|
1. 软连接与硬链接区别
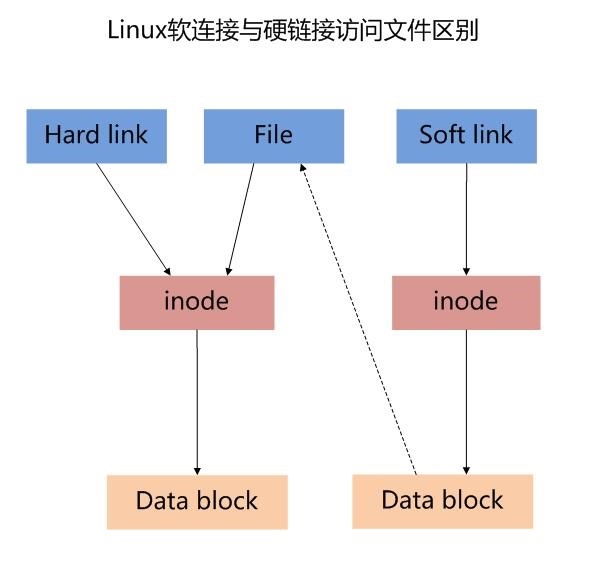
2. Linux文件删除原理

3. linux系统的启动过程
BIOS(基本输入输出系统)
-
1. 检查硬件,即计算机硬件是否满足运行基本条件。(如果硬件有问题主板会发出有频率的蜂鸣,启动终止);
-
2. 查找软盘、光盘或硬盘的引导装在程序(指引导记录,即MBR);
-
3. 将引导装在程序(MBR)载入内存,将控制权交给MBR.
MBR(主引导记录)
MBR位于启动盘第一扇区(一般为/dev/hda或者/dev/sda)
MBR共有512位由三部分组成:
① 1-446bit 主引导加载程序信息
② 447-510bit 存放分区表
③ 511-512bit 存储MBR有效标记
GRUB(启动管理器)
GRUB会让你选择启动的内核
GRUB会通过配置文件找到内核及Initrd镜像,initrd镜像含有内核所需的基本模块驱动
Kernel
由于init是被linux第一个执行的程序,所以它的进程号为1.
在根系统被挂载之前,initrd被内核作为一个临时文件系统,内核启东市展开改initrd加载根驱动,在驱动的补充下挂载根分区.
init
Runlevel programs
s开头程序为启动进程使用,即startup;
k开头程序为关闭过程使用,即kill.
s和k后面的数字代表执行顺序
即S12syslog,这个进程的启动顺序为12.
S80sendmail启动顺序为80,就会比syslog晚启动.
4. top命令右上角的load average的值是什么意思,高于多少代表负载有问题
拆分出四个内容 :
1. load average(系统平均负载)是什么?
系统平均负载被定义为在特定时间间隔内运行队列中(在CPU上运行或者等待运行多少进程)的平均进程数.
2. load average的三个数值代表什么?
通过top\uptime\w可以获取到load average的值,它的三个数字值分别记录了一分钟\五分钟\十五分钟的系统平均负载.
3. 高于多少负载有问题?
高于多少代表负载有问题呢,这里有两个法则:
4. 我们以哪个数字为准?一分钟?五分钟?还是十五分钟?
我认为你应该着眼于五分钟或者十五分钟的平均数值。坦白讲,如果前一分钟的负载情况是 1.00,那么仍可以说明认定服务器情况还是正常的。 但是如果十五分钟的数值仍然保持在 1.00,那么就值得注意了(根据我的经验,这时候你应 该增加的处理器数量了).
5. 查看网络I/O命令
dstat:多功能系统资源统计工具,不但可以获取net(网络)信息,还可以获取disk(硬盘)\处理器(CPU)等信息,结果可保存为csv.
dstat的用法如下:
dstat [-afv] [options..] [delay [count]]
使用 dstat -h查看全部选项,这里不逐一列举,下面简单介绍下常用选项
常用选项如下:
# 直接跟数字,表示#秒收集一次数据,默认为一秒;dstat 5表示5秒更新一次
-c,--cpu 统计CPU状态,包括 user, system, idle(空闲等待时间百分比), wait(等待磁盘IO), hardware interrupt(硬件中断), software interrupt(软件中断)等;
-d, --disk 统计磁盘读写状态
-D total,sda 统计指定磁盘或汇总信息
-l, --load 统计系统负载情况,包括1分钟、5分钟、15分钟平均值
-m, --mem 统计系统物理内存使用情况,包括used, buffers, cache, free
-s, --swap 统计swap已使用和剩余量
-n, --net 统计网络使用情况,包括接收和发送数据
-N eth1,total 统计eth1接口汇总流量
-r, --io 统计I/O请求,包括读写请求
-p, --proc 统计进程信息,包括runnable、uninterruptible、new
-y, --sys 统计系统信息,包括中断、上下文切换
-t 显示统计时时间,对分析历史数据非常有用
--fs 统计文件打开数和inodes数
查看网络命令为下
解释:指定查看Lo和eth0网卡,每条数据存在100秒(每一秒实时刷新数据,这个频率貌似不能改),共刷新5条.
