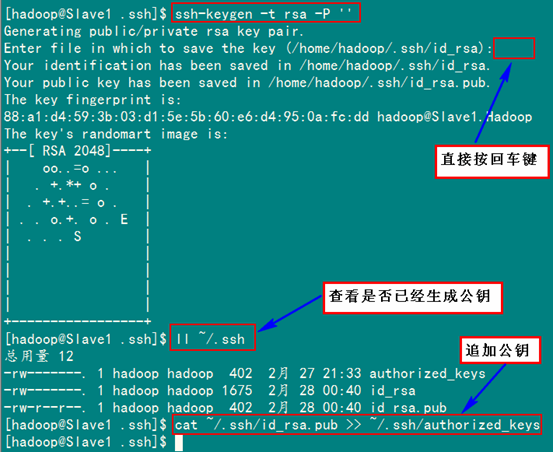
2.3 配置所有Slave无密码登录Master和Master无密码登录所有Slave原理一样,就是把Slave的公钥追加到Master的".ssh"文件夹下的"authorized_keys"中,记得是追加(>>)。 为了说明情况,我们现在就以"Slave1.Hadoop"无密码登录"Master.Hadoop"为例,进行一遍操作,也算是巩固一下前面所学知识,剩余的"Slave2.Hadoop"和"Slave3.Hadoop"就按照这个示例进行就可以了。 首先创建"Slave1.Hadoop"自己的公钥和私钥,并把自己的公钥追加到"authorized_keys"文件中。用到的命令如下:
接着是用命令"scp"复制"Slave1.Hadoop"的公钥"id_rsa.pub"到"Master.Hadoop"的"/home/hadoop/"目录下,并追加到"Master.Hadoop"的"authorized_keys"中。 1)在"Slave1.Hadoop"服务器的操作 用到的命令如下:
2)在"Master.Hadoop"服务器的操作 用到的命令如下:
然后删除掉刚才复制过来的"id_rsa.pub"文件。
最后是测试从"Slave1.Hadoop"到"Master.Hadoop"无密码登录。
从上面结果中可以看到已经成功实现了,再试下从"Master.Hadoop"到"Slave1.Hadoop"无密码登录。
至此"Master.Hadoop"与"Slave1.Hadoop"之间可以互相无密码登录了,剩下的就是按照上面的步骤把剩余 的"Slave2.Hadoop"和"Slave3.Hadoop"与"Master.Hadoop"之间建立起无密码登录。这样,Master能无密码 验证登录每个Slave,每个Slave也能无密码验证登录到Master。
3、Java环境安装所有的机器上都要安装JDK,现在就先在Master服务器安装,然后其他服务器按照步骤重复进行即可。安装JDK以及配置环境变量,需要以"root"的身份进行。
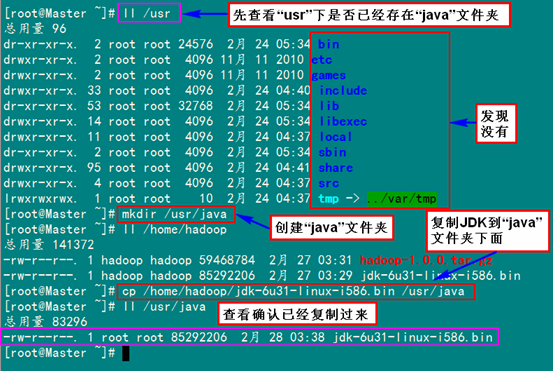
3.1 安装JDK首先用root身份登录"Master.Hadoop"后在"/usr"下创建"java"文件夹,再把用FTP上传到"/home/hadoop/"下的"jdk-6u31-linux-i586.bin"复制到"/usr/java"文件夹中。
接着进入"/usr/java"目录下通过下面命令使其JDK获得可执行权限,并安装JDK。
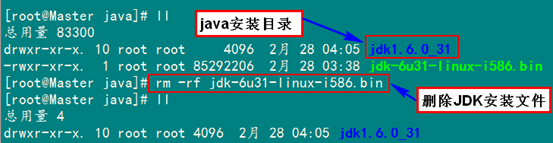
按照上面几步进行操作,最后点击"Enter"键开始安装,安装完会提示你按"Enter"键退出,然后查看"/usr/java"下面会发现多了一个名为"jdk1.6.0_31"文件夹,说明我们的JDK安装结束,删除"jdk-6u31-linux-i586.bin"文件,进入下一个"配置环境变量"环节。
3.2 配置环境变量编辑"/etc/profile"文件,在后面添加Java的"JAVA_HOME"、"CLASSPATH"以及"PATH"内容。 1)编辑"/etc/profile"文件
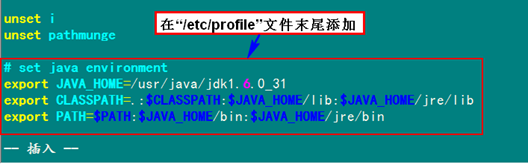
2)添加Java环境变量 在"/etc/profile"文件的尾部添加以下内容:
或者
以上两种意思一样,那么我们就选择第2种来进行设置。
3)使配置生效 保存并退出,执行下面命令使其配置立即生效。
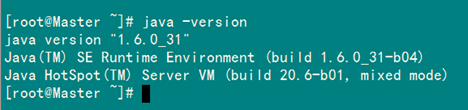
3.3 验证安装成功配置完毕并生效后,用下面命令判断是否成功。
从上图中得知,我们以确定JDK已经安装成功。
3.4 安装剩余机器这时用普通用户hadoop通过下面命令格式把"Master.Hadoop"文件夹"/home/hadoop/"的JDK复制到其他Slave的"/home/hadoop/"下面,剩下的事儿就是在其余的Slave服务器上按照上图的步骤安装JDK。
或者
备注:"~"代表当前用户的主目录,当前用户为hadoop,所以"~"代表"/home/hadoop"。 例如:把JDK从"Master.Hadoop"复制到"Slave1.Hadoop"的命令如下。
然后查看"Slave1.Hadoop"的"/home/hadoop"查看是否已经复制成功了。
从上图中得知,我们已经成功复制了,现在我们就用最高权限用户root进行安装了。其他的与这个一样。 |