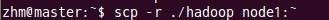|
四、下载并解压Hadoop安装包 关于安装包的下载就不多说了,不过可以提一下目前我使用的版本为hadoop-0.20.2, 这个版本不是最新的,不过学习嘛,先入门,后面等熟练了再用其它版本也不急。而且《hadoop权威指南》这本书也是针对这个版本介绍的。 注:解压后hadoop软件目录在/home/zhm/hadoop下
五、配置namenode,修改site文件 在配置site文件之前需要作一些准备工作,下载java最新版的JDK软件,可以从Oracle官网上下载,我使用的jdk软件版本为:jdk1.7.0_09,我将java的JDK解压安装在/opt/jdk1.7.0_09目录中,接着配置JAVA_HOME宏变量及hadoop路径,这是为了方便后面操作,这部分配置过程主要通过修改/etc/profile文件来完成,在profile文件中添加如下几行代码:
然后执行: 让配置文件立刻生效。上面配置过程每个结点都要进行一遍。
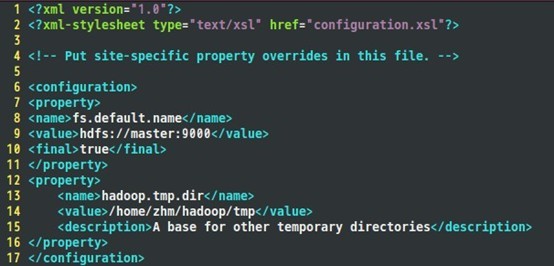
到目前为止,准备工作已经完成,下面开始修改hadoop的配置文件了,即各种site文件,文件存放在/hadoop/conf下,主要配置core-site.xml、hdfs-site.xml、mapred-site.xml这三个文件。 Core-site.xml配置如下:
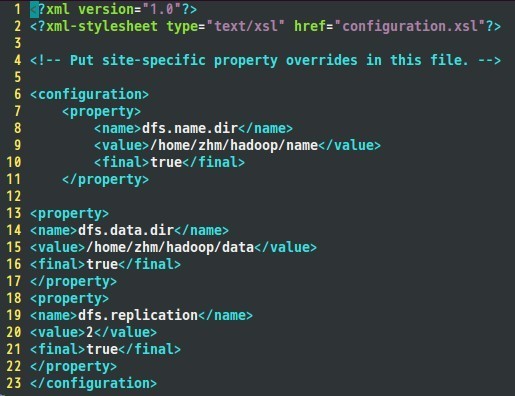
Hdfs-site.xml配置如下:
接着是mapred-site.xml文件:
六、配置hadoop-env.sh文件
这个需要根据实际情况来配置。
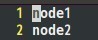
七、配置masters和slaves文件 根据实际情况配置masters的主机名,在本实验中,masters主结点的主机名为master, 于是在masters文件中填入:
