|
一、引言 Hadoop是一种分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力高速运算和存储。Hadoop 1.2.1版本下载地址:http://apache.dataguru.cn/hadoop/common/hadoop-1.2.1/ 二、准备安装环境 我的本机是环境是windows8.1系统 +VMvare9虚拟机。VMvare中虚拟了3个ubuntu 12.10的系统,JDK版本为1.7.0_17.集群环境为一个master,两个slave,节点代号分别为node1,node2,node3.保证以下ip地址可以相互ping通,并且在/etc/hosts中进行配置
三、安装环境 1、首先修改机器名 使用root权限,使用命令:
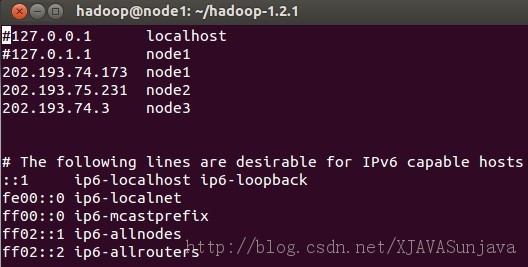
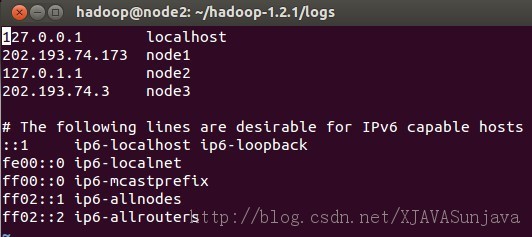
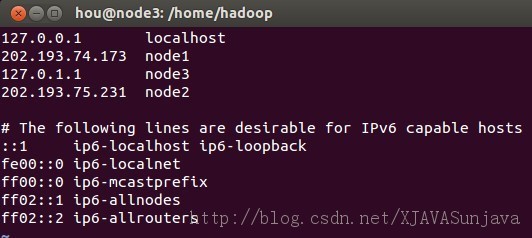
其中node1、node2、node3的/etc/hosts配置为:
/etc/hosts的配置很重要,如果配置的不合适会出各种问题,会影响到后面的SSH配置以及Hadoop的DataNode节点的启动。 2、安装JDK Ubuntu下的JDK配置请参考: http://developer.51cto.com/art/200907/135215.htm 3、添加用户 在root权限下使用以下命令添加hadoop用户,在三个虚拟机上都添加这个用户
将下载到的hadoop-1.2.1.tar文件放到/home/hadoop/目录下解压,然后修改解压后的文件夹的权限,命令如下:
4、安装和配置SSH 4.1)在三台实验机器上使用以下命令安装ssh:
安装以后执行测试:
输入当前用户名和密码按回车确认,说明安装成功,同时ssh登陆需要密码。 这种默认安装方式完后,默认配置文件是在/etc/ssh/目录下。sshd配置文件是:/etc/ssh/sshd_config 4.2)配置SSH无密码访问 在Hadoop启动以后,Namenode是通过SSH(Secure Shell)来启动和停止各个datanode上的各种守护进程的,这就须要在节点之间执行指令的时候是不须要输入密码的形式,故我们须要配置SSH运用无密码公钥认证的形式。 以本文中的三台机器为例,现在node1是主节点,他须要连接node2和node3。须要确定每台机器上都安装了ssh,并且datanode机器上sshd服务已经启动。 ( 说明:hadoop@hadoop~]$ssh-keygen -t rsa 这个命令将为hadoop上的用户hadoop生成其密钥对,询问其保存路径时直接回车采用默认路径,当提示要为生成的密钥输入passphrase的时候,直接回车,也就是将其设定为空密码。生成的密钥对id_rsa,id_rsa.pub,默认存储在/home/hadoop/.ssh目录下然后将id_rsa.pub的内容复制到每个机器(也包括本机)的/home/dbrg/.ssh/authorized_keys文件中,如果机器上已经有authorized_keys这个文件了,就在文件末尾加上id_rsa.pub中的内容,如果没有authorized_keys这个文件,直接复制过去就行.) (责任编辑:IT) |