|
1.剖析MapReduce作业运行机制 1).经典MapReduce--MapReduce1.0 整个过程有有4个独立的实体
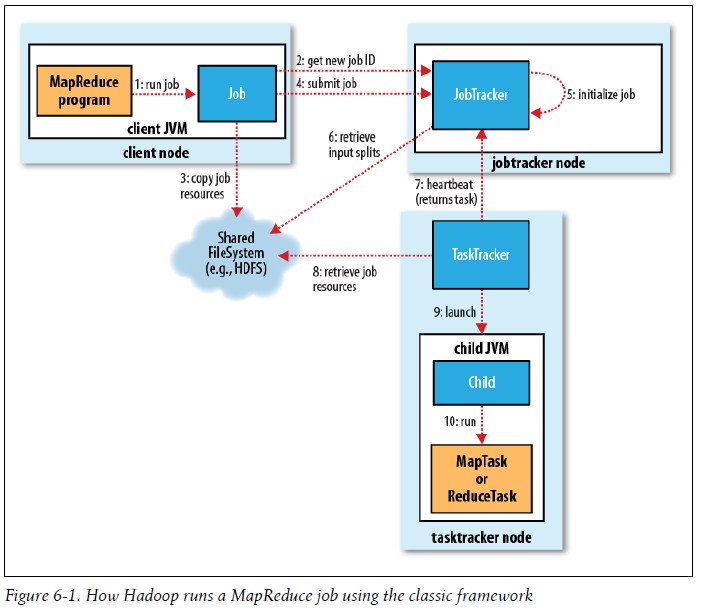
以下为运行整体图
A.作业的提交 JobClient的runJob是用于新建JobClient实例并调用其submitJob()方法的便捷方式,提交Job后,runJob()每秒轮询检测作业的进度,随时监控Job的运行状态。 其中JobClient的submitJob()方法所实现的作业提交过程:
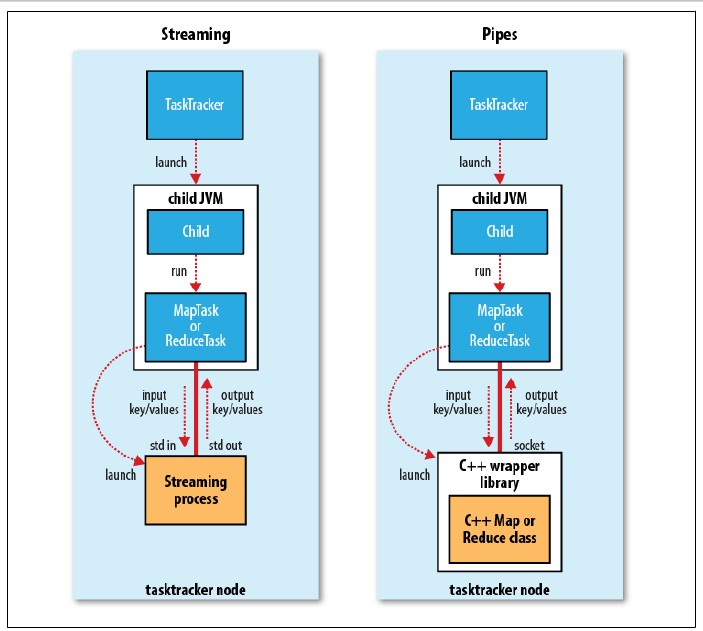
B.作业的初始化 JobTracker接收对其提交的作业后,会把这个调用放入一个队列,交由作业调度器调度,初始化。初始化包括创建一个表示正在运行作业的对象---封装任务和记录信息,以便跟踪任务的状态和进程 C.任务的分配 TaskTracker运行简单的循环来对JobTracker发送心跳,告知自己的是否存活,同时交互信息,对于map任务和reduce任务,TaskTracker会分配适当的固定数量的任务槽,理想状态一般遵循数据本地化,和机架本地化 D.任务的执行 第一步:TaskTracker拷贝JAR文件到本地,第二部:TaskTracker新建本地目录,将JAR文件加压到其下面;第三步:TaskTracker新建一个TaskRunner实例运行该任务。 Streaming和Pipes可运行特殊的Map和Reduce任务,Streaming支持多语言的编写,Pipes还可以与C++进程通信,如下图:
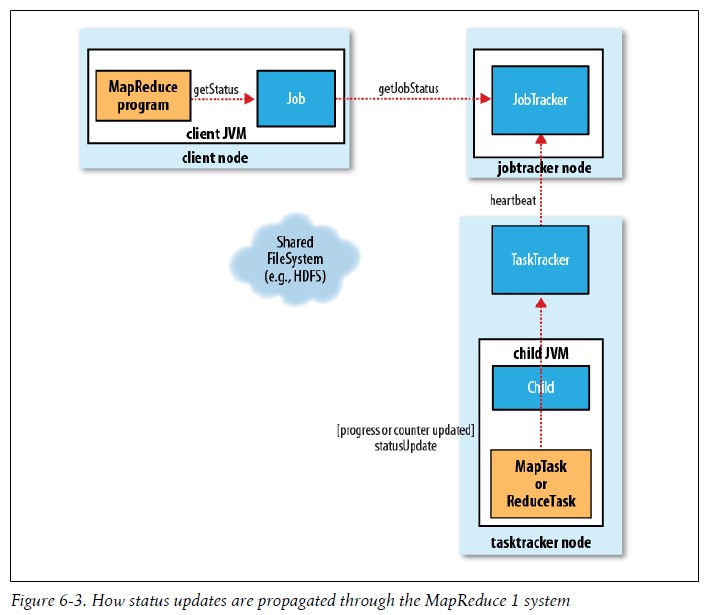
E.进程和状态的更新 通过Job的Status属性对Job进行检测,例如作业云习惯状态,map和reduce运行的进度、Job计数器的值、状态消息描述等等,尤其对计数器Counter(计数器)属性的检查。状态更新在MapReduce系统中的传递流程如下
F.作业的完成 当JobTracker收到Job最后一个Task完成的消息时候便把Job的状态设置为”完成“,JobClient得知后,从runJob()方法返回
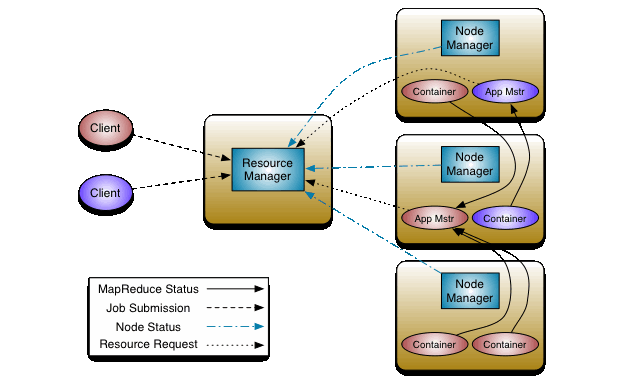
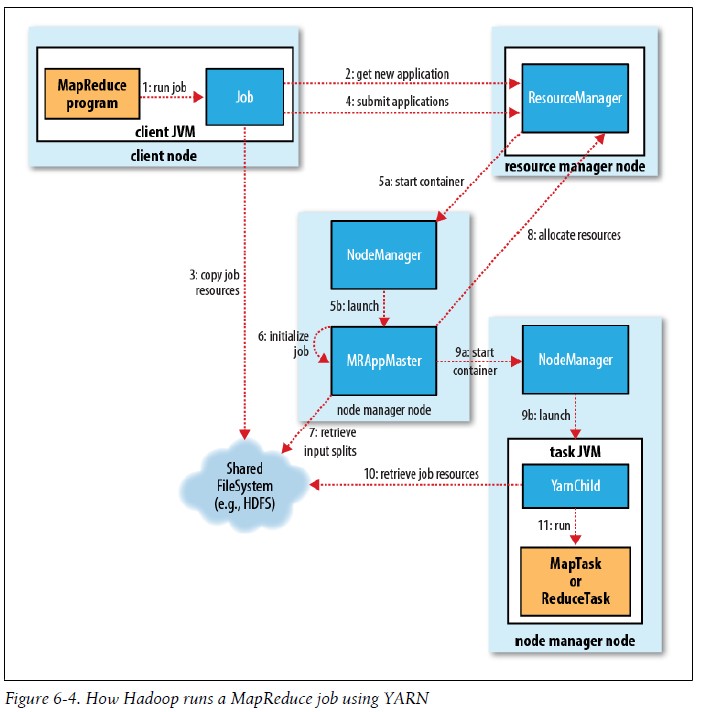
