|
�����ܽ���apache pig �IJ���ʹ�á� Ŀ¼[-]
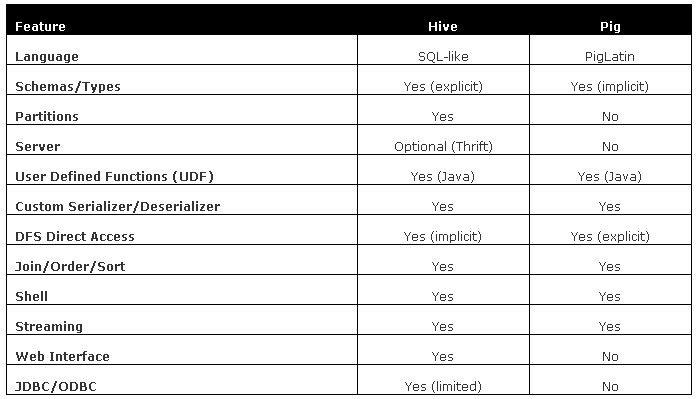
1 ��Ʒ����1.1 ��Ʒ����Google�Ĺ���ʦΪ�˷����Լ���MapReduce��ʵ�ֿ�����һ������Sawzall�Ĺ��ߣ�Ȼ���˼�ƪ���ķ������ϣ�Apache�������Ŀ�����������Sawzall��Pig���ԣ�����˵Pig����Sawzall��ɽկ�档 Pig ��һ�����������ԣ��ʺ���ʹ�� Hadoop �� MapReduce ƽ̨����ѯ���Ͱ�ṹ�����ݼ���ͨ�������Էֲ�ʽ���ݼ���������SQL�IJ�ѯ��Pig���Լ�Hadoop��ʹ�á����ṩ��SQL-LIKE���Խ�Pig Latin�������Եı����������SQL�����ݷ�������ת��Ϊһϵ�о����Ż�������MapReduce���㡣PigΪ���ӵĺ������ݲ��м����ṩ��һ���IJ����ͱ�̽ӿڡ� ��MapReduce�������map��reduce����������������ֿ���һ��MapReduceӦ�ã���Ҫ�ӱ�д���룬���룬���𣬷���Hadoop��ִ�����MapReduce������Ҫ�ķ�һ��ʱ�䣬����Pig�������Լ����MapReduce�Ŀ��������һ����ԶԲ�ͬ������֮�����ת���� Pig���Դ��������У�����Pig�����ѹ��ִ��“bin/pig -x local”����ֱ�����У��dz��������localģʽ��������������������������ʹ�ã����ǽ�Pig��hdfs/hadoop��Ⱥ�������жԽӡ�����˵Pig���Ƕ�mapreduce�㷨(���)ʵ�ֵ�һ��shell�ű�������SQL��䣬��Pig�г�֮ΪPig Latin�������ű��п��ԶԼ��ؽ��������ݽ��������ˡ���͡�����(group by)������(Joining)��PigҲ�������û��Զ���һЩ���������ݼ����в�������UDF(user-defined functions)�� ����Pig Latin��ת��������һ��MapReduce����ҵ��ͨ��MapReduce����̡߳����̻��߶���ϵͳ����ִ�д����Ľ�������з�����ɡ�Map() �� Reduce()���������Ტ�����У���ʹ������ͬһ��ϵͳ��ͬһʱ��Ҳ��ͬʱ����һ���������еĴ��������֮�����������ʽ�������ұ��浽һ���ļ���Pig����MapReduce������ֳ������Σ���һ���ηֽ��ΪС�鲢�ҷֲ���ÿһ���洢���ݵĽڵ��Ͻ���ִ�У��Լ����ѹ�����з�ɢ���ڶ����ξۺϵ�һ����ִ�е���Щ������������Դﵽ�dz��ߵ���������ͨ������Ĵ�����������ܹ�������ǧ̨�������м��㣬������ü��������Դ���˷��������е�ƿ���� 1.2 Ӧ�ó��� Apache Pig��һ������Hadoop�Ĵ��ģ���ݷ���ƽ̨����Pig��TB��������ݽ��в�ѯ�dz����ɣ�������Щ���������ݶ��Ƿǽṹ�������ݣ����磺һ���ļ�������log4j�����־���Ҵ���ڿ�Խ���������Ķ�������ϣ�������¼��ǧ̨���߷������Ľ���״̬��־������������IP���ʼ�¼��Ӧ�÷�����־�ȵȡ�ͨ����Ҫͳ�ƻ��߳�ȡ��Щ��¼�����߲�ѯ�쳣��¼������Щ��¼�γ�һЩ������������ת��Ϊ�м�ֵ����Ϣ�������Ļ���ѯ���Ϊ���ӣ���ʱ����MySQL�����IJ�Ʒ�Ͳ�һ����������ٶȡ�ִ��Ч���ϵ�������Apache��Pig����ʵ��������Ŀ�ꡣ 1.3 ��hive�Ƚ� ��Ȼpig��hive����һ�ִ��ģ���ݷ������ߣ���Hive�ƺ��е����ݿ��Ӱ�ӣ���Pig����һ����MapReduceʵ�ֵĹ���(�ű�)�����߶�ӵ���Լ��ı������ԣ���Ŀ���ǽ�MapReduce��ʵ�ֽ��м����Ҷ�д�����������ն��Ǵ洢��HDFS�ֲ�ʽ�ļ�ϵͳ�ϡ�������Pig��Hive��Щ���Ƶĵط�����Ҳ��Щ��ͬ�����ǵıȽ�����ͼ��ʾ��
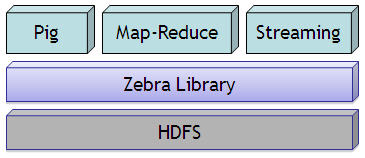