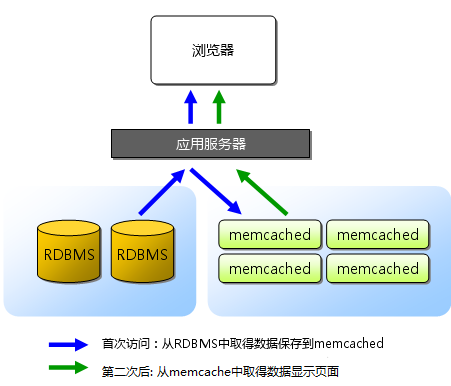
6. memcache运行原理
7. 当一个网站访问慢时,你怎么去优化 ###
翻译为: 当一个网站访问慢时, 你都是怎么去查找问题,和解决问题以达到优化效果的
第一,用5分钟排除网络因素,借助工具(如pagespeed)分析页面加载过程
1. 某个元素或者图片加载过慢: 具体原因具体分析
2. DNS解析时长问题: 可以通过购买解析服务, 来让自己的域名在各地DNS更多缓存
3. 网络带宽瓶颈: 考虑增加带宽
4. 网络线路波动: 考虑CDN,或者镜像站
第二,要考虑到服务器问题
1. 是否有服务器过载: 考虑增加硬件
2. I/O操作:数据库的频繁读写,服务器的频繁请求(包括静态文件的读取,图片的读取)等都属于I/O问题。对于数据库的问题,首先要优化SQL,存储过程等。如果单表数据量过大要考虑做分割或者运用程序来控制分表。如果请求量过大,要考虑做集群。对于服务器(静态)文件的I/O问题,则可以考虑做CDN,这样也可以解决地域性问题。对于动态文件的访问,则涉及到代码优化及负载均衡两项。
3. 具体应用优化: nginx针对访问量修改配置文件,调高Buffers 调低keep alive空连接时间等
第三,安全方面
1. 查看web\mail等其它服务日志,是否存在被攻击现象: 针对安全方面加固
2. 是否有其它攻击存在DDOS,WEB CC等
8. mysql主从不同步怎么解决
-
在master端执行:
mysql> flush logs;
mysql> show master status;
PS:记下File、Position的值。
-
在slave端执行:
mysql> stop slave;
mysql> CHANGE MASTER TO MASTER_LOG_FILE='bin-log.000002',MASTER_LOG_POS=107;
mysql> start slave;
mysql> show slave status
sql命令手动同步,还有一种方法是跳过这个导致错误的事物
-
跳过指定数量的事务:
mysql>slave stop;
mysql>SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1 #跳过一个事务
mysql>slave start
-
修改mysql的配置文件,通过slave_skip_errors参数来跳所有错误或指定类型的错误
vi /etc/my.cnf
[mysqld]
slave-skip-errors=1062,1053,1146 #跳过指定error no类型的错误
slave-skip-errors=all #跳过所有错误
9. 进程和线程的区别
翻译: 进程和线程的概念
-
进程(英语:process),是计算机中已运行程序的实体。进程是程序的基本执行实体,进程本身不是基本运行单位,而是线程的容器
-
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
① 进程是系统进行资源分配的基本单位,有独立的内存地址空间; 线程是CPU调度的基本单位,没有单独地址空间,有独立的栈,局部变量,寄存器, 程序计数器等。
② 创建进程的开销大,包括创建虚拟地址空间等需要大量系统资源; 创建线程开销小,基本上只有一个内核对象和一个堆栈。
③ 一个进程无法直接访问另一个进程的资源;同一进程内的多个线程共享进程的资源。
④ 进程切换开销大,线程切换开销小;进程间通信开销大,线程间通信开销小。
⑤ 线程属于进程,不能独立执行。每个进程至少要有一个线程,成为主线程
10. 常用的RAID原理
RAID 0连续以位或字节为单位分割数据,并行读/写于多个磁盘上,因此具有很高的数据传输率,但它没有数据冗余,因此并不能算是真正的RAID 结构。RAID 0 只是单纯地提高性能,并没有为数据的可靠性提供保证,而且其中的一个磁盘失效将影响到所有数据。因此,RAID 0 不能应用于数据安全性要求高的场合。
