使用SQL Trace来实现SQL Server的跟踪操作
时间:2016-06-05 20:18 来源:linux.it.net.cn 作者:IT
在SQLServer中,跟踪信息由一系列的事件组成。数据库引擎是事件生成者,跟踪控制器负责事件的分发以及事件的过滤,
跟踪会话负责对事件的列过滤以及跟踪事件的终点。本文通过实例解释了这一过程,供读者学习参考。
说到跟踪,很多人会想起SQL Profiler。SQL Profiler仅仅是一个GUI,SQL Trace才是本质。SQL Trace是构建服务器跟踪和Profiler的基础。如果你了解到这点,那你就会毫不犹豫的在生产环境使用服务器跟踪。下面分别从跟踪的代价、跟踪架构、反跟踪和跟踪原则等方面来介绍SQL Trace,并通过一个实例使这些介绍更加的通俗易懂。
一、SQL Trace跟踪的代价
必须指出,跟踪会影响系统的性能这是不可完全避免的。当然可以通过一些方式我们能将这种代价降到最小。很多人往往以跟踪会影响现网性能为理由而拒绝跟踪。其实这是不对的,还有一些人平时也做跟踪,不过他们喜欢在系统不繁忙的时候跟踪。这样的做法都是有问题的。前者往往会出现突然间你的系统出现问题,而你完全没有任何预兆,后者往往会出现你错过捕获问题的最佳时机这样在不繁忙时的跟踪等于白费。 那什么时候对生产环境进行跟踪呢?正确的做法应该是每时每刻的收集系统信息,为对系统性能整体分析提供信息来源。
二、SQL Trace架构
如果你想理解SQL Trace,那最好的方式莫过于用你自己的系统去对比。一般情况下我们都会在系统中记录一些日志,根据我们关注的点来区分记录日志的级别。典型的日志组件就是Log4net之类的日志组件。这样我们就能够通过日志来分析系统的运行情况。知道这点,那理解SQL Trace就容易了。在SQLServer中,跟踪信息由一系列的事件组成。既然有事件,那谁触发事件呢。数据库引擎中的各个组件都是事件的生产者。下面看看SQL Trace的架构图:
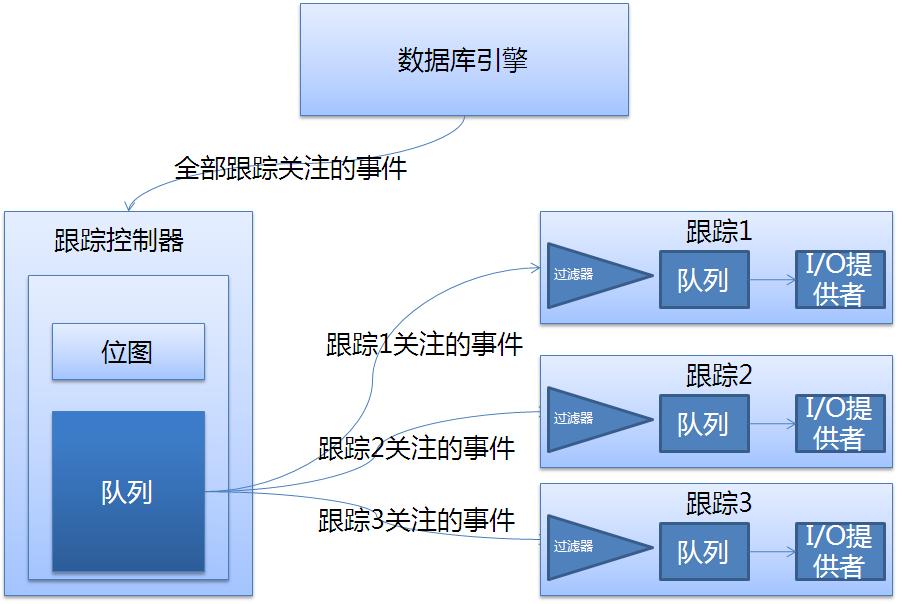
如上图所示:整个SQL Trace架构有三个部分组成,数据库引擎、跟踪控制器、跟踪会话。数据库引擎是事件生成者,跟踪控制器负责事件的分发以及事件的过滤,跟踪会话负责对事件的列过滤以及跟踪事件的终点。下面简单描述下整个过程,跟踪控制器通过一个位图让数据库引擎的其他组件知道跟踪器请求了哪些事件,这个位图是所有跟踪的事件集合。一旦数据库引擎生成一个事件后,就把事件信息保存在跟踪控制器中的队列中。然后跟踪控制器把完整的事件信息传递给每个要求这个事件的跟踪会话。跟踪会话接收到自己关注的事件信息时,先经过过滤器(主要是过滤掉不感兴趣的列与行),过滤掉后发送给跟踪的I/O提供者。这里面的队列只是起缓冲作用。I/O提供者有很多种,比如Profiler、服务器跟踪、SQLServer自己的跟踪。
三、具体跟踪例子
这里的例子不想用SQL Profiler进行举例,因为我觉得它仅仅是方便我们跟踪而已。但是它在跟踪时既会把输出写入目标文件或者表(然后选择保存文件中保存表)还有把跟踪信息写入运行Profiler的客户端。把跟踪信息写入到运行Profiler客户端,这个比直接写入文件往往会慢。大家可以想想为什么?不过倒是可以用Profiler图形化方式定义跟踪,然后导出生成的跟踪SQL。具体如下:
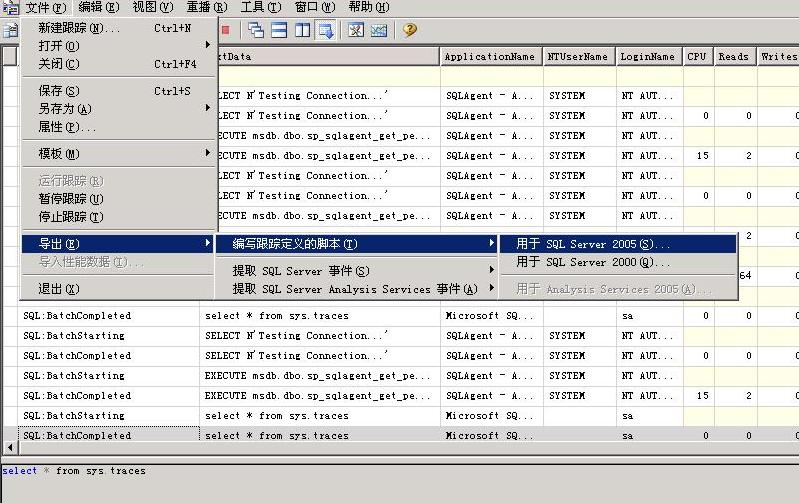
一旦你开启了跟踪后,你可以通过:
select * from sys.traces 查看到你正在跟踪的会话。
四、如何反跟踪
有时候,我们不希望自己的sql被人跟踪。比如,我们不希望别人能看到我们程序中写的sql。方法有很多,这里介绍一种简单的方法。思路就是:强迫SQLServer停止跟踪。具体存储过程如下:
