MSSQL数据批量插入优化详细
时间:2018-04-22 05:14 来源:linux.it.net.cn 作者:IT
序言
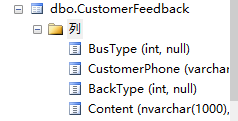
现在有一个需求是将10w条数据插入到MSSQL数据库中,表结构如下,你会怎么做,你感觉插入10W条数据插入到MSSQL如下的表中需要多久呢?
或者你的批量数据是如何插入的呢?我今天就此问题做个探讨。
压测mvc的http接口看下数据
首先说下这里只是做个参照,来理解插入数据库的性能状况,与开篇的需求无半毛钱关系。
mvc接口代码如下:
public bool Add(CustomerFeedbackEntity m)
{
using (var conn=Connection)
{
string sql = @"INSERT INTO [dbo].[CustomerFeedback]
([BusType]
,[CustomerPhone]
,[BackType]
,[Content]
)
VALUES
(@BusType
,@CustomerPhone
,@BackType
,@Content
)";
return conn.Execute(sql, m) > 0;
}
}
压测的此mvc接口单条数据插入数据库的聚合数据图。
用例这样的:5000个请求分500个线程执行post请求接口。

这个图告诉我们,最慢的请求只用啦4毫秒。那么我们做个算法。
如开篇的需求来看,我们用最小的响应时间来计算。
那么插入10w条数据到数据库需用时=100000*4毫秒,大致是6.67分钟。那么我们奔着这个目标来做出插入方案。
最常见的insert做法
首先我们的工程师拿到需求后这样写啦段代码,如下:
//执行数据条数
int cnt = 10 * 10000;
//要插入的数据
CustomerFeedbackEntity m = new CustomerFeedbackEntity() { BusType = 1, CustomerPhone = "1888888888", BackType = 1, Content = "123123dagvhkfhsdjk肯定会撒娇繁华的撒娇防护等级划分噶哈苏德高房价盛大开放" };
//第一种
public void FristWay()
{
using (var conn = new SqlConnection(ConnStr))
{
conn.Open();
Stopwatch sw = new Stopwatch();
sw.Start();
StringBuilder sb = new StringBuilder();
Console.WriteLine("从:" + DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "开始循环执行:" + cnt + "条sql语句 ...");
for (int i = 0; i <= cnt; i++)
{
sb.Clear();
sb.Append(@"INSERT INTO [dbo].[CustomerFeedback]
([BusType]
,[CustomerPhone]
,[BackType]
,[Content]
)
VALUES(");
sb.Append(m.BusType);
sb.Append(",'");
sb.Append(m.CustomerPhone);
sb.Append("',");
sb.Append(m.BackType);
sb.Append(",'");
sb.Append(m.Content);
sb.Append("')");
using (SqlCommand cmd = new SqlCommand(sb.ToString(), conn))
{
cmd.CommandTimeout = 0;
cmd.ExecuteNonQuery();
}
}
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,执行:" + cnt + "条sql语句完成 ! 耗时:" + sw.ElapsedMilliseconds + "毫秒。");
}
}
执行结果如下:

10w条数据,693906毫秒,11分钟,有没有感觉还行,或者还可以接受的。亲们,我是吐血状不说话,继续写,你们看MSSQL数据库与.Net配合插入止于哪里?
