|
作者|阿里资源管理技术专家杨仪
刚刚过去的 2018 年天猫“双11”,创下了全天 2135 亿 GMV 的数字奇迹,零点交易峰值比往年提升 50%,各项指标均创下历史新高。
2018 年是“双11”的第十年,也是阿里系统软件事业部参与的第二个“双11”,系统软件是介于业务应用和 IDC、网络、服务器之间的核心关键层,为阿里巴巴集团在线业务提供基础的操作系统、资源调度、SRE、JVM 等领域重要的基础设施。
经过两年“双11”的精心淬炼,系统软件事业部与其他兄弟 BU 并肩作战,逐步提升了阿里巴巴在基础软件领域的技术深度。阿里系统软件是如何应对“双11”流量峰值的呢?以下为大家一一揭晓。
“双11”面临的挑战
双11的核心是稳定压倒一切,如何确保各个系统在峰值流量下的稳定性成为重中之重,系统软件作为阿里巴巴的基础设施底盘,今年主要面临如下挑战:
在去年双11的完美表现的基础上,今年双11的稳定性不容有失,从内核到业务层保障,所有基础设施必须保障绝对稳定;
大量新技术如规模化混部演进给集团带来技术进步的同时,给系统和业务带来不确定的技术风险;
如何在保障业务稳定性的同时,确保成本最低,是业务给系统软件提出的更高要求;
系统软件双11备战回顾
双11备战之资源交付
面向终态的站点交付
众所周知,阿里巴巴的交易系统采用了异地多活的灾容架构,当大促来临前,需要在多个地域快速交付多个站点,通过全链路压测平台进行站点能力验证。借助于阿里巴巴资源快速弹性的能力,从交付使用到站点压测,需要在短短10多天时间内完成多个站点的快速交付,无疑是一个巨大的挑战。
为了提升整体建站的效率,确保站点高质量交付,系统软件建站团队对建站链路进行了全面的方案优化和升级如下:
全生命周期业务集群管控
包括 0->1(建站)、1->N/N->1(弹性伸缩/快上快下)、1->0(站点下线);弹性伸缩范围包括接入层、中间件、Tair 及应用全链路。
无缝对接容量模型
单元化应用分组自动识别,应用弹性结合预算产出容量模型,对接中间件等容量模型,交易笔数->建站范围及资源需求。
