-

hadoop-reduce分析
日期:Map的结果,会通过partition分发到Reducer上,Reducer做完Reduce操作后,通过OutputFormat,进行输出 Map的结果,会通过partition分发到Reducer上,Reducer做完Reduce操作后,通过OutputFormat,进行输出。 ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18...
-

hadoop-ID分析
日期:我们开始来分析Hadoop MapReduce的内部的运行机制。用户向Hadoop提交Job(作业),作业在JobTracker对象的控制下执行。Job被分解成为Task(任务),分发到集群中,在TaskTracker的控制下运行。Task包括MapTask和ReduceTask,是MapReduce的Map操作和Reduce操...
-
Hadoop杂记
日期:namenode(hdfs)+jobtracker(mapreduce)可以放在一台机器上,datanode+tasktracker可以在一台机器上,辅助namenode要单独放一台机器,jobtracker通常情况下分区跟datanode一样(目录最好分布在不同的磁盘上,一个目录对应一个磁盘),namenode存储目录需要...
-
hadoop 节点正常启动可是50075/50030不能访问
日期:情景描述: 因为以前namenode节点下面的hadoop/lib文件夹加入了一些别的jar包(为了测试一些东西),而datanode节点下面的hadoop/lib文件夹没有增加.导致hadoop启动错误.为了统一,我把namenode节点下面的hadoop/lib文件夹下面的所有文件都删除了,从datanode节点...
-
Cannot delete .... . Name node is in safe mode
日期:摘要org.apache.hadoop.ipc.RemoteException: org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot delete /benchmarks/TestDFSIO/io_control. Name node is in safe mode. 如何关闭安全模式呢? 命令为: 1 bin/hadoop dfsadmin -safemode le...
-
Hadoop序列化中的Writable接口(附部分源码)
日期:序列化是将结构化对象为字节流以便与通过网络进行传输或者写入持久存储。反序列化指的是将字节流转为一系列结构化对象的过程。 序化在分布式数据处理的两列大领域经常出现:进程间通信和永久存储 hadoop中,节点直接的进程间通信是用远程过程调用(RPC)实现...
-
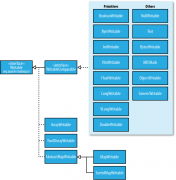
Hadoop 实现定制的Writable类型(附部分源码)
日期:writeable接口对java基本类型提供了封装,short和char除外。所有的封装包含get()和set()两个方法用于读取和设置值。 Writable的Java基本类封装 Java基本类型 Writable使用序列化大小(字节) 布尔型 BooleanWritable 1 字节型 ByteWritable 1 整型 IntWritab...
-
hadoop 压缩
日期:编码器和解码器用以执行压缩解压算法。在Hadoop里,编码/解码器是通过一个压缩解码器接口实现的。 Hadoop可用的编码/解码器。 压缩格式 Hadoop压缩编码/解码器 DEFLATE org.apache.hadoop.io.compress.DefaultCodec gzip org.apache.hadoop.io.compress.Gzip...
-
hadoop 数据一致模型
日期:文件系统的一致模型描述了对文件读写的数据可见性。HDFS为性能牺牲了一些POSIX请求,因此一些操作可能比想像的困难。 在创建一个文件之后,在文件系统的命名空间中是可见的,如下所示: pathp=newPath(p); Fs.create(p); assertThat(fs.exists(p),is(true));...
-
hadoop常见问题Browse the filesystem链接打不开
日期:现象: 在访问 Master:50070 之后,点击 browse the filesystem 后,该页无法显示。 原因: 点击 browse the filesystem 后,网页转向的地址用的是 hadoop 集群的某一个 datanode 的主机名,由于客户端的浏览器无法解析这个主机名,因此该页无法显示。 解决...