2).Yarn(MapReduce 2.0) Yarn出现在Hadoop 0.23和2.0版本中,相对前面 MapReduce的性能有不少的提高 相比较MapReduce1.0,JobTracker在MRv2 中被拆分成了两个主要的功能使用守护进程执行:资源管理和任务的调度与监视。这个想法创建一个全局的资源管理(global ResourceManager (RM))和为每个应用创建一个应用管理(ApplicationMaster (AM))。一个应用可以使一个MR jobs的经典场景或者是一串连续的Job ResourceManager 和每个slave节点的NodeManager (NM)构成一个资源估算框架。ResourceManager 对在系统中所有应用的资源分配拥有最终的最高级别仲裁权。其中ResourceManager 拥有两个主要的组件:调度器(Scheduler) 和资源管理器(ApplicationsManager) 实际上每个应用的ApplicationMaster(AM)是资源估算框架具体用到的lib包,被用来和ResourceManager 进行资源谈判,并且为NodeManager执行和监控task 整体如下图:
综上,在Hadoop Yarn中有5个独立的实体
整体如下:
A.作业的提交 Job提交相似于MapReduce1.0.当在配置文件中设置mapreduce.framework.name为yarn时候,MapReduce2.0继承接口ClientProtocol的模式就激活了,RM生成新的Job ID(从Yarn的角度看是Application ID---步骤2),接着Job客户端计算输入分片,拷贝资源(包括Job JAR文件、配置文件,分片信息)到HDFS(步骤3),最后用submitApplication函数提交Job给RM(步骤4)
B.作业的初始化 RM接受到由上面的A提交过来的调用,将其请求给调度器处理,调度器分配Container,同时RM在NM上启动Application Master进程(步骤5a和5b),AM主函数MRAppMatser会初始化一定数量的记录对象(bookkeeping)来跟踪Job的运行进度,并收取task的进度和完成情况(步骤6),接着MRAppMaster收集计算后的输入分片 之后与MapReduce1.0又有所不同,此时Application Master会决定如何组织运行MapReduce Job,如果Job很小,能在同一个JVM,同一个Node运行的话,则用uber模式运行(参见源码)
