-

Hadoop-HDFS源码学习草记
日期:HDFS protocol: Block 块定义,组成(blockId,numBytes,generationStamp),定义问块文件的文件命名为blk_{blockId},存储的最小单位。 BlockListAsLongs:每个Block块可以由3个long的数字表达,使用long[]存储Block[],主要用于datanode高效的上报给namenode...
-

Hadoop初探之MapReduce+HBase实例
日期:一、环境配置 这里选择的环境是hadoop-0.20.2和hbase-0.90.4,Hadoop环境配置参看这里,HBase环境配置请看这里。 需要注意的是,本文的需求是在Hadoop上跑MapReduce job来分析日志并将结果持久化到HBase,所以,在编译程序时,Hadoop需要用到HBase和Zookeeper...
-
Hadoop集群搭建
日期:本文主要向大家介绍有关Hadoop集群搭建,从配置环境到简单的命令启动一一进行了讲解。希望对于想接触hadoop的你有所帮助。 首先说一下配置环境:三台电脑 192.168.30.149hadoop149namenode和jobtracker###因为149机器稍微好一点 192.168.30.150hadoop150data...
-
Hadoop安装部署
日期:花了两天时间把Hadoop 0.18.3部署到了RedHat 9上。总结一下思路。 环境:RedHat 9 + Hadoop 0.18.3 + JDK 1.6u14 新建一个用户: howard 首先,从SUN上下载了JDK 1.6u14(使用Hadoop必须保证JDK在1.5以上的版本)用root身份登录,使用vi /etc/profile命令,在...
-
谈Hadoop的C++扩展
日期:原文在http://blog.sina.com.cn/s/blog_6e273ebb0100pid0.html 长期一来,Hadoop因为其Java实现带来的性能问题而饱受争议,同时也涌现了很多方案来缓解这一问题。 Jeff Hammerbacher(Cloudera首席科学家)曾在Quora上写过这样一段: ----------------------...
-
Hadoop C++ Pipes中context常见成员函数的作用
日期:getJobConf Get the JobConf for the current task getInputKey Get the current key getInputValue Get the current value In the reducer, context.getInputValue is not available till context.nextValue is called ! progress This method simply phone...
-
面向MapReduce 的数据处理流程开发方法 ------------重点内容摘要
日期:摘 要:数据处理流程在信息爆炸的今天被广泛应用并呈现出海量和并行的特点, MapReduce 编程模型的简单性和高性价比使得其适用于海量数据的并行处理, 但是 MapReduce 不支持多数据源的数据处理, 不能直接应用于具有多个处理操作、多个数据流分支的数据处理流...
-
在Redhat AS6上搭建Hadoop集群总结
日期:本周末在家里的两台电脑上用Vmware+Redhat As6 + hadoop-0.21.0上搭建了一个3节点的Hadoop集群,虽说是原来已经搭建过类似的集群了,也跑过JavaAPI来操作HDFS与Map/reduce,但是这一次依然是受到挑战了,好些小细节,稍有遗漏就会有如坐过山车一般大起大落。...
-
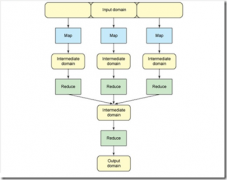
Map-Reduce简介
日期:MapReduce是一种编程模型,始于:Dean, Jeffrey Ghemawat, Sanjay (2004). MapReduce: Simplified Data Processing on Large Clusters。主要应用于大规模数据集的并行运算。其将并行计算简化为Map和reduce过程,极大地方便了编程人员在不会分布式并行编程的...
-

Hadoop MapReduce
日期:mapreducehadoop分布式计算任务分布式存储程序开发 Hadoop MapReduce是一个用于处理海量数据的分布式计算框架。这个框架解决了诸如数据分布式存储、作业调度、容错、机器间通信等复杂问题,可以使没有并行处理或者分布式计算经验的工程师,也能很轻松地写出...