RAID 1它是通过磁盘数据镜像实现数据冗余,在成对的独立磁盘上产生互为备份的数据。当原始数据繁忙时,可直接从镜像拷贝中读取数据,因此RAID 1 可以提高读取性能。RAID 1是磁盘阵列中单位成本最高的,但提供了很高的数据安全性和可用性。当一个磁盘失效时,系统可以自动切换到镜像磁盘上读写,而不需要重组失效的数据。简单来说就是:镜象结构,类似于备份模式,一个数据被复制到两块硬盘上。
RAID 10高可靠性与高效磁盘结构一个带区结构加一个镜象结构,因为两种结构各有优缺点,因此可以相互补充。主要用于容量不大,但要求速度和差错控制的数据库中。
RAID 5分布式奇偶校验的独立磁盘结构,它的奇偶校验码存在于所有磁盘上,任何一个硬盘损坏,都可以根据其它硬盘上的校验位来重建损坏的数据。支持一块盘掉线后仍然正常运行。
11. 有没有做过性能调优
这个是个大的话题,要反问是应用调优还是系统调优 没有进行过调优,基本调优步骤:
1. 找出系统性能瓶颈(包括硬件瓶颈和软件瓶颈);
2. ***能优化的方案(升级硬件?改进系统系统结构?);
3. 达到合理的硬件和软件配置;
4. 使系统资源使用达到最大的平衡。
12. 请求一个网站的过程
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户
13. lvs/dr调度的过程
客户端请求发送给LVS ==> LVS接受请求后根据调度算法选出后台服务器 ==> LVS将报文目标MAC地址修改为该服务器 ==> 服务器处理请求后直接返回给客户端
14. 我想查看WEB日志中访问TOP 10的IP有哪些怎么查看
当时是面试官让我把具体命令说出来, 也就是看看知道一些处理文本的命令嘛.其实不难:
|
|
cat logfile |cut -d ' ' -f 5 |sort |uniq -c | sort -nr | head -n 10 |less
|
cut命令负责将文本以空格分开,取第五列数据==>
排序==> 去重并统计次数(-c参数就是统计参数)==> 再次排序(统计次数会被写在IP之前, 所以这里是按统计次数排序 sort的-r是逆序就是从大到小,-n为按数字排序主要是sort默认排序很可能会把10判断为比2还小,通过-n就不会出现这个情况)==> 取次数最多的10条==> less可有可无
15. CDN的主要原理
CDN是一种组合技术,主要包含以下3个方面:
① 源站
源站指发布内容的原始站点。添加、删除和更改网站的文件,都是在源站上进行的;另外缓存服务器所抓取的对象也全部来自于源站。
② 缓存服务器
缓存服务器是直接提供给用户访问的站点资源,有一台或数台服务器组成;当用户发起访问时,他的访问请求被智能DNS定位到离他较近的缓存服务器。如果用户所请求的内容刚好在缓存里面,则直接把内容返还给用户;如果访问所需的内容没有被缓存,则缓存服务器向邻近的缓存服务器或直接向源站抓取内容,然后再返还给用户。
③ 智能DNS
智能DNS是整个CDN技术的核心,它主要根据用户的来源,将其访问请求指向离用户比较近的缓存服务器,如把广州电信的用户请求指向到广州电信IDC机房中的缓存服务器。通过智能DNS解析,让用户访问同服务商下的服务器,消除国内南北网络互相访问慢的问题,达到加速作用。智能DNS的出现,颠复了传统的一个域名对应一个镜像的做法,让用户更加便捷的去访问网站。
缓存服务器中有访问内容:
客户端请求 ==> 智能DNS解析到最近的缓存服务器 ==> 缓存服务器返回请求资源
缓存服务器中无访问内容:
客户端请求 ==> 智能DNS解析到最近的缓存服务器 ==> 缓存服务器发现没有客户端请求资源,向源站请求 ==> 源站返回资源到缓存服务器 ==> 缓存服务器返回客户端请求资源
16. 跨服务器同步文件
当时面试官原问题是, "将某一个文件夹的所有图片(不同类型jpg|png)同步到另一台服务器的",当时我那个不会啊...只憋出个find命令含含糊糊的说了下.
回来赶紧复习了下, 其实就两个内容, 一个是怎么查找到这个文件, 一个是怎么去同步到另一台服务器:
怎么查找:
1. ls命令 + grep命令
|
|
ls /tmp/test | grep ".*\.jpg\|.*\.png"
|
最简单易懂, 只不过ls并不是查找命令, 所以这条命令也只是去查看了/tmp/test文件夹下的有哪些文件,并没有对/tmp/test下的子目录去搜索.