同理,在slaves文件中填入:
八、向各节点复制hadoop 向node1节点复制hadoop:
向node2节点复制hadoop:
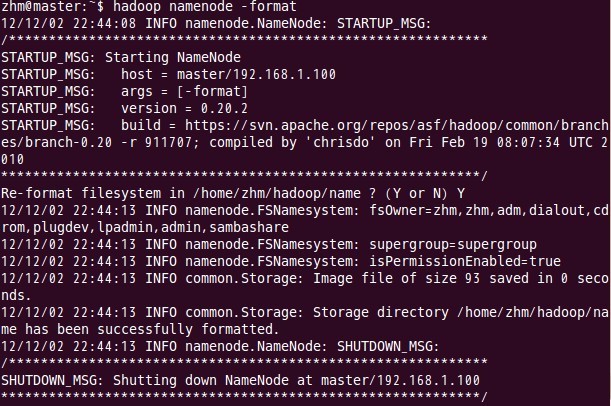
这样,结点node1和结点node2也安装了配置好的hadoop软件了。 九、格式化namenode 这一步在主结点master上进行操作:
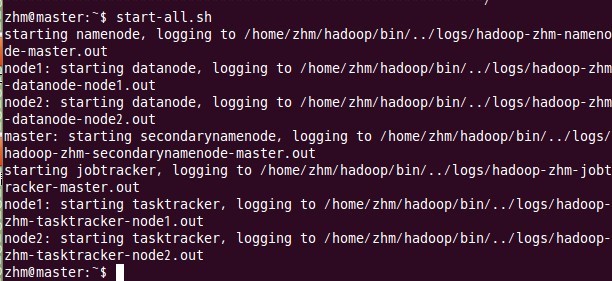
注意:上面只要出现“successfully formatted”就表示成功了。 十、启动Hadoop 这一步也在主结点master上进行操作:
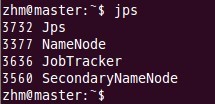
十一、 用jps检验各后台进程是否成功启动 在主结点master上查看namenode,jobtracker,secondarynamenode进程是否启动。
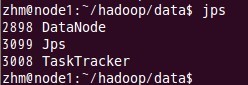
如果出现以上进程则表示正确。 在node1和node2结点了查看tasktracker和datanode进程是否启动。 先来node1的情况:
下面是node2的情况:
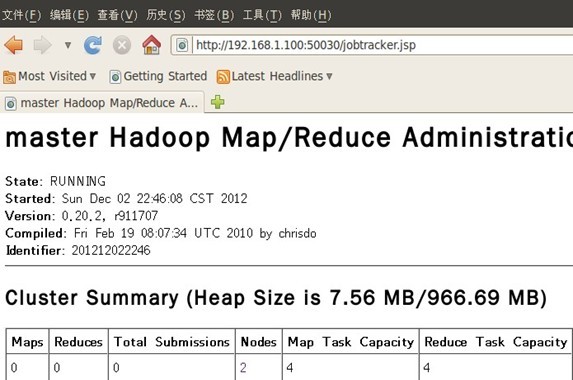
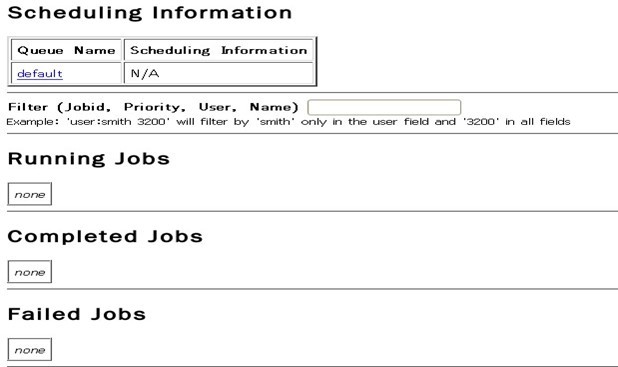
进程都启动成功了。恭喜~~~ 十二、 通过网站查看集群情况 在浏览器中输入:http://192.168.1.100:50030,网址为master结点所对应的IP:
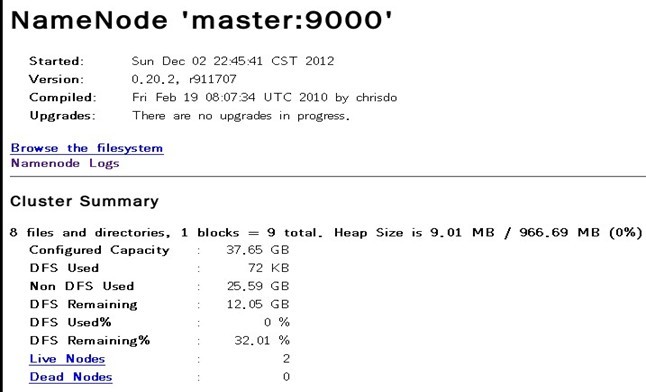
在浏览器中输入:http://192.168.1.100:50070,网址为master结点所对应的IP:
至此,hadoop的完全分布式集群安装已经全部完成,可以好好睡个觉了。~~ (责任编辑:IT) |