-
CentOS6.5 安装 Hadoop
日期:Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set...
-

Hadoop/Yarn/MapReduce内存分配(配置)方案
日期:以horntonworks给出推荐配置为蓝本,给出一种常见的Hadoop集群上各组件的内存分配方案。方案最右侧一栏是一个8G VM的分配方案,方案预留1-2G的内存给操作系统,分配4G给Yarn/MapReduce,当然也包括了HIVE,剩余的2-3G是在需要使用HBase时预留给HBase的。 Con...
-

hadoop启动脚本解读
日期:本文以start-dfs.sh为例向下延展解释各脚本的作用和相互关系,对于start-yarn.sh同理可证。下图解释了各个脚本的作用: 注意:slaves.sh在通过SSH推送命令时,会首先读取$HADOOP_SLAVE_NAMES这个数组中的机器列表作为推送目标,当这个数组为空时才使用slaves...
-
配置NTP服务ntpd/ntp.conf(搭建Hadoop集群可参考)
日期:本文拟定是在一个局域网内(比如一个Hadoop集群)设定一台NTP服务器作为整个网络的标准时间参考,使用网络(集群)内的所有机器保持时间一致!以下是详细的操作步骤: 1. 修改选定的服务器的本地时间 #date -s 2014-11-21 12:48:30 +%F %T #2014-11-21 12:48:...
-
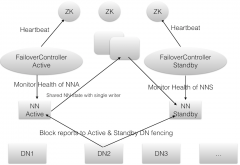
配置高可用的Hadoop平台
日期:1.概述 在Hadoop2.x之后的版本,提出了解决单点问题的方案--HA(High Available 高可用)。这篇博客阐述如何搭建高可用的HDFS和YARN,执行步骤如下: 创建hadoop用户 安装JDK 配置hosts 安装SSH 关闭防火墙 修改时区 ZK(安装,启动,验证) HDFS+HA的结...
-
Hadoop jobhistory历史服务器介绍
日期:Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Had...
-
修改HDFS文件块大小
日期:1 通过Hadoop自带的WEB监控管理界面我们可以看到文件块的大小现在为64MB。 2 关闭集群 3 设置每个namenode节点和datanode节点的hdfs-site.xml文件,将文件中 的dfs.block.size属性值改为33554432(32M),重启集群 4 再次添加一个文件 会看到文件块的大小变...
-
基于Hadoop0.20.2版本的namenode与secondarynamenode分离实验
日期:我们在Hadoop配置集群时,经常将namenode与secondarynamenode存放在一个节点上,其实这是非常危险的,如果此节点崩溃的话,则整个集群不可恢复。下面介绍一下将namenode与secondarynamenode分离的方法。当然还存在好多不足和待改进的地方,欢迎各位大神指点...
-
Hadoop集群部署时候的几个问题记录
日期:由于Hadoop 2.5.x 已经出来有好几个月了,网上配置类似架构的文章也有很多,所以在这里重点描述一下namenode 和 secondary namenode不再同一台机器上的配置方法,以及namenode 宕机后 meta数据的恢复方法,并且描述一下几个主要配置文件中配置项的意义。 集...
-
Hadoop单节点安装部署
日期:从零开始 机器环境 Distributor ID:CentOS Description: CentOS release 5.8 (Final) Release: 5.8 Codename: Final jdk 版本 java version 1.6.0_45 hadoop 版本 2.5.2 http://mirrors.cnnic.cn/apache/hadoop/common/hadoop-2.5.2/ 安装jdk: 从甲骨文官方...