规模化资源编排
基于 Sigma 的规模化场景资源编排,最小化资源碎片,节省资源,通过实际验证,资源分配率达到 98%。
自动化业务回归
各 BU 自动化业务回归,例如基于天启/doom、全链路压测、×××等。
资源运营降低大促成本
根据准确测算,2018年大促每万笔交易成本比去年下降20%;这里面除了混部技术的大规模运用、云化等因素外,还需要在资源运营层面进行一系列优化,其中的重点就是打造一套资源全生命周期管理的资源运营平台,实现资源快速交付和资源最大化利用。
资源交付体系建设
在资源交付链路上,资源运营团队对额度系统进行重构升级,将面向时间的额度系统升级为面向当前账户的额度体系,应用负责人可以自由地在应用之间进行额度转移,极大地提升了资源交付效率;此外,我们基于一系列的容量规划和算法预测,实现了大量业务的分时复用,将大量不参与大促的业务的资源提前释放,用于支撑大促需求。
基于系统化的资源运营方式,集团资源运营的效率和利用率大幅提升,有效地防止了资源泄露和资源闲置,真正实现了大促成本不增加,为阿里集团节省了亿级别采购成本。
双11备战之调度备战
大规模混部技术应用
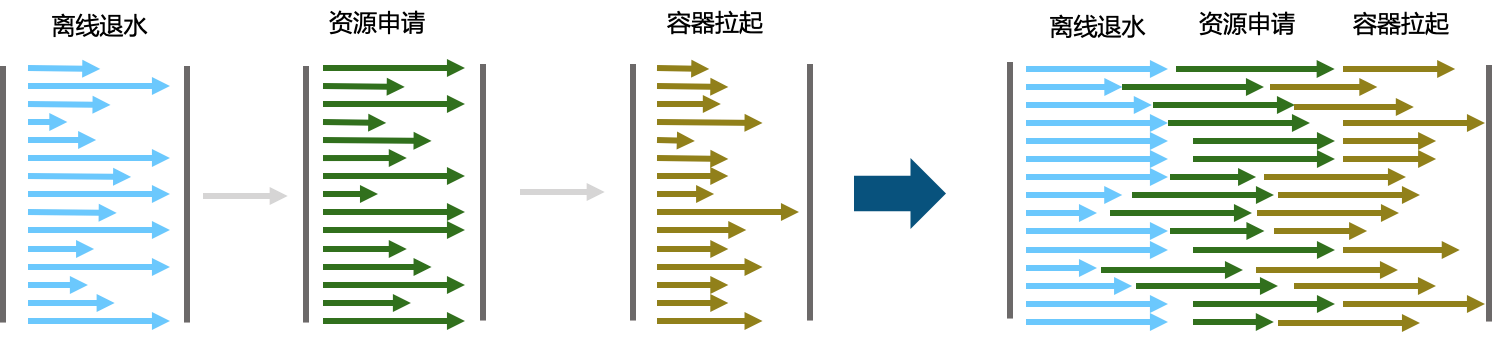
2017年双11,阿里巴巴的混部技术在大促零点成功得到验证,今年双11混部的量级扩大到去年的3倍;在这个大目标下,混部团队对现有架构进行了升级,在离线调度器伏羲和在线调度器sigma之上演化出一个总体的资源协调者0层,主要承载离线和在线资源记账、区分优先级的资源分配和总体协调的作用,可以把它形象的看成是一个大的账本,上面的每一条记录便是某台机器上cpu/mem/io资源如何划分给在线和离线业务,从而解决混部环境在线和离混资源的资源分配问题。
在混部业务稳定性保障方面,通过对两类资源(CPU和MEM)按优先级划分的策略进行使用,其中以CPU资源为例划分为三个级别,分别为金牌,CPU采用绑核模式具有最高优调度抢占优先级;银牌,在线和离线高优先级任务使用,离线银牌资源不会被在线任务驱赶,保障调度优先级和稳定性;铜牌,离线大部分worker申请铜牌资源使用。在线S10和S20需要使用CPU时可以驱赶离线铜牌对CPU核的占用,实现资源充足时离线成分用满,资源紧张时在线能及时抢占的效果。
