|
不论是开发、管理、优化还是设计,对Oracle的基本原理的了解都是必不可少的,于是对自己最近关于Oracle的学习作出一点点的总结。
庖丁解牛之所以能做到“合于桑林之舞,乃中经首之会”,是因为其“所好者道也”。那我们实际的Oracle使用中,了解Oracle的基本体系,也才能对一系列的操作知其然也知其所以然,才能在这个基础上进行相关的优化操作。
开局一张图,内容全靠编。
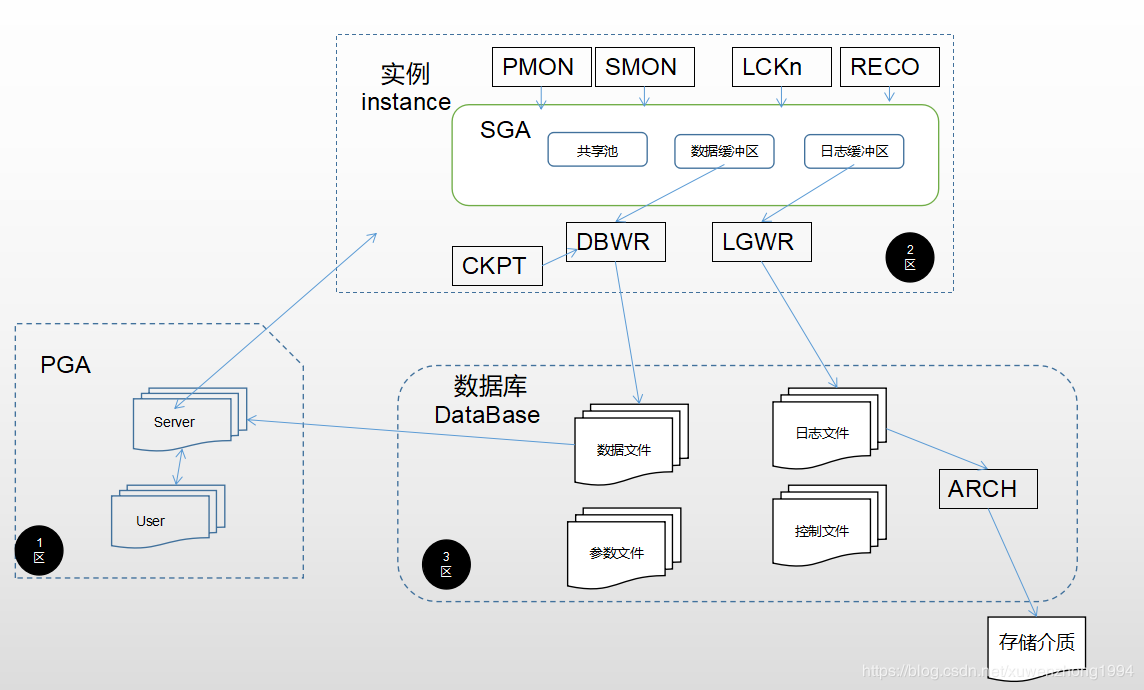
上图是Oracle的一张基本体系图,简单描述一下大概如下四点:
1.Oracle是由数据库和实例组成的;
2.实例是由一个开辟的共享内存区SGA(System Global Area)和一系列后台进程组成的,其中SGA最主要被划分为共享池(shared pool)、数据缓冲区(db cache)和日志缓冲区(log buffer)三类,后台进程包括但不限于图中列出的PMON等进程;
3.数据库是由数据文件、参数文件、日志文件、控制文件、归档日志文件等系列文件组成的,其中归档日志最终可能会被转移到新的存储介质中,用于备份恢复使用;
4.PGA(Program Global Area)区,也是开辟出来的内存区,但和SGA不同的地方是,PGA不是共享内存,是私有不共享的。用户对数据库发起一系列更删改查操作都是在PGA先预处理,然后才进入实例区域,由SGA和后台进程共同完成用户发起的请求;这其中的预处理主要有三点:一是保存用户的连接信息,如会话属性、绑定变量等;二是保存用户权限等重要信息,当用户进程与数据库建立会话时,系统会将这个用户的相关权限查询出来,然后保存在这个会话区内;三是当发起的指令需要排序的时候,PGA正是这个排序区,如果内存中可以放下排序的尺寸,就在内存PGA区内完成,如果放不下,超出的部分就在临时表空间中完成排序,也就是在磁盘中完成排序;
我们以一条简单的查询语句”select username from tsys_user t where t.user_id = ‘001’”为例,看看这条语句都在Oracle里经历了怎样的旅程。
当用户发起这条SQL指令后,首先在1区做准备工作,获取用户连接信息和权限信息并保存,在连接未断开之前,下次该用户操作数据库时,都是直接从PGA取用户信息。然后为这条SQL生成一个对应的HASH值,然后进入2区;
在2区的共享池中根据这个HASH值查找是否有存储过这条SQL的信息,如果没有,就检查SQL的语法、语义以及是否有权限信息等,检查通过后,估算SQL语句的执行效率,选最高效的执行计划并将hash值和对应的执行计划存储下来。
然后进入数据缓存区去取数,如果数据缓存区有数据,则返回数据,如果没有对应的数据,则去3区的database数据文件中取数,如果查到了就存在数据缓存区,并返回结果,如果没有数据,则查询不到数据。