点评下:
1、不停的创建与释放sqlcommon对象,会有性能浪费。
2、不停的与数据库建立连接,会有很大的性能损耗。
此2点还有执行结果告诉我们,此种方式不可取,即便这是我们最常见的数据插入方式。
那么我们针对以上两点做优化,1、创建一次sqlcommon对象,只与数据库建立一次连接。优化改造代码如下:
public void SecondWay()
{
using (var conn = new SqlConnection(ConnStr))
{
conn.Open();
Stopwatch sw = new Stopwatch();
sw.Start();
StringBuilder sb = new StringBuilder();
Console.WriteLine("从:" + DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "开始循环拼接:" + cnt + "条sql语句 ...");
for (int i = 0; i <= cnt; i++)
{
sb.Append(@"INSERT INTO [dbo].[CustomerFeedback]
([BusType]
,[CustomerPhone]
,[BackType]
,[Content]
)
VALUES(");
sb.Append(m.BusType);
sb.Append(",'");
sb.Append(m.CustomerPhone);
sb.Append("',");
sb.Append(m.BackType);
sb.Append(",'");
sb.Append(m.Content);
sb.Append("')");
}
var result = sw.ElapsedMilliseconds;
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,循环拼接:" + cnt + "条sql语句完成 ! 耗时:" + result + "毫秒。");
using (SqlCommand cmd = new SqlCommand(sb.ToString(), conn))
{
cmd.CommandTimeout = 0;
Stopwatch sw1 = new Stopwatch();
sw1.Start();
Console.WriteLine("从:" + DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "开始执行:" + cnt + "条sql语句 ...");
cmd.ExecuteNonQuery();
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,执行:" + cnt + "条sql语句完成 ! 耗时:" + sw1.ElapsedMilliseconds + "毫秒。");
}
}
}
执行结果如下:

呀,好奇怪啊,为什么跟上一个方案没有多大区别呢?
首先我们看下拼接这么长的sql语句是怎么在数据库中是怎么执行的。
1、查看数据库的连接情况
select * from sysprocesses where dbid in (select dbid from sysdatabases where name='dbname')
--或者
SELECT * FROM
[Master].[dbo].[SYSPROCESSES] WHERE [DBID] IN ( SELECT
[DBID]
FROM
[Master].[dbo].[SYSDATABASES]
WHERE
NAME='dbname'
)
2、查看数据库正在执行的sql语句
SELECT [Spid] = session_id ,
ecid ,
[Database] = DB_NAME(sp.dbid) ,
[User] = nt_username ,
[Status] = er.status ,
[Wait] = wait_type ,
[Individual Query] = SUBSTRING(qt.text,
er.statement_start_offset / 2,
( CASE WHEN er.statement_end_offset = -1
THEN LEN(CONVERT(NVARCHAR(MAX), qt.text))
* 2
ELSE er.statement_end_offset
END - er.statement_start_offset )
/ 2) ,
[Parent Query] = qt.text ,
Program = program_name ,
hostname ,
nt_domain ,
start_time
FROM sys.dm_exec_requests er
INNER JOIN sys.sysprocesses sp ON er.session_id = sp.spid
CROSS APPLY sys.dm_exec_sql_text(er.sql_handle) AS qt
WHERE session_id > 50 -- Ignore system spids.
AND session_id NOT IN ( @@SPID ) -- Ignore this current statement.