C.任务的分配 如果不在uber模式下运行,则Application Master会为所有的map和reducer task向RM请求Container,所有的请求都通过heartbeat(心跳)传递,心跳也传递其他信息,例如关于map数据本地化的信息,分片所在的主机和机架地址信息,这信息帮主调度器来做出调度的决策,调度器尽可能遵循数据本地化或者机架本地化的原则分配Container 在Yarn中,不像MapReduce1.0中那样限制map或者reduce的slot个数,这样就限制了资源是利用率,Yarn中非配资源更具有灵活性,可以在配置文件中设置最大分配资源和最小分配资源,例如,用yarn.scheduler.capacity.minimum-allocation-mb设置最小申请资源1G,用yarn.scheduler.capacity.maximum-allocation-mb设置最大可申请资源10G 这样一个Task申请的资源内存可以灵活的在1G~10G范围内
D.任务的执行 分配给Task任务Container后,NM上的Application Master就联系NM启动(starts)Container,Task最后被一个叫YarnChild的main类执行,不过在此之前各个资源文件已经从分布式缓存拷贝下来,这样才能开始运行map Task或者reduce Task。PS:YarnChild是一个(dedicated)的JVM Streaming 和 Pipes 运行机制与MapReduce1.0一样
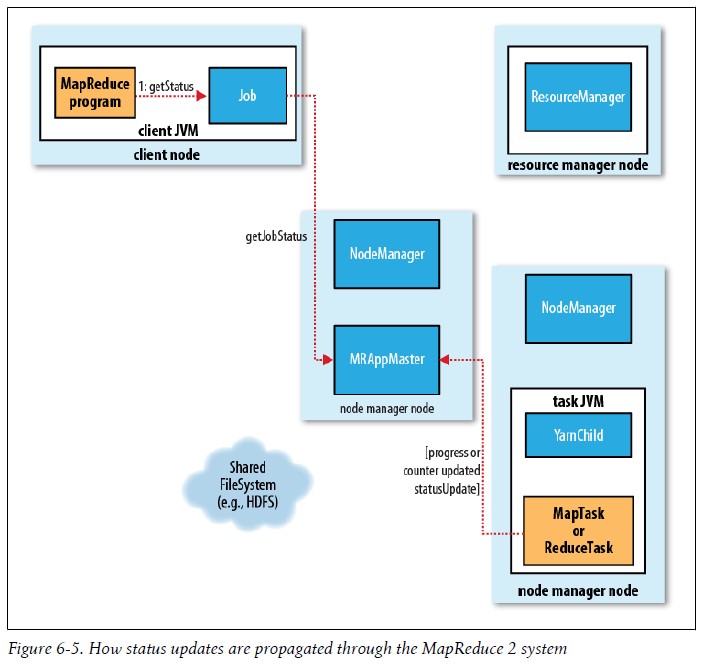
E.进程和状态的更新 当Yarn运行同时,Task和Container会报告它的进度和状态给Application Master,客户端会每秒轮询检测Application Master,这样就随时收到更新信息,这些信息也哭通过Web UI来查看
F.作业的完成 客户端每5秒轮询检查Job是否完成,期间需要调用函数Job类下waitForCompletion()方法,Job结束后该方法返回。轮询时间间隔可以用配置文件的属性mapreduce.client.completion.pollinterval来设置
2.失败情况 1)经典MapReduce---MapReduce1.0 A.TasK失败 第一种情况:map或reduce任务中的用户代码抛出运行异常,此时子进程JVM进程会在退出之前想TaskTracker发送错误报告,错误报告被记录错误日志,TaskTracker会将这个任务(Task)正在运行的Task Attempt标记为失败,释放一个任务槽去运行另外一个Task Attempt 第二种情况:子进程JVM突然退出Task Tracker会注意到JVM退出,并将此Task Attempt标记为失败 JobTracker通过心跳得知一个Task Attempt失败后,会重启调度该Task的执行,默认情况下如果失败4次不会重试(通过mapred.map.max.attempts可改变这个次数),整个Job也会标记为失败