得益于前文所述的新混部调度框架,0层和1层调度间的资源配合有了一个明显提升,去年的混部方案中,0层只保留静态的集群或单机资源配比,并且比例生效都是通过外部人为设置,而今年0层精细化单机账本之后,每台单机的配比则交给fuxi和sigma自动调整,按照容器所需资源比例进行设置。借助于资源配比的按需调整功能,快上快下也实现了完全自动化的流程驱动。
混部快上快下是指在大促过程中,离线快速地资源释放给在线或在线快速给归还资源给离线的过程;自动化流程完美的实现了规模化混部目标,通过完整链路优化,最终实现了快上2小时,快下1小时的时间目标,也正是如此快速的资源伸缩操作保障了离线业务在资源相对紧缺的情况下安全顺滑支持规模性压测及双11大促的完整支持。
今年双11,有超过50%的流量运行在混部集群;其中离在线混部(即离线提供资源给在线交易使用)支撑了40%的交易流量;在离线混部(即在线出让部分资源用于离线任务运行)一共部署约了数千台机器资源,为离线业务团队减少数千台机器采购。
Sigma调度能力升级
sigma是阿里巴巴自研的资源调度器,调度引擎是Sigma调度的核心,调度引擎的优劣,直接决定了其调度的业务的稳定性。今年调度能力升级主要做了以下几方面工作:
业务运行时保障
今年调度引擎团队首次提出了资源确定性的SLO目标,将业务方关心的资源争抢、超卖、CPU核重叠等容器运行时的稳定作为第一优先级任务解决,在确保核心应用CPU逻辑核不堆叠的前提下,满足了同应用不同容器和同容器对端核争抢的需求,从而提升了资源稳定性。
引擎升级
新版Sigma 调度器在原有基础上进行了重新设计和架构升级,兼容开源kubernetes框架,在数万笔交易容量集群上得到了大规模验证。
Pouch容器
