-

Hadoop2.X/YARN环境搭建 CentOS7.0系统配置
日期:Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个应用程序分解为许多并行计算指令,跨大量的计算节点运行非常巨大的数据集。使用该框架的一个典型例子就是在网络数据上运行的搜索算法。 一、我缘何选择CentOS7.0 14年7月7...
-

Hadoop在Windows系统的Eclipse下运行Cannot run program "chmod": CreateProcess error=2解决办法
日期:运行hadoop程序报错如下: Exception in thread main java.io.IOException: Cannot run program chmod: CreateProcess error=2 解决方法: 只需要把cygwin的bin目录加到windows的用户环境变量中就可以了,然后需要重启eclipse...
-
Hadoop 2.0 代码:Client端代码简要分析
日期:1.概览 以下主要叙述Hadoop如何将用户写好的MR程序,以Job的形式提交 主要涉及的四个java类文件: hadoop-mapreduce-client-core下的包org.apache.hadoop.mapreduce: Job.java、JobSubmitter.java hadoop-mapreduce-client-jobclient下的包org.apache.hadoo...
-

Hadoop:The Definitive Guid 总结 Chapter 1~2 初识Hadoop、MapReduce
日期:1.数据存储与分析 问题:当磁盘的存储量随着时间的推移越来越大的时候,对磁盘上的数据的读取速度却没有多大的增长 从多个磁盘上进行并行读写操作是可行的,但是存在以下几个方面的问题: 1).第一个问题是硬件错误。使用的硬件越多出错的几率就越大。一种常...
-
Hadoop:The Definitive Guid 总结 Chapter 3 Hadoop分布式文件系统
日期:1.HDFS的设计 HDFS设计的适合对象:超大文件(TB级别的文件)、流式数据访问(一次写入,多次读取)、商用硬件(廉价硬件) HDFS设计不适合的对象:低时间延迟的数据访问、大量的小文件、多用户写入,任意修改文件 2.HDFS的概念 1).数据块(Block) HDFS中Block的大...
-

Hadoop:The Definitive Guid 总结 Chapter 4 Hadoop I/O
日期:1.数据的完整性 1).HDFS的数据完整性 HDFS以透明方式校验所有写入它的数据,并在默认设置下,会在读取数据时验证校验和。针对数据的每个io.bytes.per.checksum字节都会创建一个单独的校验和。默认值为512字节; DataNode负责在存储数据(包括数据的校验和)...
-

Hadoop:The Definitive Guid 总结 Chapter 5 MapReduce应用开发 (R1)
日期:用MapReduce来编写程序,有几个主要的特定流程,首先写map函数和reduce函数,最好使用单元测试来确保函数的运行符合预期,然后,写一个驱动程序来运行作业,要看这个驱动程序是否可以运行,之后利用本地IDE调试,修改程序 实际上权威指南的一些配置已经过时...
-
Hadoop:The Definitive Guid 总结 Chapter 6 MapReduce的工作原理(R1)
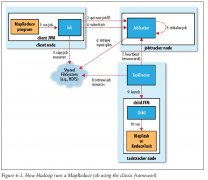
日期:1.剖析MapReduce作业运行机制 1).经典MapReduce--MapReduce1.0 整个过程有有4个独立的实体 客户端:提交MapReduce JobTracker:协调作业的运行 TaskTracker:运行作业划分后的任务 HDFS:用来在其他实体之间共享作业文件 以下为运行整体图 A.作业的提交 JobC...
-

Hadoop:The Definitive Guid 总结 Chapter 7 MapReduce的类型与格式
日期:MapReduce数据处理模型非常简单:map和reduce函数的输入和输出是键/值对(key/value pair) 1.MapReduce的类型 Hadoop的MapReduce一般遵循如下常规格式: map(K1, V1) list (K2, V2) combine(K2, list(V2)) list(K2, V2) partition(K2, V2) integer reduce(K2,...
-
Hadoop:The Definitive Guid 总结 Chapter 8 MapReduce的特性
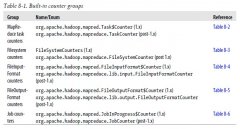
日期:1.计数器 计数器是一种收集Job统计的有效手段,用于质量控制或应用级统计。计数器的应用使得获取统计数据比使用日志文件获取数据更加容易。 1).内置计数器 Hadoop的内置计数器用来描述Job的各项指标,例如已处理的字节数和记录数,输入数据量和输出数据量。...