B.TaskTracker失败 如果TaskTracker由于崩溃或者运行过慢失败,则停止向JobTracker发送心跳,JobTracker会注意到这点并将这个TaskTracker从等待任务调度TaskTracker池中移除 即使TaskTracker没有失败,也有可能因为失败任务次数远远高于集群的平均失败次数,这种情况会被列入黑名单,在重启后才将此TaskTracker移出黑名单
C.JobTracker失败 JobTracker失败是是最严重的是爱,此时只得重新开始提交运行
2).Yarn失败 A.Task(任务)的失败 情况与MapReduce1.0相似,其中Task Attempt失败这个消息会通知Application Master,由Application Master标记其为失败。当Task失败的比例大于mapreduce.map.failures.maxpercent(map)或者mapreduce.reduce.failures.maxpercent(reduece)时候,Job失败
B.Application Master的失败 与前面相似,当Application Master失败,会被标记为失败,这是RM会立刻探寻到AM(Application Master)的失败,并新实例化一个AM和借助NM建造新的相应的Container,在设置yarn.app.mapreduce.am.job.recovery.enable为true情况下失败的AM能够恢复,并且恢复后并不返回。默认情况下,失败AM会让所有的Task返回 如果客户端轮询得知AM失败后,经过一段时间AM失败状态仍然没有改变,则重新想RM申请相应的资源
C.Node Manager的失败 NM失败时,会停止向RM发送心跳,则RM会将这个NM从可用的NM池中移出,心态间隔时间可由yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms设置,默认是10分钟 如果NM上Application失败次数过高,此NM会被列入黑名单,AM会在不同Node上运行Task
D.Resources Manager的失败 RM的失败是最严重,离开了RM整个系统将陷入瘫痪,所以它失败后,会利用checkpoint机制来重新构建一个RM,详细配置见权威指南和Hadoop官网