今年双11,超过10%的物理机上线了pouch开源回迁版本,为探索阿里内外使用同一个容器打下基础。同时,容器团队还在Containerd-1.0 方面做了大量的性能优化/锁优化/定时任务CPU优化,确保容器运行时稳定。
CpuShare精细化资源分配
CpuShare是一种基于linux cgroup对应用的cpu和内存进行精细化的控制和使用的技术,双11前在线资源池整体share容器数占比10%,其中核⼼应⽤5%,次核⼼应⽤10%,非核⼼应⽤20%+。
大促云化
大促云化是指大促时通过短时间使用阿里云的计算能力,大促峰值过后将资源释放归还给公共云继续售卖的一种资源使用方式。
大促云化的本质是资源的云化,包括计算资源、网络、IDC、服务器全部基于阿里云的底层技术,从2014年提出大促云化后,大促云化方案经过了多次升级改进,通过vpc网络打通云上云下互访,实现大促过后直接释放资源即可直接售卖,从而减少资源占用时长和改造成本。
全量使用公共云方案,网络层通过VPC方案实现公共云环境与弹内环境互通;通过使用阿里云的ECS buffer,减少交易的资源采购;
计算存储分离,使用阿里云的盘古做为远程盘存储,大大减小物理机本盘,降低了大促资源成本;
此外,在应用、中间件、数据库层面大规模部署神龙云服务器,总体效果良好。
大规模计算存储分离
2018年是计算存储分离破局之年,基于盘古远程盘,部署了数千台在线宿主机,超过50%的集群使用了存储计算分离技术,这项技术有望大幅减少未来阿里集团在服务器SSD盘的硬件成本投入。
双11备战之内核备战
内核是系统运行的基础,今年内核团队的备战主要集中在以下两个方面:
4.9 版本内核部署
Linus Torvalds在2016年12月11日发布了Linux内核4.9的正式版本,由于4.9新内核修复了大量老内核已知bug,4.9版本的操作系统比目前版本相比稳定性更高,宕机率也有明显下降;目前装机量达到数十万台级别,双11交易集群约90%的交易部署在4.9内核环境,未来将继续扩大新内核的升级。
混部环境内核调优