ORDER BY 1 ,
2
点评:虽然看似得到啦优化,其实与上一个解决方案的执行过程几乎是一样的,所以就不用多说什么啦。
利于MSSQL数据库的用户自定义表类型做优化
依旧先上代码,或许这样你才能对用户自定义表类型产生兴趣。
CREATE TYPE CustomerFeedbackTemp AS TABLE(
BusType int NOT NULL,
CustomerPhone varchar(40) NOT NULL,
BackType int NOT NULL,
Content nvarchar(1000) NOT NULL
)
public void ThirdWay()
{
Stopwatch sw = new Stopwatch();
Stopwatch sw1 = new Stopwatch();
DataTable dt = GetTable();
using (var conn = new SqlConnection(ConnStr))
{
string sql = @"INSERT INTO[dbo].[CustomerFeedback]
([BusType]
,[CustomerPhone]
,[BackType]
,[Content]
) select BusType,CustomerPhone,BackType,[Content] from @TempTb";
using (SqlCommand cmd = new SqlCommand(sql, conn))
{
cmd.CommandTimeout = 0;
SqlParameter catParam = cmd.Parameters.AddWithValue("@TempTb", dt);
catParam.SqlDbType = SqlDbType.Structured;
catParam.TypeName = "dbo.CustomerFeedbackTemp";
conn.Open();
Console.WriteLine("从:" + DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "开始循环插入内存表中:" + cnt + "条数据 ...");
sw.Start();
for (int i = 0; i < cnt; i++)
{
DataRow dr = dt.NewRow();
dr[0] = m.BusType;
dr[1] = m.CustomerPhone;
dr[2] = m.BackType;
dr[3] = m.Content;
dt.Rows.Add(dr);
}
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,循环插入内存表:" + cnt + "条数据完成 ! 耗时:" + sw.ElapsedMilliseconds + "毫秒。");
sw1.Start();
if (dt != null && dt.Rows.Count != 0)
{
cmd.ExecuteNonQuery();
sw.Stop();
}
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,执行:" + cnt + "条数据的datatable的数据进数据库 ! 耗时:" + sw1.ElapsedMilliseconds + "毫秒。");
}
}
}
运行结果:

哇抓Q,不到2秒,不到2秒,怎么比每条4毫秒还快,不敢相信,是不是运行出问题啦。
再来一遍

再来一遍

是的你没有看错,10w条数据,不到2秒。是不是迫不及待的要知道为什么?迫不及待的想知道我们用到的用户自定义表类型是什么?
用户自定义表类型
首先类型大家应该很容易理解,像int,varchar,bit等都是类型,那么这个表类型是个毛线呢?
其实他就是用户可以自己定义一个表结构然后把他当作一个类型。
创建自定义类型的详细文档:https://msdn.microsoft.com/zh-cn/library/ms175007.aspx
其次自定义类型也有一些限制,安全性:https://msdn.microsoft.com/zh-cn/library/bb522526.aspx
然后就是如何用这个类型,他的使用就是作为表值参数来使用的。
使用表值参数,可以不必创建临时表或许多参数,即可向 Transact-SQL 语句或例程(如存储过程或函数)发送多行数据。
表值参数与 OLE DB 和 ODBC 中的参数数组类似,但具有更高的灵活性,且与 Transact-SQL 的集成更紧密。 表值参数的另一个优势是能够参与基于数据集的操作。
Transact-SQL 通过引用向例程传递表值参数,以避免创建输入数据的副本。 可以使用表值参数创建和执行 Transact-SQL 例程,并且可以使用任何托管语言从 Transact-SQL 代码、托管客户端以及本机客户端调用它们。
优点
就像其他参数一样,表值参数的作用域也是存储过程、函数或动态 Transact-SQL 文本。 同样,表类型变量也与使用 DECLARE 语句创建的其他任何局部变量一样具有作用域。 可以在动态 Transact-SQL 语句内声明表值变量,并且可以将这些变量作为表值参数传递到存储过程和函数。
表值参数具有更高的灵活性,在某些情况下,可比临时表或其他传递参数列表的方法提供更好的性能。 表值参数具有以下优势:
-
首次从客户端填充数据时,不获取锁。
-
提供简单的编程模型。
-
允许在单个例程中包括复杂的业务逻辑。
-
减少到服务器的往返。
-
可以具有不同基数的表结构。
-
是强类型。
-
使客户端可以指定排序顺序和唯一键。
-
在用于存储过程时像临时表一样被缓存。 从 SQL Server 2012 开始,对于参数化查询,表值参数也被缓存。
限制
表值参数有下面的限制:
-
SQL Server 不维护表值参数列的统计信息。
-
表值参数必须作为输入 READONLY 参数传递到 Transact-SQL 例程。 不能在例程体中对表值参数执行诸如 UPDATE、DELETE 或 INSERT 这样的 DML 操作。
-
不能将表值参数用作 SELECT INTO 或 INSERT EXEC 语句的目标。 表值参数可以在 SELECT INTO 的 FROM 子句中,也可以在 INSERT EXEC 字符串或存储过程中。
