-
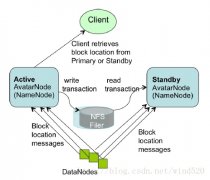
Hadoop中Namenode单点故障的解决方案及详细介绍
日期:正如大家所知,NameNode在Hadoop系统中存在单点故障问题,这个对于标榜高可用性的Hadoop来说一直是个软肋。本文讨论一下为了解决这个问题而存在的几个solution。 1. Secondary NameNode 原理:Secondary NN会定期的从NN中读取editlog,与自己存储的Image进行...
-
编译hadoop的eclipse插件hadoop-eclipse-plugin-1.2.1.jar
日期:1:下载后Hadoop-1.1.2.tar.gz文件,里面包含源代码,并解压到E:\hadoop\hadoop-1.2.1 2:在eclipse导入工程,目录选择:E:\hadoop\hadoop-1.2.1\src\contrib\eclipse-plugin 3:在项目 MapReduceTools 中新建 lib 目录,将 hadoop-1.2.1 下的 hadoop-core-1...
-

大数据集群环境ambari支持集群管理监控,供应hadoop+hbase+zookeeper
日期:大数据集群环境ambari支持集群管理监控,供应hadoop+hbase+zookeeper Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog...
-

CentOS7下LVS+Keepalived实现高性能高可用负载均衡
日期:一、规划 对外VIP:10.10.10.10对内VIP:192.168.10.10LVS_MASTER:10.10.10.28(eth0)192.168.10.128(eth1)LVS_BACKUP:10.10.10.29(eth0)192.168.10.129(eth1)WEB1:192.168.10.130WEB2:192.168.10.131 二、释义 LVS 是 Linux Virtual Server 的简写,意即 Linux...
-

CentOS 6.5 LVS + KeepAlived 搭建 负载均衡 高可用 集群
日期:手把手教程: CentOS 6.5 LVS + KeepAlived 搭建 负载均衡 高可用 集群 为了实现服务的高可用和可扩展,在网上找了几天的资料,现在终于配置完毕,现将心得公布处理,希望对和我一样刚入门的菜鸟能有一些帮助。 一、理论知识(原理) 我们不仅要知其然,而且...
-
MapReduce 中的两表 join 几种方案简介
日期:1. 概述 在传统数据库(如:MYSQL)中,JOIN操作是非常常见且非常耗时的。而在HADOOP中进行JOIN操作,同样常见且耗时,由于Hadoop的独特设计思想,当进行JOIN操作时,有一些特殊的技巧。 本文首先介绍了Hadoop上通常的JOIN实现方法,然后给出了几种针对不同...
-
MapReduce中的自定义多目录/文件名输出HDFS
日期:最近考虑到这样一个需求: 需要把原始的日志文件用hadoop做清洗后,按业务线输出到不同的目录下去,以供不同的部门业务线使用。 这个需求需要用到MultipleOutputFormat和MultipleOutputs来实现自定义多目录、文件的输出。 需要注意的是,在hadoop 0.21.x之前...
-
使用 FileSystem JAVA API 对 HDFS 进行读、写、删除等操作
日期:Hadoop文件系统 基本的文件系统命令操作, 通过hadoop fs -help可以获取所有的命令的详细帮助文件。 Java抽象类org.apache.hadoop.fs.FileSystem定义了hadoop的一个文件系统接口。该类是一个抽象类,通过以下两种静态工厂方法可以过去FileSystem实例: public...
-
MapReduce:默认Counter的含义
日期:MapReduce Counter为提供我们一个窗口:观察MapReduce job运行期的各种细节数据。今年三月份期间,我曾经专注于MapReduce性能调优工作,是否优化的绝大多评估都是基于这些Counter的数值表现。MapReduce自带了许多默认Counter,可能有些朋友对它们有些疑问,现...
-
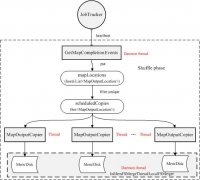
Hadoop中shuffle阶段流程分析
日期:宏观上,Hadoop每个作业要经历两个阶段:Map phase和reduce phase。对于Map phase,又主要包含四个子阶段:从磁盘上读数据-》执行map函数-》combine结果-》将结果写到本地磁盘上;对于reduce phase,同样包含四个子阶段:从各个map task上读相应的数据(shuf...