3.作业的调度 1).FIFO Scheduler 这个调度是Hadoop默认d ,使用FIFO调度算法来运行Job,并且可以设置优先级,但是这个FIFO调度并不支持抢占,所以后来的高优先级的Job仍然会被先来低优先级的Job所阻塞 2)Fair Scheduler Fair Scheduler的目标是让每个用户公平的享有集群当中的资源,多个Job提交过来后,空闲的任务槽资源可以以"让每个用户公平共享集群"的原则被分配,某个用户一个很短的Job将在合理时间内完成,即便另一个用户有一个很长的Job正在运行 一般Job都放在Job池当中,默认时,每个用户都有自己的Job池,当一个用户提交的Job数超过另一个用户时,不会因此得到更多的集群资源 另外Fair Scheduler支持抢占,如果一个池的资源未在一段时间内公平得到集群资源,那么Fair Scheduler会从终止得到多余集群资源的Task,分给前者。 3).Capacity Scheduler Capacity Scheduler中,集群资源会有很多队列,每个队列有一定的分配能力,在每个队列内会按照FIFO Scheduler去分配集群资源。
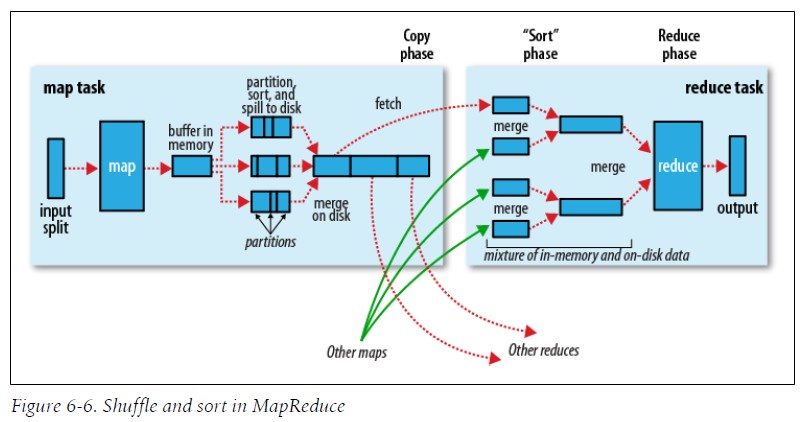
4.shuffle和排序 在Hadoop Job运行时,MapReduce会确保每个reducer的输入都按键排序,并且执行这个排序过程---将map的输出所谓reducer的输入---称为shuffle,从许多方面看来,shuffle正是map的心脏。 以下掩盖了一些细节,并且新版Hadoop,在这一块有修改 1).map端 MapTask都一个环形的内存缓冲区,之后当缓冲区被占用内到达一定比例(比如80%),会启用spill线程将缓冲区中的数据写入磁盘,写入磁盘前,spill线程会据根据最终要送达的reduce将数据划分为相应的partition,每个partition中,线程会按照键进行内排序(Haoop2.0显示的用的是快排序),当spill线程执行处理最后一批MapTask的输出结构后,启用merger合并spill文件,如果设置Combiner,那接下来执行Combine函数,合并本地相同键的文件
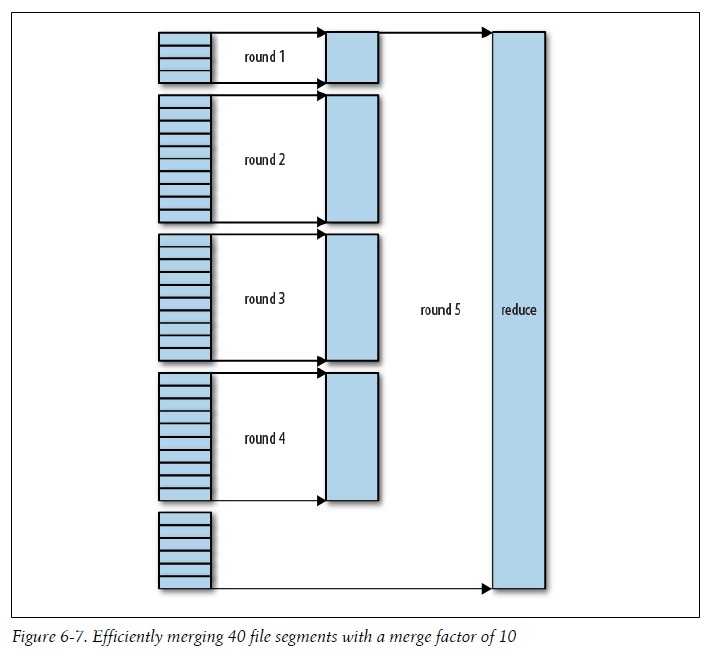
2).reduce端 接下来运行ReduceTask,其中的Fetch的线程会从Map端以HTTP方式获取相应的文件分区,完成复制map的输出后,reducer就开始排序最后运行merger把复制过来的文件存储在本地磁盘。(PS:在Yarn中 Map和Reduce之间的数据传输用到了Netty以及Java NIO 详见源代码) 这里需要注意的是:每趟合并目标是合并最小数量的文件以便满足最后一趟的合并系数,eg:有40个文件,我们不会再4趟中,每趟合并10个文件然后得到4个文件,相反第一堂只合并4个文件,最后的三趟每次合并10个文件,在最后的一趟中4个已经合并的文件和余下的6个文件(未合并)进行10个文件的合并(见下图),其实这里并没有改变合并次数,它只是一个优化措施,尽量减少写到磁盘的数据量,因为最后一趟总是合并到reduce(?这个地方合并来源来自内存和磁盘,减少了从内存的文件数,所以减少最后一次写到磁盘的数据量)