常见的BULK INSERT 数据集插入优化
public void FourWay()
{
Stopwatch sw = new Stopwatch();
Stopwatch sw1 = new Stopwatch();
DataTable dt = GetTable();
using (SqlConnection conn = new SqlConnection(ConnStr))
{
SqlBulkCopy bulkCopy = new SqlBulkCopy(conn);
bulkCopy.BulkCopyTimeout = 0;
bulkCopy.DestinationTableName = "CustomerFeedback";
bulkCopy.BatchSize = dt.Rows.Count;
conn.Open();
Console.WriteLine("从:" + DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "开始循环插入内存表中:" + cnt + "条数据 ...");
sw.Start();
for (int i = 0; i < cnt; i++)
{
DataRow dr = dt.NewRow();
dr[0] = m.BusType;
dr[1] = m.CustomerPhone;
dr[2] = m.BackType;
dr[3] = m.Content;
dt.Rows.Add(dr);
}
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,循环插入内存表:" + cnt + "条数据完成 ! 耗时:" + sw.ElapsedMilliseconds + "毫秒。");
sw1.Start();
if (dt != null && dt.Rows.Count != 0)
{
bulkCopy.WriteToServer(dt);
sw.Stop();
}
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,执行:" + cnt + "条数据的datatable的数据进数据库 ! 耗时:" + sw1.ElapsedMilliseconds + "毫秒。");
}
执行结果:




1秒之内完成,1秒之内完成,看完这个简直要在1秒之内完成10w条数据的插入的节奏,逆天,逆天啊。
bulk insert详解:https://msdn.microsoft.com/zh-cn/library/ms188365.aspx
专业的点评:
表值参数的使用方法与其他基于数据集的变量的使用方法相似;但是,频繁使用表值参数将比大型数据集要快。 大容量操作的启动开销比表值参数大,与之相比,表值参数在插入数目少于 1000 的行时具有很好的执行性能。
重用的表值参数可从临时表缓存中受益。 这一表缓存功能可比对等的 BULK INSERT 操作提供更好的伸缩性。 使用小型行插入操作时,可以通过使用参数列表或批量语句(而不是 BULK INSERT 操作或表值参数)来获得小的性能改进。 但是,这些方法在编程上不太方便,并且随着行的增加,性能会迅速下降。
表值参数在执行性能上与对等的参数阵列实现相当甚至更好。
(责任编辑:IT)
序言现在有一个需求是将10w条数据插入到MSSQL数据库中,表结构如下,你会怎么做,你感觉插入10W条数据插入到MSSQL如下的表中需要多久呢? 或者你的批量数据是如何插入的呢?我今天就此问题做个探讨。
压测mvc的http接口看下数据首先说下这里只是做个参照,来理解插入数据库的性能状况,与开篇的需求无半毛钱关系。 mvc接口代码如下:
public bool Add(CustomerFeedbackEntity m)
{
using (var conn=Connection)
{
string sql = @"INSERT INTO [dbo].[CustomerFeedback]
([BusType]
,[CustomerPhone]
,[BackType]
,[Content]
)
VALUES
(@BusType
,@CustomerPhone
,@BackType
,@Content
)";
return conn.Execute(sql, m) > 0;
}
}
压测的此mvc接口单条数据插入数据库的聚合数据图。 用例这样的:5000个请求分500个线程执行post请求接口。
这个图告诉我们,最慢的请求只用啦4毫秒。那么我们做个算法。 如开篇的需求来看,我们用最小的响应时间来计算。 那么插入10w条数据到数据库需用时=100000*4毫秒,大致是6.67分钟。那么我们奔着这个目标来做出插入方案。 最常见的insert做法首先我们的工程师拿到需求后这样写啦段代码,如下:
//执行数据条数
int cnt = 10 * 10000;
//要插入的数据
CustomerFeedbackEntity m = new CustomerFeedbackEntity() { BusType = 1, CustomerPhone = "1888888888", BackType = 1, Content = "123123dagvhkfhsdjk肯定会撒娇繁华的撒娇防护等级划分噶哈苏德高房价盛大开放" };
//第一种
public void FristWay()
{
using (var conn = new SqlConnection(ConnStr))
{
conn.Open();
Stopwatch sw = new Stopwatch();
sw.Start();
StringBuilder sb = new StringBuilder();
Console.WriteLine("从:" + DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "开始循环执行:" + cnt + "条sql语句 ...");
for (int i = 0; i <= cnt; i++)
{
sb.Clear();
sb.Append(@"INSERT INTO [dbo].[CustomerFeedback]
([BusType]
,[CustomerPhone]
,[BackType]
,[Content]