所以用户的请求发起经历的顺序一般是1区到2区再到3区;或者1区到2区
目前为止,图中的后台进程都未提及。但假如是一条更新语句”update tsys_user t set t.age = 18 where t.user_id = ‘001’”,在找到对应的数据的时候所经历的步骤都是和select语句一样,更新语句在找到数据之后,在数据缓冲区内修改完数据,然后commit,启用DBWR进程,将数据从内存中刷入磁盘。
所有关于数据库的操作都会记录日志在日志缓冲区,由LGWR进程负责。一般日志文件分成几个小块,第一个小块写满了写到第二个小块,第二个写满写到第三个小块,如此循环至所有小块写满。然后ARCH进程从头开始备份第一个小块到存储介质中,然后LGWR进程重写地一小块日志缓冲区。因为日志缓冲区存储所有的相关操作这个特性,所以Oracle不会每commit一次就将数据写进磁盘,而是批量写进去。而CKPT进程就是调度批量刷进磁盘数据的进程,可以修改CKPT的FAST_START_MTTR_TARGET参数来调整触发CKPT进程。
其中还有PMON进程,是进程监视器,当有进程失败异常或者是崩溃了,会对进程重启或者回滚操作;SMON进程则是系统监视器,关注的是系统级的操作而非单个进程,主要在于数据库实例,此外还有清理临时表空间、清理回滚段表空间和合并空闲空间等;LCKn则是实例间的封锁;RECO则是用于分布式数据库的恢复;
其中LGWR进程,为保证日志记录的顺序性,只能采用单进程,所以LGWR进程每三秒钟运行一次;任何commit触发一次;DBWR将数据从缓存写入磁盘触发一次;日志缓冲区满三分之一或记录满1MB,触发一次;联机日志文件切换触发一次。
重点介绍LGWR进程是因为,所有回滚操作都是建立在日志记录的基础上进行的。
那了解Oracle的体系结构有什么用呢?当然大有所用,有些优化的操作就可以有的放矢了:
1.由于排序是在PGA中进行的,如果PGA放不下排序的数据,甚至要在磁盘中进行,那如果无需排序则不进行排序,如果排序是必须的,且数据量庞大,则可以适当增加PGA的大小。
2.如果数据库很大,访问量很高,可以适当增加共享池的大小,避免很多SQL的解析;相应的,如果数据访问量很小,但数据库服务器内存资源有限,可以不用给SGA开辟很大的内存空间;
3.如果数据库的更新操作频繁,日志文件产生很快且多,可以适当增加日志文件的大小,防止日志块写满,频繁切换日志记录块。
以上只是针对Oracle的基本体系的浅显说明,很多的SQL优化手段都是基于这个基础体系上进行的。下期准备在基础体系的基础上介绍索引的利与弊。如果对我的文章有兴趣,欢迎关注我的公众号“代码狗go”,会不定期更新一些自己的学习所得哦。
(责任编辑:IT) |