名称:[DBO].[Performance_Trace_StopAll]
功能:防止反跟踪
作者:junling
创建时间:2011-02-09
项目名称:XXXX
历史记录:
编号 日期 作者 备注
1.0 2011-02-09 junling 创建
代码的执行过程如下:
-
create proc [dbo].[Performance_Trace_StopAll]
-
-
AS
-
-
declare traceCursor cursor for select id from sys.traces where id <> 1
-
-
open traceCursor
-
-
declare @curid int
-
-
fetch next from traceCursor into @curid
-
-
while(@@fetch_status=0)
-
-
begin
-
-
exec sp_trace_setstatus @curid,0
-
-
exec sp_trace_setstatus @curid,2
-
-
fetch next from traceCursor into @curid
-
-
end
-
-
close traceCursor
-
-
deallocate traceCursor
具体什么时候调用,就是看你具体的情况了。
五、SQL Trace跟踪原则
这里主要列出我们在跟踪时应该注意的事项,或者说按照下面的原则会降低跟踪对生产环境的影响。
1、不要使用Profiler GUI跟踪,如果使用了尽量不要运行在跟踪的SQLServer所在服务器;
2、不要把跟踪数据直接写入表,我们可以采用系统不是很繁忙时才把跟踪信息导入表中(除非你想立刻分析数据);
3、跟踪会有大量的I/O操作,尽量把跟踪文件单独放在物理磁盘中;
4、只选择自己感兴趣的事件,多选一个事件都会带来开销(除非你多选的事件不发生,那样也就没有选择的必要;
5、过滤你的跟踪信息,比如你只对某数据库感兴趣,你只对某些列感兴趣(注意这里仅仅是减少了架构图中的I/O提供者的开销,想想为什么);
6、像XXXXXXStarting之类的事件往往没有太大意义;
7、要注意你跟踪的sql中是否使用了标量函数,对这些sql的跟踪会严重影响性能,每个标量函数每处理一行都会触发事件(如果表很大,这是件很恐怖的事件);
8、只给需要跟踪的用户指定跟踪权限。
(责任编辑:IT)
在SQLServer中,跟踪信息由一系列的事件组成。数据库引擎是事件生成者,跟踪控制器负责事件的分发以及事件的过滤, 跟踪会话负责对事件的列过滤以及跟踪事件的终点。本文通过实例解释了这一过程,供读者学习参考。
说到跟踪,很多人会想起SQL Profiler。SQL Profiler仅仅是一个GUI,SQL Trace才是本质。SQL Trace是构建服务器跟踪和Profiler的基础。如果你了解到这点,那你就会毫不犹豫的在生产环境使用服务器跟踪。下面分别从跟踪的代价、跟踪架构、反跟踪和跟踪原则等方面来介绍SQL Trace,并通过一个实例使这些介绍更加的通俗易懂。 一、SQL Trace跟踪的代价 必须指出,跟踪会影响系统的性能这是不可完全避免的。当然可以通过一些方式我们能将这种代价降到最小。很多人往往以跟踪会影响现网性能为理由而拒绝跟踪。其实这是不对的,还有一些人平时也做跟踪,不过他们喜欢在系统不繁忙的时候跟踪。这样的做法都是有问题的。前者往往会出现突然间你的系统出现问题,而你完全没有任何预兆,后者往往会出现你错过捕获问题的最佳时机这样在不繁忙时的跟踪等于白费。 那什么时候对生产环境进行跟踪呢?