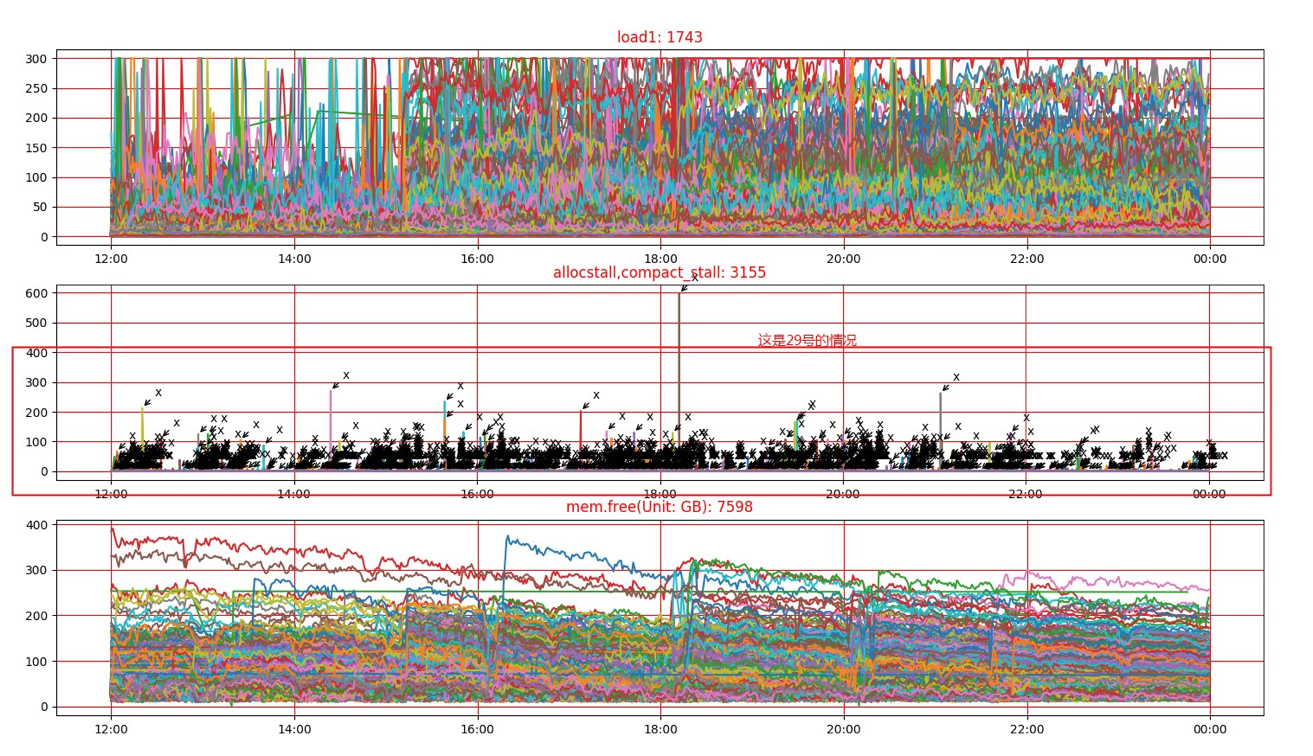
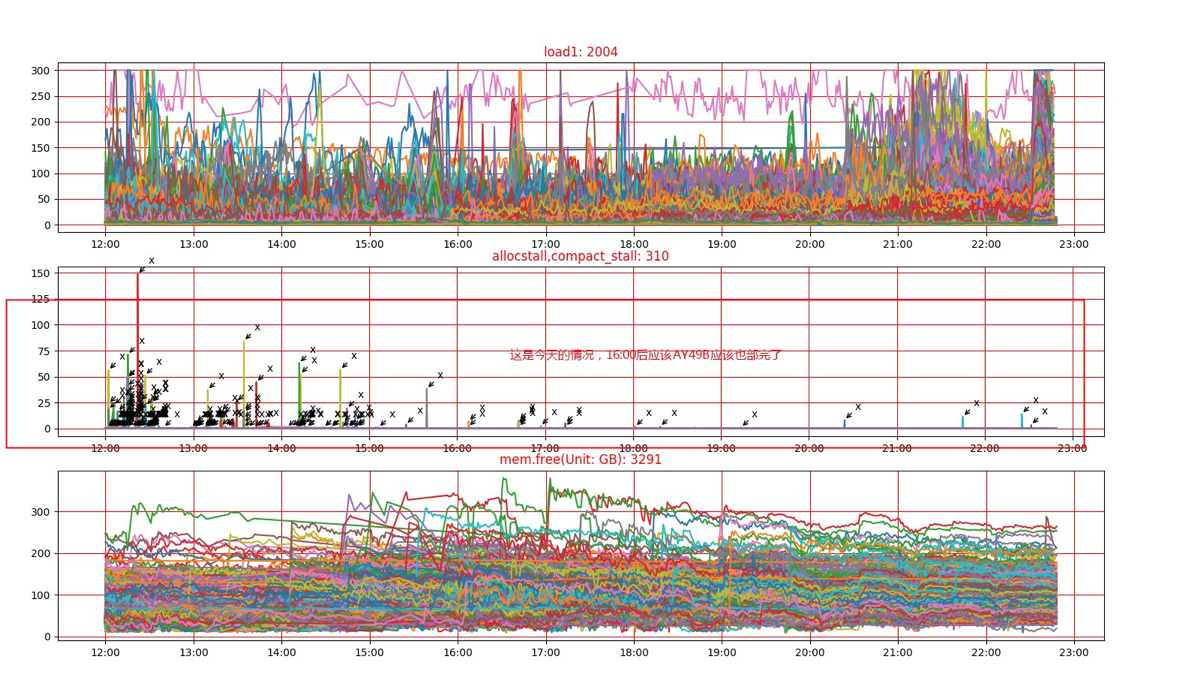
离线和在线混部的集群中,由于宿主机整体资源有限,如何避免离线任务的运行对在线任务造成影响,成为业界难题;今年混部实施以来,发现混部任务调度到在线宿主机后在线业务频繁反馈容器及宿主机load高或CPU sys高的情况;经过内核团队介入排查,发布宿主机内存文件缓存过大,申请新内存时触发整机内存直接回收,导致系统开销大;优化思路:调整整机内存后台回收值(调整内存水线,提高内存Normal Zone的LOW/HIGH水线),提前回收文件缓存页面,避免内核进入直接回收流程。
补丁前:MIN=8G, LOW=10G, HIGH=12G,LOW与MIN之间只有2G,当应用分配大量内存时,kswap还没来得及后台回收,系统内存就低于8G,这时应用只能进入direct reclaim,直接去回收。
补丁后:MIN=8G,LOW=25G,HIGH=27G
双11备战之JVM备战
JVM协程(wisp)
JVM协程今年部署范围交易核心应用扩大到导购,大促期间整体某导购核心应用水位从去年30%提升到今年的60%,业务没有新增机器。
ZenGC
TenureAlloc
部分核心应用默认开启ZenGC,GC暂停改善50%;
GCIH2.0
核心应用部署GCIH2.0,在安全性和性能上进行了改进,GC暂停时间最多改进20+%。
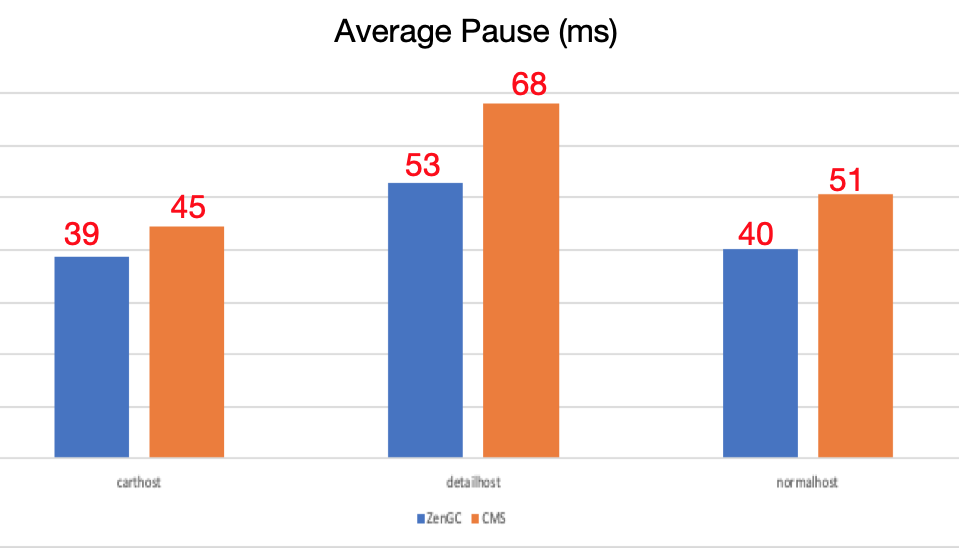
ElasticHeap动态堆内存
双十一0点之前低流量时降低Java进程内存20%+,双十一0点迅速恢复Java堆全量使用,峰值过后,继续缩小Java堆,减少进程内存20%+,99%和最大暂停大幅好于CMS,CMS为G1的150%~5X。
EarlyOldScavenge
在Lindorm Velocity证,大幅减少Concurrent GC从1天30+次,减少为1天1次,推算堆增长率减少95%以上。
(责任编辑:IT) |