-

Hadoop MapReduce
日期:mapreducehadoop分布式计算任务分布式存储程序开发 Hadoop MapReduce是一个用于处理海量数据的分布式计算框架。这个框架解决了诸如数据分布式存储、作业调度、容错、机器间通信等复杂问题,可以使没有并行处理或者分布式计算经验的工程师,也能很轻松地写出...
-

Hadoop Streaming
日期:Hadoop MapReduce和HDFS采用Java实现,默认提供Java编程接口,另外提供了C++编程接口和Streaming框架。Streaming框架允许 任何程序语言 实现的程序在Hadoop MapReduce中使用,方便已有程序向Hadoop平台移植。 Streaming的原理 是用Java实现一个包装用户程序...
-
Hadoop客户端环境配置
日期:1. 安装客户端(通过端用户可以方便的和集群交互) 2. 修改客户端~/.bashrc alias hadoop=/home/work/hadoop/client/hadoop-client/hadoop/bin/hadoop #hadoop 可执行文件位置 alias hls=hadoop fs -ls alias hlsr=hadoop fs -lsr alias hcp=hadoop fs -cp a...
-
Hadoop Streaming 实战: grep
日期:streaming支持shell 命令的使用。但是,需要注意的是,对于多个命令,不能使用形如cat; grep 之类的多命令,而需要使用脚本,后面将具体介绍。 下面示例用grep检索巨量数据: 1. 待检索的数据放入hdfs $ hadoop fs -put localfile /user/hadoop/hadoopfile...
-
Hadoop Streaming 实战: bash脚本
日期:streaming支持使用脚本作为map、reduce程序。以下介绍一个实现分布式的计算所有文件的总行数的程序 1. 待检索的数据放入hdfs $ hadoop fs -put localfile /user/hadoop/hadoopfile 2. 编写map、reduce脚本,记得给脚本加可执行权限。 mapper.sh view plain #!...
-
Hadoop Streaming 实战: 文件分发与打包
日期:如果程序运行所需要的可执行文件、脚本或者配置文件在Hadoop集群的 计算节点 上不存在,则首先需要将这些文件分发到集群上才能成功进行计算。 Hadoop提供了自动分发文件和压缩包的机制,只需要在启动Streaming作业时配置相应的参数。 1. file 将本地文件分发...
-
使用hadoop存储图片服务器 使用hadoop存储图片服务器
日期:公司的一个服务需要存储大量的图片服务器,考虑使用hadoop的hdfs来存放图片文件.以下是整个架构思路: 使用hadoop作为分布式文件系统,hadoop是一个实现了HDFS文件系统和MapReduce的开源项目,我们这里只是 使用了它的hdfs.首先从web页面上上传的文件直接调用...
-
yarn hadoop mapreduce 2.0 编译
日期:下载 [zhouhh@h185 ~]$ wget http://labs.mop.com/apache-mirror/hadoop/chukwa/stable/chukwa-0.4.0.tar.gz[zhouhh@h185 ~]$ wget http://labs.mop.com/apache-mirror/hadoop/common/hadoop-2.0.1-alpha/hadoop-2.0.1-alpha.tar.gzLength: 82726054 (79M)[z...
-
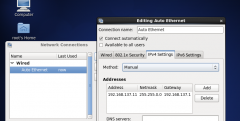
正式生产环境下hadoop集群的DNS+NFS+ssh免密码登陆配置
日期:环境虚拟机centos6.5 主机名h1 IP 192.168.137.11 作为DNS FNS的服务器 主机名h2 IP 192.168.137.12 主机名h3 IP 192.168.137.13 建立DNS(为了取代集群修改hosts带来的大量重复工作) 1.安装DNS在h1上面 检查命令: rpm q bind rpm -q bind-chroot 安装命令...
-
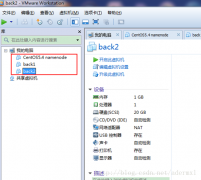
Hadoop 1.1.2分布式安装过程 (vmware10+centeros5.4 64位+hadoop1.1.2+ securecrt)
日期:Hadoop 1.1.2分布式安装过程 (vmware10+centeros5.464位+hadoop1.1.2+ securecrt) 安装环境 虚拟机:vmware10 操作系统:centeros5.4 64位 Hadoop版本:hadoop1.1.2 Securecrt7.0.0 jdk-7u51-linux-x64.gz 1虚拟机环境配置 1.1在win7系统安装虚拟机vmware1...