从Map到Reducer数据整体传输过程如下:
3)配置的调优 调优总的原则给shuffle过程尽量多提供内存空间,在map端,可以通过避免多次溢出写磁盘来获得最佳性能(相关配置io.sort.*,io.sort.mb),在reduce端,中间数据全部驻留在内存时,就能获得最佳性能,但是默认情况下,这是不可能发生的,因为一般情况所有内存都预留给reduce含函数(如需修改 需要配置mapred.inmem.merge.threshold,mapred.job.reduce.input.buffer.percent)
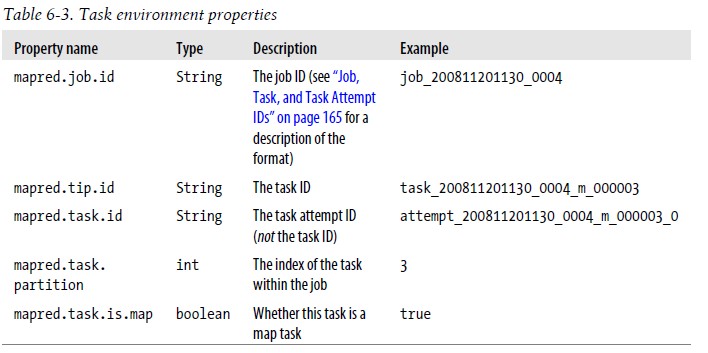
5.Task的执行 1).任务执行环境 Hadoop为MapTask和ReduceTask提供了运行环境相关信息,例如MapTask可以找到他所处理文件的名称,通过为mapper和reducer提供一个configure()方法实现,表可获得下图中的Job的配置信息。
Hadoop设置Job的配置参数可以作为Streaming程序的环境变量。
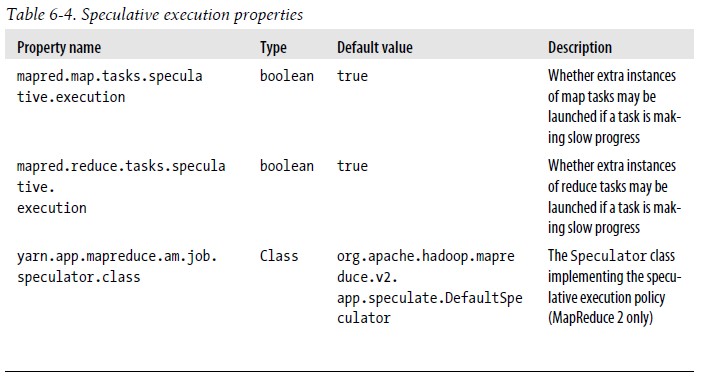
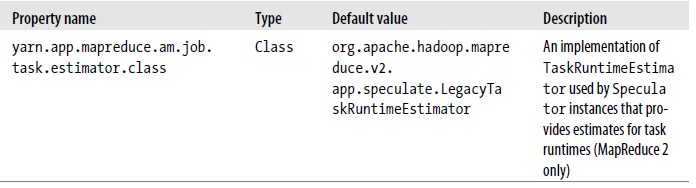
2).推测执行(Speculative Execution) Speculative Execution机制的为了解决Hadoop中出现缓慢某些Task拖延整个Job运行的问题,Speculative Execution会针对那些慢于平均进度的Task启动Speculative Task,此时如果原Task在Speculative Task前完成,则Speculative Task会被终止,同样的,如果Speculative Task先于原Task完成则原来的Task会被终止 默认情况下Speculative Execution是启用的,下面的属性可以控制是否开启该功能:
3).Output Committers Hadoop MapReduce利用commit协议确保在Job或者Task运行期间插入是适当的操作,无论他们成功完成或者失败,在新的API中OutputCommitter由接口OutputFormat决定, 下面是OutputCommitter的API: 