)
VALUES(");
sb.Append(m.BusType);
sb.Append(",'");
sb.Append(m.CustomerPhone);
sb.Append("',");
sb.Append(m.BackType);
sb.Append(",'");
sb.Append(m.Content);
sb.Append("')");
using (SqlCommand cmd = new SqlCommand(sb.ToString(), conn))
{
cmd.CommandTimeout = 0;
cmd.ExecuteNonQuery();
}
}
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,执行:" + cnt + "条sql语句完成 ! 耗时:" + sw.ElapsedMilliseconds + "毫秒。");
}
}
执行结果如下:
10w条数据,693906毫秒,11分钟,有没有感觉还行,或者还可以接受的。亲们,我是吐血状不说话,继续写,你们看MSSQL数据库与.Net配合插入止于哪里? 点评下: 1、不停的创建与释放sqlcommon对象,会有性能浪费。 2、不停的与数据库建立连接,会有很大的性能损耗。 此2点还有执行结果告诉我们,此种方式不可取,即便这是我们最常见的数据插入方式。 那么我们针对以上两点做优化,1、创建一次sqlcommon对象,只与数据库建立一次连接。优化改造代码如下:
public void SecondWay()
{
using (var conn = new SqlConnection(ConnStr))
{
conn.Open();
Stopwatch sw = new Stopwatch();
sw.Start();
StringBuilder sb = new StringBuilder();
Console.WriteLine("从:" + DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "开始循环拼接:" + cnt + "条sql语句 ...");
for (int i = 0; i <= cnt; i++)
{
sb.Append(@"INSERT INTO [dbo].[CustomerFeedback]
([BusType]
,[CustomerPhone]
,[BackType]
,[Content]
)
VALUES(");
sb.Append(m.BusType);
sb.Append(",'");
sb.Append(m.CustomerPhone);
sb.Append("',");
sb.Append(m.BackType);
sb.Append(",'");
sb.Append(m.Content);
sb.Append("')");
}
var result = sw.ElapsedMilliseconds;
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,循环拼接:" + cnt + "条sql语句完成 ! 耗时:" + result + "毫秒。");
using (SqlCommand cmd = new SqlCommand(sb.ToString(), conn))
{
cmd.CommandTimeout = 0;
Stopwatch sw1 = new Stopwatch();
sw1.Start();
Console.WriteLine("从:" + DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "开始执行:" + cnt + "条sql语句 ...");
cmd.ExecuteNonQuery();
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,执行:" + cnt + "条sql语句完成 ! 耗时:" + sw1.ElapsedMilliseconds + "毫秒。");
}
}
}
执行结果如下:
呀,好奇怪啊,为什么跟上一个方案没有多大区别呢? 首先我们看下拼接这么长的sql语句是怎么在数据库中是怎么执行的。 1、查看数据库的连接情况 select * from sysprocesses where dbid in (select dbid from sysdatabases where name='dbname') --或者 SELECT * FROM [Master].[dbo].[SYSPROCESSES] WHERE [DBID] IN ( SELECT [DBID] FROM [Master].[dbo].[SYSDATABASES] WHERE NAME='dbname' ) 2、查看数据库正在执行的sql语句
SELECT [Spid] = session_id ,
ecid ,
[Database] = DB_NAME(sp.dbid) ,
[User] = nt_username ,
[Status] = er.status ,
[Wait] = wait_type ,
[Individual Query] = SUBSTRING(qt.text,
er.statement_start_offset / 2,
( CASE WHEN er.statement_end_offset = -1
THEN LEN(CONVERT(NVARCHAR(MAX), qt.text))
* 2
ELSE er.statement_end_offset
END - er.statement_start_offset )
/ 2) ,
[Parent Query] = qt.text ,
Program = program_name ,
hostname ,
nt_domain ,
start_time
FROM sys.dm_exec_requests er
INNER JOIN sys.sysprocesses sp ON er.session_id = sp.spid
CROSS APPLY sys.dm_exec_sql_text(er.sql_handle) AS qt
WHERE session_id > 50 -- Ignore system spids.