正确的做法应该是每时每刻的收集系统信息,为对系统性能整体分析提供信息来源。 二、SQL Trace架构 如果你想理解SQL Trace,那最好的方式莫过于用你自己的系统去对比。一般情况下我们都会在系统中记录一些日志,根据我们关注的点来区分记录日志的级别。典型的日志组件就是Log4net之类的日志组件。这样我们就能够通过日志来分析系统的运行情况。知道这点,那理解SQL Trace就容易了。在SQLServer中,跟踪信息由一系列的事件组成。既然有事件,那谁触发事件呢。数据库引擎中的各个组件都是事件的生产者。下面看看SQL Trace的架构图:
如上图所示:整个SQL Trace架构有三个部分组成,数据库引擎、跟踪控制器、跟踪会话。数据库引擎是事件生成者,跟踪控制器负责事件的分发以及事件的过滤,跟踪会话负责对事件的列过滤以及跟踪事件的终点。下面简单描述下整个过程,跟踪控制器通过一个位图让数据库引擎的其他组件知道跟踪器请求了哪些事件,这个位图是所有跟踪的事件集合。一旦数据库引擎生成一个事件后,就把事件信息保存在跟踪控制器中的队列中。然后跟踪控制器把完整的事件信息传递给每个要求这个事件的跟踪会话。跟踪会话接收到自己关注的事件信息时,先经过过滤器(主要是过滤掉不感兴趣的列与行),过滤掉后发送给跟踪的I/O提供者。这里面的队列只是起缓冲作用。I/O提供者有很多种,比如Profiler、服务器跟踪、SQLServer自己的跟踪。 三、具体跟踪例子 这里的例子不想用SQL Profiler进行举例,因为我觉得它仅仅是方便我们跟踪而已。但是它在跟踪时既会把输出写入目标文件或者表(然后选择保存文件中保存表)还有把跟踪信息写入运行Profiler的客户端。把跟踪信息写入到运行Profiler客户端,这个比直接写入文件往往会慢。大家可以想想为什么?不过倒是可以用Profiler图形化方式定义跟踪,然后导出生成的跟踪SQL。具体如下:
一旦你开启了跟踪后,你可以通过: select * from sys.traces 查看到你正在跟踪的会话。
四、如何反跟踪 有时候,我们不希望自己的sql被人跟踪。比如,我们不希望别人能看到我们程序中写的sql。方法有很多,这里介绍一种简单的方法。思路就是:强迫SQLServer停止跟踪。具体存储过程如下: 名称:[DBO].[Performance_Trace_StopAll] 功能:防止反跟踪 作者:junling 创建时间:2011-02-09 项目名称:XXXX 历史记录: 编号 日期 作者 备注 1.0 2011-02-09 junling 创建 代码的执行过程如下:
具体什么时候调用,就是看你具体的情况了。 五、SQL Trace跟踪原则 这里主要列出我们在跟踪时应该注意的事项,或者说按照下面的原则会降低跟踪对生产环境的影响。 1、不要使用Profiler GUI跟踪,如果使用了尽量不要运行在跟踪的SQLServer所在服务器; 2、不要把跟踪数据直接写入表,我们可以采用系统不是很繁忙时才把跟踪信息导入表中(除非你想立刻分析数据); 3、跟踪会有大量的I/O操作,尽量把跟踪文件单独放在物理磁盘中; 4、只选择自己感兴趣的事件,多选一个事件都会带来开销(除非你多选的事件不发生,那样也就没有选择的必要; 5、过滤你的跟踪信息,比如你只对某数据库感兴趣,你只对某些列感兴趣(注意这里仅仅是减少了架构图中的I/O提供者的开销,想想为什么); 6、像XXXXXXStarting之类的事件往往没有太大意义; 7、要注意你跟踪的sql中是否使用了标量函数,对这些sql的跟踪会严重影响性能,每个标量函数每处理一行都会触发事件(如果表很大,这是件很恐怖的事件); 8、只给需要跟踪的用户指定跟踪权限。 (责任编辑:IT) |