2. find命令
|
|
find /tmp/test -type f -regex '.*\.jpg\|.*\.png'
|
最常用的查找命令, 可以通过指定正则\文件类型\文件大小\文件权限\文件属主属组\文件时间等对文件匹配查找.
还有一些locate\whereis等等比较另类的命令,都可以用,只要你能定位到你的文件就可以,这里就不一一举例.
怎么同步:
通过管道将查找交给负责同步的命令
-
xargs + scp命令
ls /tmp/test | grep ".*\.jpg\|.*\.png" | xargs -n1 -I {} scp {} root@192.168.1.97:/tmp
find /tmp/test -type f -regex '.*\.jpg\|.*\.png' | xargs -n1 -I {} scp {} root@192.168.1.97:/tmp
|
使用xargs接收管道标准输入,然后执行远程拷贝命令.
-
find命令 + scp命令
|
|
find /tmp/test -type f -regex '.*\.jpg\|.*\.png' -exec scp {} root@192.168.1.97:/tmp \;
|
也可以配合xargs命令完成
|
|
find /tmp/test -type f -regex '.*\.jpg\|.*\.png' | xargs -n1 -I {} scp {} root@192.168.1.97:/tmp
|
这两条效果一样的,执行过程都是建立子进程逐个文件scp.比较坑的是, 你要使用scp文件的话,没有秘钥认证远程主机的话,每个文件都要输一次密码...
-
rsync同步 普通rsync同步:
|
|
find /tmp/test -type f -regex '.*\.jpg\|.*\.png' | xargs -n1 -I {} rsync {} root@192.168.1.97:/tmp
|
上传rsync server同步(需要远程主机已搭建rsync服务器):
|
|
find /tmp -type f -regex '.*\.jpg\|.*\.png'| xargs -n1 -I {} rsync -avzP {} wys@192.168.1.98::wys
|
以上的两条和scp一样需要逐个密码认证,而rsync有--password-file指定密码文件(注意密码文件权限必须600,否则会报错)来戴我们认证密码,像这样:
|
|
find /tmp -type f -regex '.*\.jpg\|.*\.png'| xargs -n1 -I {} rsync -avzP {} --password-file=/tmp/wys.password wys@192.168.1.98::wys
|
同步的命令或者服务也有很多,但是像这种临时性的不是很大量的使用我觉得最多rsync就够了.
涉及到到知识:
rsync服务器搭建:参考一 | 参考二
rsync命令: 参考一
find命令:参考一
xargs命令: 参考一 注意这篇里边-I参数例子中有个错误少写了替换字符串,应该是:
17. mysql增删改查基础问题(笔试基础)
-
增
INSERT INTO 表名称 VALUES(值1,值2,...); #按列的顺序将值依次赋给对应列的对象
INSERT INTO 表名称(列1,列2) VALUES(值1,值2); #对应列插入相应值
-
删
DELETE FROM 表名称 WHERE 列 运算符 值; # 例: DELETE FROM tab WHERE name=job; 匹配到name列值为job的一条记录,删除它
DELETE * FROM 表名称; #清空表
-
改
UPDATE 表名称 SET 列名称=新值 WHERE 列=值; 例: UPDATE tab SET name=eason WHERE id=3; 匹配到id列值为3的记录,修改该记录name的值为eason
-
查
SELECT 列名称1,列名称2... FROM 表名称; # 指定列查询
SELECT * FROM 表名称; # 查询表所有内容
SELECT 列名称 FROM 表名称 WHERE 列 运算符 值; # 例: SELECT name FROM tab WHERE id<10; 匹配到tab的id列小于10的记录, 查看这些记录name列的值
SELECT DISTINCT 列名称 FROM 表名称; #删除返回结果的重复项
SELECT * FROM 表名称 ORDER BY 列名称; #按照某一列排序(从小到大顺序)
SELECT * FROM 表名称 ORDER BY 列名称 DESC; #按照某一列排序(倒序)
18. 服务器更换主板后linux无法识别网卡
系统加载网卡驱动后会去读一个文件,这个文件是一个缓存文件,包含了网卡的mac地址,因为更换了主板,网卡的mac也变动了,但是这个文件的mac还是没有变,所以现有的网卡mac地址和文件里的不同,所以系统就拒绝启动,把这个文件删除后重启系统就可以了 操作为下:
>#mv /etc/udev/rules.d/70-persistent-net.rules /etc/udev/rules.d/70-persistent-net.rules.bak
>#reboot #重启后会生成新的缓存文件
(责任编辑:IT) |