AND session_id NOT IN ( @@SPID ) -- Ignore this current statement.
ORDER BY 1 ,
2
点评:虽然看似得到啦优化,其实与上一个解决方案的执行过程几乎是一样的,所以就不用多说什么啦。 利于MSSQL数据库的用户自定义表类型做优化依旧先上代码,或许这样你才能对用户自定义表类型产生兴趣。 CREATE TYPE CustomerFeedbackTemp AS TABLE( BusType int NOT NULL, CustomerPhone varchar(40) NOT NULL, BackType int NOT NULL, Content nvarchar(1000) NOT NULL )
public void ThirdWay()
{
Stopwatch sw = new Stopwatch();
Stopwatch sw1 = new Stopwatch();
DataTable dt = GetTable();
using (var conn = new SqlConnection(ConnStr))
{
string sql = @"INSERT INTO[dbo].[CustomerFeedback]
([BusType]
,[CustomerPhone]
,[BackType]
,[Content]
) select BusType,CustomerPhone,BackType,[Content] from @TempTb";
using (SqlCommand cmd = new SqlCommand(sql, conn))
{
cmd.CommandTimeout = 0;
SqlParameter catParam = cmd.Parameters.AddWithValue("@TempTb", dt);
catParam.SqlDbType = SqlDbType.Structured;
catParam.TypeName = "dbo.CustomerFeedbackTemp";
conn.Open();
Console.WriteLine("从:" + DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "开始循环插入内存表中:" + cnt + "条数据 ...");
sw.Start();
for (int i = 0; i < cnt; i++)
{
DataRow dr = dt.NewRow();
dr[0] = m.BusType;
dr[1] = m.CustomerPhone;
dr[2] = m.BackType;
dr[3] = m.Content;
dt.Rows.Add(dr);
}
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,循环插入内存表:" + cnt + "条数据完成 ! 耗时:" + sw.ElapsedMilliseconds + "毫秒。");
sw1.Start();
if (dt != null && dt.Rows.Count != 0)
{
cmd.ExecuteNonQuery();
sw.Stop();
}
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,执行:" + cnt + "条数据的datatable的数据进数据库 ! 耗时:" + sw1.ElapsedMilliseconds + "毫秒。");
}
}
}
运行结果:
哇抓Q,不到2秒,不到2秒,怎么比每条4毫秒还快,不敢相信,是不是运行出问题啦。 再来一遍
再来一遍
是的你没有看错,10w条数据,不到2秒。是不是迫不及待的要知道为什么?迫不及待的想知道我们用到的用户自定义表类型是什么? 用户自定义表类型首先类型大家应该很容易理解,像int,varchar,bit等都是类型,那么这个表类型是个毛线呢? 其实他就是用户可以自己定义一个表结构然后把他当作一个类型。 创建自定义类型的详细文档:https://msdn.microsoft.com/zh-cn/library/ms175007.aspx 其次自定义类型也有一些限制,安全性:https://msdn.microsoft.com/zh-cn/library/bb522526.aspx 然后就是如何用这个类型,他的使用就是作为表值参数来使用的。 