|
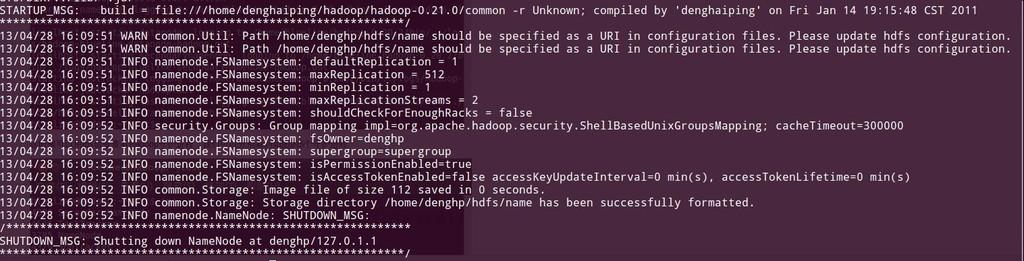
一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。 最近有对hadoop进行简单研究,为了以后方便,把简单的伪分布式环境搭建给记录下来: 硬件、软件准备Ubuntu12.04,Java环境 安装过程1、安装ssh、设置免密码登录 $ sudo apt-get install ssh $ sudo apt-get install rsync 2、配置免密码ssh登录 $ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 配置完后,执行一下 ssh localhost, 确认你的机器可以用 SSH 连接,并且连接时不需要手工输入密码。 3、安装Hadoop (1)、hadoop包含三个部分:Hadoop Common,HDFS,Hadoop MapReduce (2)、下载Hadoop稳定的发行版本。下载地址http://hadoop.apache.org/common/releases.html (3)、配置Hadoop环境变量$HADOOP_HOME $ sudo vim /etc/profile #添加如下配置 HADOOP_HOME=/home/denghp/hadoop-0.21.0 export HADOOP_HOME export HADOOP=$HADOOP_HOME/bin export PATH=$HADOOP:$PATH (4)、修改hadoop配置 hadoop配置文件,在hadoop的conf文件夹中,hadoop的所有配置文件都在里面,这里主要关注以下几个配置文件: 根据提示添加JAVA环境变量JAVA_HOME $ vi hadoop-env.sh # The java implementation to use. Required. export JAVA_HOME=/home/denghp/software/jdk1.6.0_30 (5)、伪分布式配置 Hadoop可以在单节点上以所谓的伪分布式模式运行,此时每一个Hadoop守护进程都作为一个独立的Java进程运行。 core-site.xml配置如下: <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration> hdfs-site.xml配置如下: <configuration> <property> <name>dfs.name.dir</name> <value>/home/denghp/hdfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/home/denghp/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration> mapred-site.xml配置如下: <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration> 启动伪分布式hadoop1、格式化一个新的文件系统,挂载 $ hadoop namenode -format
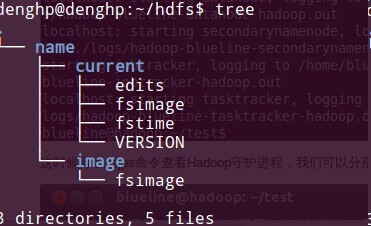
namenode -format 这是第一需要做的初始化之后产生如下文件:
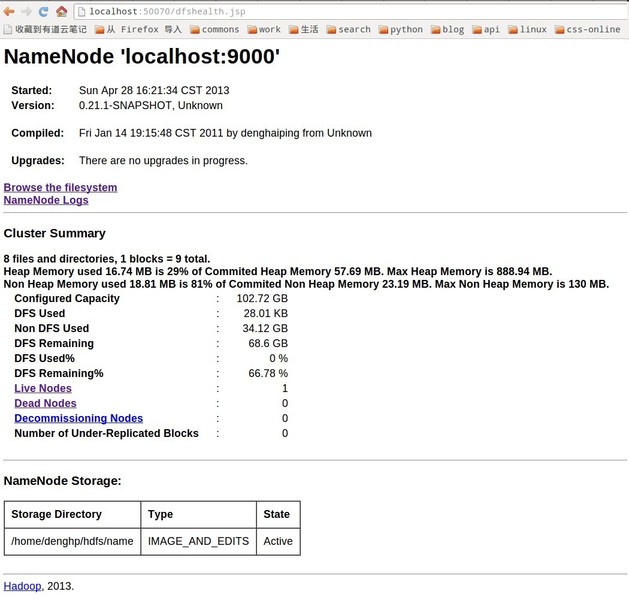
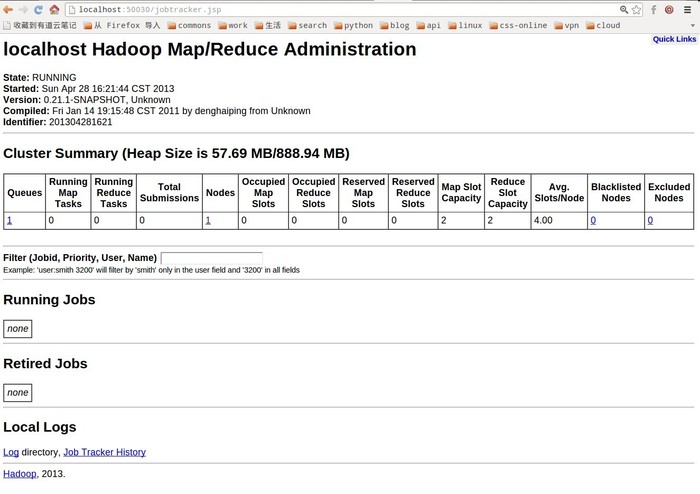
2、因为我们把hadoop的已经配置到环境变量中了,所以我们可以在任何目录下执行hadoop的start-all.sh,启动hadoop守护进程 denghp@denghp:~/software/hadoop-0.21.0$ start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-mapred.sh starting namenode, logging to /home/denghp/software/hadoop-0.21.0/bin/../logs/hadoop-denghp-namenode-denghp.out localhost: starting datanode, logging to /home/denghp/software/hadoop-0.21.0/bin/../logs/hadoop-denghp-datanode-denghp.out localhost: starting secondarynamenode, logging to /home/denghp/software/hadoop-0.21.0/bin/../logs/hadoop-denghp-secondarynamenode-denghp.out starting jobtracker, logging to /home/denghp/software/hadoop-0.21.0/bin/../logs/hadoop-denghp-jobtracker-denghp.out localhost: starting tasktracker, logging to /home/denghp/software/hadoop-0.21.0/bin/../logs/hadoop-denghp-tasktracker-denghp.out 3、查看启动状态 $ jps 17268 TaskTracker 17473 Jps 16848 SecondaryNameNode 16241 NameNode 16545 DataNode 16971 JobTracker 2859 Main 4、通过界面查看NameNode,JobTracker NameNode-- http://localhost:50070 JobTracker-- http://localhost:50030 NameNode