public abstract class OutputCommitter { public abstract void setupJob(JobContext jobContext) throws IOException; public void commitJob(JobContext jobContext) throws IOException {
} public void abortJob(JobContext jobContext, JobStatus.State state) throws IOException {
} public abstract void setupTask(TaskAttemptContext taskContext) throws IOException; public abstract boolean needsTaskCommit(TaskAttemptContext taskContext) throws IOException; public abstract void commitTask(TaskAttemptContext taskContext) throws IOException; public abstract void abortTask(TaskAttemptContext taskContext) throws IOException;
}
其中当将要运行Job时候运行setupJob()方法;当Job运行成功后调用commitJob()方法,并且输出目录后缀_SUCCESS;当Job没有成功运行,则调用abortJob(),并且删除相应的输出文件;相类似Task执行成功调用commitTask()方法,Task执行失败调用abortTask()方法,并且删掉相应生成的文件
4).Task JVM重用 启动JVM重用后,可以让不同Task重用一个JVM,节省了重建销毁JVM的时间,在Hadoop2.0中默认情况不提供这种功能
5).跳过坏记录 在大数据中经常有一些损坏的记录,当Job开始处理这个损坏的记录时候,导致Job失败,如果这些记录并不明显影响运行结果,我们就可以跳过损坏记录让Job成功运行 一般情况,当任务失败失败两次后会启用skipping mode,对于一直在某记录失败的Task,NM或者TaskTracker将会运行一下TaskAttempt A.任务失败 B.任务失败 C.开启skipping mode。任务失败,失败记录由TaskTracker或者NM保存 D.仍然启用skipping mode,任务继续运行,但是跳过上一次尝试失败的坏记录
在默认情况下,skipping mode是关闭的 可以用SkipBadRecords类来启用该功能 (责任编辑:IT) |