使用表值参数,可以不必创建临时表或许多参数,即可向 Transact-SQL 语句或例程(如存储过程或函数)发送多行数据。 表值参数与 OLE DB 和 ODBC 中的参数数组类似,但具有更高的灵活性,且与 Transact-SQL 的集成更紧密。 表值参数的另一个优势是能够参与基于数据集的操作。 Transact-SQL 通过引用向例程传递表值参数,以避免创建输入数据的副本。 可以使用表值参数创建和执行 Transact-SQL 例程,并且可以使用任何托管语言从 Transact-SQL 代码、托管客户端以及本机客户端调用它们。 优点 就像其他参数一样,表值参数的作用域也是存储过程、函数或动态 Transact-SQL 文本。 同样,表类型变量也与使用 DECLARE 语句创建的其他任何局部变量一样具有作用域。 可以在动态 Transact-SQL 语句内声明表值变量,并且可以将这些变量作为表值参数传递到存储过程和函数。 表值参数具有更高的灵活性,在某些情况下,可比临时表或其他传递参数列表的方法提供更好的性能。 表值参数具有以下优势:
限制 表值参数有下面的限制:
常见的BULK INSERT 数据集插入优化
public void FourWay()
{
Stopwatch sw = new Stopwatch();
Stopwatch sw1 = new Stopwatch();
DataTable dt = GetTable();
using (SqlConnection conn = new SqlConnection(ConnStr))
{
SqlBulkCopy bulkCopy = new SqlBulkCopy(conn);
bulkCopy.BulkCopyTimeout = 0;
bulkCopy.DestinationTableName = "CustomerFeedback";
bulkCopy.BatchSize = dt.Rows.Count;
conn.Open();
Console.WriteLine("从:" + DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "开始循环插入内存表中:" + cnt + "条数据 ...");
sw.Start();
for (int i = 0; i < cnt; i++)
{
DataRow dr = dt.NewRow();
dr[0] = m.BusType;
dr[1] = m.CustomerPhone;
dr[2] = m.BackType;
dr[3] = m.Content;
dt.Rows.Add(dr);
}
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,循环插入内存表:" + cnt + "条数据完成 ! 耗时:" + sw.ElapsedMilliseconds + "毫秒。");
sw1.Start();
if (dt != null && dt.Rows.Count != 0)
{
bulkCopy.WriteToServer(dt);
sw.Stop();
}
Console.WriteLine(DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss fff") + "时,执行:" + cnt + "条数据的datatable的数据进数据库 ! 耗时:" + sw1.ElapsedMilliseconds + "毫秒。");
}
执行结果:
1秒之内完成,1秒之内完成,看完这个简直要在1秒之内完成10w条数据的插入的节奏,逆天,逆天啊。 bulk insert详解:https://msdn.microsoft.com/zh-cn/library/ms188365.aspx 专业的点评: 表值参数的使用方法与其他基于数据集的变量的使用方法相似;但是,频繁使用表值参数将比大型数据集要快。 大容量操作的启动开销比表值参数大,与之相比,表值参数在插入数目少于 1000 的行时具有很好的执行性能。 重用的表值参数可从临时表缓存中受益。 这一表缓存功能可比对等的 BULK INSERT 操作提供更好的伸缩性。 使用小型行插入操作时,可以通过使用参数列表或批量语句(而不是 BULK INSERT 操作或表值参数)来获得小的性能改进。 但是,这些方法在编程上不太方便,并且随着行的增加,性能会迅速下降。 表值参数在执行性能上与对等的参数阵列实现相当甚至更好。 (责任编辑:IT) |