Jobtracker
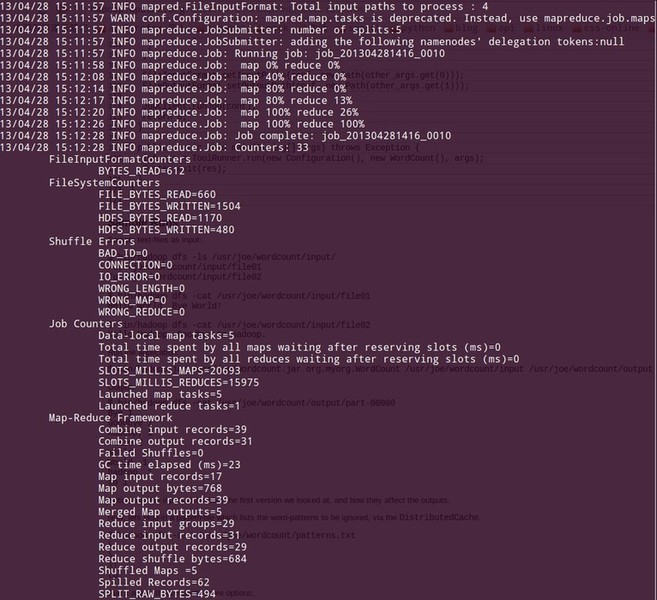
运行MapReduce Tutorial的例子1、将input文件夹及文件copy到hdfs $ hadoop fs -copyFromLocal input input 2、查看拷贝上去的文件 $ hadoop fs -ls input 13/04/28 16:46:26 INFO security.Groups: Group mapping impl=org.apache.hadoop.security.ShellBasedUnixGroupsMapping; cacheTimeout=300000 13/04/28 16:46:26 WARN conf.Configuration: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id Found 4 items -rw-r--r-- 1 denghp supergroup 28 2013-04-28 16:46 /user/denghp/input/input-1.txt -rw-r--r-- 1 denghp supergroup 36 2013-04-28 16:46 /user/denghp/input/input.txt -rw-r--r-- 1 denghp supergroup 178 2013-04-28 16:46 /user/denghp/input/test.txt -rw-r--r-- 1 denghp supergroup 370 2013-04-28 16:46 /user/denghp/input/url 3、文件内容 denghp@denghp:~/software/hadoop-0.21.0$ hadoop fs -cat input/url 13/04/28 16:49:03 INFO security.Groups: Group mapping impl=org.apache.hadoop.security.ShellBasedUnixGroupsMapping; cacheTimeout=300000 13/04/28 16:49:03 WARN conf.Configuration: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id http://www.hao123.com/ 公司介绍 创业团队 荣誉之路 企业招聘 联系我们 友情链接 新闻资讯 产品与服务 分布式虚拟存储系统 http://www.baidu.com/ baidu http://www.google.com/ google中国 denghp@denghp:~/software/hadoop-0.21.0$ hadoop fs -cat input/input-1.txt 13/04/28 16:49:10 INFO security.Groups: Group mapping impl=org.apache.hadoop.security.ShellBasedUnixGroupsMapping; cacheTimeout=300000 13/04/28 16:49:11 WARN conf.Configuration: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id Hello Hadoop Goodbye Hadoop 4、运行WordCount程序 $ hadoop jar lib/wordcount-example-1.0-20130428.jar com.company.mr.WordCount input out
5、运行结果 denghp@denghp:~/workspace/mapreduce/trunk$ hadoop fs -cat out/part-00000 13/04/28 15:25:41 INFO security.Groups: Group mapping impl=org.apache.hadoop.security.ShellBasedUnixGroupsMapping; cacheTimeout=300000 13/04/28 15:25:41 WARN conf.Configuration: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id Goodbye 1 Hadoop 2 Hello 1 baidu 1 google中国 1 http://www.baidu.com/ 3 http://www.dangdang.com/ 2 http://www.google.com/ 1 http://www.hao123.com 1 产品与服务 1 企业招聘 1 公司介绍 1 分布式虚拟存储系统 1 创业团队 1 友情链接 1 新闻资讯 1 联系我们 1 荣誉之路 1(责任编辑:IT) |