-

Hadoop2.2.0伪分布式完全安装手册
日期:网络上充斥着大量Hadoop1的教程,版本老旧,Hadoop2的中文资料相对较少,本教程的宗旨在于从Hadoop2出发,结合作者在实际工作中的经验,提供一套最新版本的Hadoop2相关教程。 为什么是Hadoop2.2.0,而不是Hadoop2.4.0 本文写作时,Hadoop的最新版本已经是2.4...
-
hadoop常见配置含义
日期:参数 取值 备注 fs.default.name NameNode 的URI。 hdfs://主机名/ dfs.hosts/dfs.hosts.exclude 许可/拒绝DataNode列表。 如有必要,用这个文件控制许可的datanode列表。 dfs.replication 默认: 3 数据复制的分数 dfs.name.dir 举例: /home/username/hado...
-
hadoop安装及配置流程
日期:Hadoop环境配置以及安装过程: 1、Linux系统安装,以及网络的搭建 1.1 网络的选择为host-only模式 1.2 启动vmwave的虚拟网络配置器 1.3修改ip地址,将VMware网络配置器中的iP地址设置成192.168.80.1,在Linux中网络连接中将连接更改为manual(自定义),并设...
-
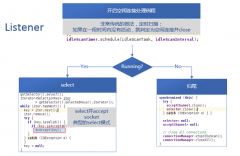
Hadoop 的 Server 及其线程模型分析
日期:一、Listener Listener线程,当Server处于运行状态时,其负责监听来自客户端的连接,并使用Select模式处理Accept事件。 同时,它开启了一个空闲连接(Idle Connection)处理例程,如果有过期的空闲连接,就关闭。这个例程通过一个计时器来实现。 当select操...
-

Linux 下 Hadoop 2.6.0 集群环境的搭建
日期:本文旨在提供最基本的,可以用于在生产环境进行Hadoop、HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用。 基础环境 JDK的安装与配置 现在直接到Oracle官网(http://www.oracle.com/)寻找JDK7的安装包不太容易,因为现在官方推荐JDK8。...
-
Hadoop DistributedCache分布式缓存的使用
日期:做项目的时候遇到一个问题,在Mapper和Reducer方法中处理目标数据时,先要去检索和匹配一个已存在的标签库,再对所处理的字段打标签。因为标签库不是很大,没必要用HBase。我的实现方法是把标签库存储成HDFS上的文件,用分布式缓存存储,这样让每个slave都能...
-
Hadoop的安装与配置及示例程序wordcount的运行
日期:前言 最近在学习Hadoop,文章只是记录我的学习过程,难免有不足甚至是错误之处,请大家谅解并指正!Hadoop版本是最新发布的Hadoop-0.21.0版本,其中一些Hadoop命令已发生变化,为方便以后学习,这里均采用最新命令。具体安装及配置过程如下: 1 机器配置说明...
-
超详细单机版搭建hadoop环境图文解析
日期:年前,在老大的号召下,我们纠集了一帮人搞起了hadoop,并为其取了个响亮的口号云在手,跟我走。大家几乎从零开始,中途不知遇到多少问题,但终 于在回家之前搭起了一个拥有12台服务器的集群,并用命令行在该集群上运行了一些简单的mapreduce程序。想借此总...
-
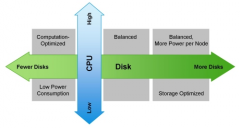
Hadoop 硬件规划
日期:Hadoop近几年一直很热门,市面上有各种各样的书籍以及培训机构,当你熟悉完这些准备在生产上运行自己的第一个生产Hadoop集群的时候,就需要考虑购买什么样的硬件了,专业人士肯定会说:这要看你的业务类型和负载了,当然这是很有道理的,但是我接触的很多企业...
-
hadoop启动namenode失败
日期:启动hadoop的namenode时,报错: ERRORorg apache. Hadoop. HDFS. Server. The namenode. The namenode: Java. Lang. IllegalArgumentException: Does not contain a valid host: port authority: HDFS: / / hadoop_forged: 9000 原因分析: 一般都是配置文...