandby�����Բ���ʵ����Master/Slave���������л���
(���α༭��IT) |