-
Hadoop:The Definitive Guid 总结 Chapter 9 构建MapReduce集群
日期:1.集群规范 1)配置规范 一般Hadoop DataNode和TaskTracker节点典型机器具有吐下规范: 处理器:2个四核 2~2.5 GHz CPU 内存:16~24 ECC RAM 存储器:4*1TB SATA 磁盘 网络:千兆以太网 2).网络拓扑 Hadoop集群架构包含两级网络拓扑,如下图所示,机架拓扑由...
-
Hadoop:The Definitive Guid 总结 Chapter 10 管理Hadoop
日期:1.HDFS 1).永久性数据结构 A.NameNode的目录结构 NameNode被格式化之后,将产生所示的目录结构: ${dfs.name.dir}/current/VERSION /edits /fsimage /fstime dfs.name.dir属性中列出的目录的内容都是相同,同为如上所示的目录结构 VERSION文件是一个Java属性...
-

Notes for Hadoop the definitive guide
日期:1.Introduction to HDFS 1.1.HDFS Concepts 1.1.1.Blocks lHDFS too has the concept of a block, but it is a much larger unit 64 MB by default. lLike in a filesystem for a single disk, files in HDFS are broken into block-sized chunks, which are...
-
Hadoop的运行痕迹
日期:在使用hadoop的时候,可能遇到各种各样的问题,然而由于hadoop的运行机制比较复杂,因而出现了问题的时候比较难于发现问题。 本文欲通过某种方式跟踪Hadoop的运行痕迹,方便出现问题的时候可以通过这些痕迹来解决问题。 一、环境的搭建 为了能够跟踪这些运行...
-
HDFS读写过程解析(R1)
日期:一、文件的打开 1.1、客户端 HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为: public FSDataInputStream open(Path f, int bufferSize) throws IOException { return new DFSClient.DFSDataInputStream(...
-
HDFS简介 (R1)
日期:一、HDFS的基本概念 1.1、数据块(block) HDFS(Hadoop Distributed File System)默认的最基本的存储单位是64M的数据块。 和普通文件系统相同的是,HDFS中的文件是被分成64M一块的数据块存储的。 不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块...
-
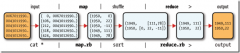
Map-Reduce入门 (R1)
日期:1、Map-Reduce的逻辑过程 假设我们需要处理一批有关天气的数据,其格式如下: 按照ASCII码存储,每行一条记录 每一行字符从0开始计数,第15个到第18个字符为年 第25个到第29个字符为温度,其中第25位是符号+/- 0067011990999991950051507+0000+ 004301199099...
-
hadoop0.20.2完全分布模式安装和配置
日期:----------------------------------------------------------- hadoop集群规划 IP地址 hostname ------------ -------- 10.10.10.100master(namenode,secondary namenode,job tracker) 10.10.10.101slave1(datanode,tasktracker) 10.10.10.102slave2(datano...
-
hadoop0.20.2伪分布模式安装和配置
日期:虚拟机软件VMWare Server2.0 操作系统:RedHat Enterprise Linux Server 5.3(32bit) hadoop版本:0.20.2 jdk版本:1.7 注意:各操作用户请注意查看命令行的提示符 1、首先查看下该虚拟机系统的网络配置 [root@hadoop ~]# cat /etc/hosts # Do not remove the...
-
hadoop-集群管理(1)――配置文件
日期:1. 配置文件列表如下: [tianyc@Route conf]$ pwd /home/tianyc/hadoop-1.0.4/conf [tianyc@Route conf]$ ll 总用量 76 -rw-rw-r--. 1 tianyc NEU 7457 3月 6 10:38 capacity-scheduler.xml -rw-rw-r--. 1 tianyc NEU 535 3月 6 10:38 configuration.xsl -rw...