DeepSeek 提出新的注意力机制:原生稀疏注意力 (NSA),创始人亲自提交论文
时间:2025-02-20 10:47 来源:未知 作者:IT
2 月 18 日,DeepSeek 官方发文公布了一篇新的论文,论文提出了一种新的注意力机制「NSA」。
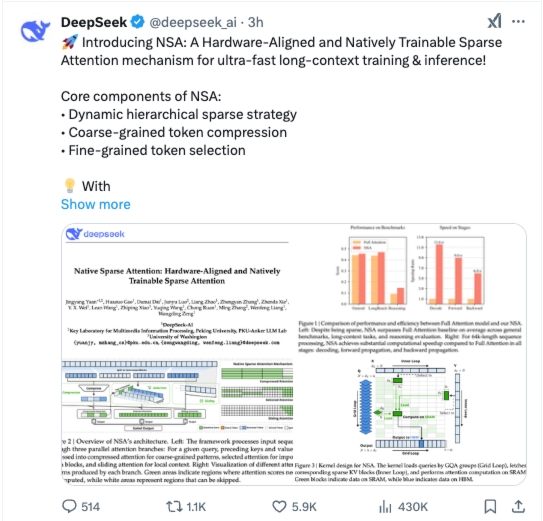
据 DeepSeek 介绍,「原生稀疏注意力 (Native Sparse Attention, NSA) 」是一个用于超快长上下文训练和推断的本地可训练的稀疏注意力机制,并且还具有与硬件对齐的特点。
论文摘要:
长文本建模对下一代语言模型来说至关重要,但标准注意力机制的高计算成本带来了显著的计算挑战。稀疏注意力为提高效率同时保持模型能力提供了一个有前景的方向。我们提出了 NSA(原生稀疏注意力),这是一个将算法创新与硬件对齐优化相结合的、原生可训练的稀疏注意力机制,用于实现高效的长文本建模。

NSA 核心组件包括:
-
动态分层稀疏策略
-
粗粒度 token 压缩
-
细粒度 token 选择
研究通过对现实世界语言语料库的综合实验来评估 NSA。其中作者评估了 NSA 在通用语言评估、长上下文评估和链式推理评估中的表现。实验结果表明,NSA 实现了与 Full Attention 基线相当或更优的性能,同时优于现有的稀疏注意力方法。
此外,与 Full Attention 相比,NSA 在解码、前向和后向阶段提供了明显的加速,且加速比随着序列长度的增加而增加。这些结果验证了分层稀疏注意力设计有效地平衡了模型能力和计算效率。
另外,有网友发现,arXiv 上 NSA 这篇论文的提交记录显示,它于 2 月 16 日提交,提交者正是梁文锋本人,他也是这篇论文的合著者。

(责任编辑:IT)
2 月 18 日,DeepSeek 官方发文公布了一篇新的论文,论文提出了一种新的注意力机制「NSA」。 据 DeepSeek 介绍,「原生稀疏注意力 (Native Sparse Attention, NSA) 」是一个用于超快长上下文训练和推断的本地可训练的稀疏注意力机制,并且还具有与硬件对齐的特点。
NSA 核心组件包括:
研究通过对现实世界语言语料库的综合实验来评估 NSA。其中作者评估了 NSA 在通用语言评估、长上下文评估和链式推理评估中的表现。实验结果表明,NSA 实现了与 Full Attention 基线相当或更优的性能,同时优于现有的稀疏注意力方法。 此外,与 Full Attention 相比,NSA 在解码、前向和后向阶段提供了明显的加速,且加速比随着序列长度的增加而增加。这些结果验证了分层稀疏注意力设计有效地平衡了模型能力和计算效率。 另外,有网友发现,arXiv 上 NSA 这篇论文的提交记录显示,它于 2 月 16 日提交,提交者正是梁文锋本人,他也是这篇论文的合著者。
|