1. Language ��Hive�п���ִ�в���/ɾ���Ȳ���������Pigû�з����п��Բ������ݵķ����� 2. Schemas Hive�����ٻ���һ��“��”�ĸ������Pig�л���û�б��ĸ����ν�ı�������Pig Latin�ű��У���������metadata�ˣ� 2. Partitions Pig��û�б��ĸ������˵����������Pig��˵������̸��hive���з����ĸ�� 3. Server Hive����������Thrift����һ�����������ṩԶ�̵��ã�Pigû�У� 4. Shell ��Pig����ִ��ls ��cat�����ܾ����linux shell���������Hive��û�У� 5. Web Interface Hive�У�Pig�ޣ� 6. JDBC/ODBC Pig�ޣ�Hive�С� 2 ��Ʒ�ܹ� Pig��5����Ҫ�IJ��ֹ��ɣ�����ͼ��ʾ��
1.Pig�Լ�ʵ�ֵ�һ��ܶ����롢������˻��������ֵ�ʵ�֣�����Pig Latin�� 2.Zebra��Pig��HDFS/Hadoop���м�㡢Zebra��MapReduce��ҵ��д�Ŀͻ��ˣ�Zerbra�ýṹ��������ʵ���˶�hadoop�����洢Ԫ���ݵĹ�����Ҳ�Ƕ�Hadoop�����ݳ���㣬��Zebra����2�����ĵ��� TableStore(д)/TableLoad(��)��Hadoop�ϵ����ݽ��ж�д������ 3.Pig�е�Streaming��Ҫ��Ϊ4�������Pig Latin������(Logical Layer)��������(Physical Layer)��Streaming����ʵ��(Implementation)��Streaming�ᴴ��һ��Map/Reduce��ҵ���������������ʵļ�Ⱥ��ͬʱ���������ҵ���ڼ�Ⱥ�����е�����ִ�й��̣� 4.MapReduce��ÿ̨�����Ͻ��зֲ�ʽ����Ŀ��(�㷨)�� 5.HDFS���մ洢���ݵIJ��֡� 3 ��װ����Hive���°汾��apache-hive-0.13.1-bin.tar.gz�����ص�ַΪhttp://apache.fayea.com/apache-mirror/hive/hive-0.13.1/�� ���غ�ѡ��Ŀ¼����ѹ���������£� # tar -zxvf hive-0.10.0.tar.gz 4 Pig����������ϵ��relation��������bag����Ԫ�飨tuple�����ֶΣ�field�������ݣ�data���Ĺ�ϵ һ����ϵ��relation����һ������bag�����������˵����һ���ⲿ�İ���outer bag���� һ������bag����һ��Ԫ�飨tuple���ļ��ϡ���pig�б�ʾ����ʱ���ô�����{}�������Ķ�����ʾһ����——�������ڽ̳��е�ʵ����ʾ��������pig����ģʽ�µ����������ѭ������Լ���� һ��Ԫ�飨tuple���������ֶΣ�field����һ������ordered set������pig�б�ʾ����ʱ����С����()�������Ķ�����ʾһ��Ԫ�顣 һ���ֶ���һ�����ݣ�data���� “Ԫ��”����ʺܳ�����������ɹ�ϵ�����ݿ���е�һ�У�������һ�������ֶΣ����У�ÿһ���ֶο������κ��������ͣ����ҿ����л���û�����ݡ� “��ϵ”���Ա����ɹ�ϵ�����ݿ��һ�ű���������˵�ˣ�“Ԫ��”���Ա��������ݱ��е�һ�У��ڹ�ϵ�����ݿ��У�ͬһ�ű��е�ÿһ�ж��й̶����ֶ�������pig�е�“��ϵ”��“Ԫ��”֮�䣬“��ϵ”����Ҫ��ÿһ��“Ԫ��”��������ͬ�������ֶΣ�����Ҳ����Ҫ���“Ԫ��”������ͬλ�ô����ֶξ�����ͬ���������͡� 5 Pig����������5.1 AVG��ƽ��һ�������ά�������ƽ��ֵ��ʵ������ �����������ļ���a.txt������ֵ֮������tab�ָ��ģ��� [root@localhost pig]$ cat a.txt a 1 2 3 4.2 9.8 a 3 0 5 3.5 2.1 b 7 9 9 - - a 7 9 9 2.6 6.2 a 1 2 5 7.7 5.9 a 1 2 3 1.4 0.2 �������£���������ڵ�2��3��4�е�������ϵ�����£�������е�ƽ��ֵ�ֱ��Ƕ��٣� ���磬��2��3��4����һ�����Ϊ��1��2��3��������һ�к����һ�����ݡ������ά�������˵��������е�ƽ��ֵ�ֱ�Ϊ�� ��4.2+1.4��/2��2.8 ��9.8+0.2��/2��5.0 �����ڵ�2��3��4�е���������ά����ϣ����ֱ�ֻ��һ�����ݣ����������е�ƽ��ֵ��ʵ�������������� �ر�أ���ϣ�7��9��9�������м�¼�����������У����ǵ��������ݵ��������û��ֵ���������Ӧ�ñ�����ƽ��ֵ�ļ��㣬Ҳ����˵���ڼ���ƽ��ֵʱ������������Ч���ݡ����ԣ�7��9��9����ϵ�������е�ƽ��ֵΪ2.6��6.2�� ������pig����һ�£�����������յĽ���� �Ƚ��뱾�ص���ģʽ��pig -x local������������������pig���룺 A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double); B = GROUP A BY (col2, col3, col4); C = FOREACH B GENERATE group, AVG(A.col5), AVG(A.col6); DUMP C; pig���������£� ((1,2,3),2.8,5.0) ((1,2,5),7.7,5.9) ((3,0,5),3.5,2.1) ((7,9,9),2.6,6.2) ���棬����������ÿһ��pig����ֱ�õ���ʲô�������ݡ� �ټ���a.txt�ļ�����ָ��ÿһ�е��������ͷֱ�Ϊchararray���ַ�������int��int��int��double��double��ͬʱ������ÿһ�б������ֱ�Ϊcol1��col2��……��col6����������ں�������ݴ����л��õ�——����㲻ָ����������ô�ں���Ĵ����У���ֻ��ʹ��������$0��$1��……������ʶ��Ӧ�����ˣ������ɶ��Ի����ˣ����й̶�������£�����ָ�������ĺá� �����ݼ���֮���浽����A�У�A�����ݽṹ���£� A: {col1: chararray,col2: int,col3: int,col4: int,col5: double,col6: double} �ɼ���A���ô������������Ķ��������ݱ���ǰ���˵����A��һ������bag����A�������е�������һ�µģ�Ҳ������ǰ���ӡ������a.txt�ļ���������һ���ģ�����һ��һ�е�������“��ά��”�����ݡ� �ڰ���A�ĵ�2��3��4�У���A���з��顣pig���ҳ����е�2��3��4�е���ϣ�����������������У�Ȼ���������Ӧ�İ�A�����������õ����µ����ݽṹ�� B: {group: (col2: int,col3: int,col4: int),A: {col1: chararray,col2: int,col3: int,col4: int,col5: double,col6: double}} �ɼ���A�ĵ�2��3��4�е���ϱ�pig������һ��������group��ͬʱB��ÿһ����ʵ������һ��group�����ɸ�A��ɵ�——ע�⣬�����ɸ�A������֮����ֻ��ʾ��һ��A������Ϊ�����ʾ�������ݽṹ��������ʾ���������ж����顣 ʵ�ʵ�����Ϊ�� ((1,2,3),{(a,1,2,3,4.2,9.8),(a,1,2,3,1.4,0.2)}) ((1,2,5),{(a,1,2,5,7.7,5.9)}) ((3,0,5),{(a,3,0,5,3.5,2.1)}) ((7,9,9),{(b,7,9,9,,),(a,7,9,9,2.6,6.2)}) �ɼ�����ǰ����˵��һ������ϣ�1��2��3����Ӧ���������ݣ���ϣ�7��9��9��Ҳ��Ӧ���������ݡ� �ۼ���ÿһ������µ�������е�ƽ��ֵ�� �۸�������õ���B�����ݣ�����B�����һ��һ�е����ݣ�ֻ������Щ�в��ǶԳƵģ���FOREACH�������Ƕ�B��ÿһ�����ݽ��б�����Ȼ����м��㡣 GENERATE��������ΪҪ����ʲô�������ݣ������group������һ��������B�ĵ�һ�����ݣ���pigΪA�ĵ�2��3��4�е���ϸ���ı������������������������ݼ�C��ÿһ�����һ�����B�е�group——�����ڣ�1��2��5��������Ԫ�飩�� ��AVG(A.col5)�����ļ��㣬���ǵ�����pig��һ����ƽ��ֵ�ĺ���AVG�����ڶ�A����Ϊcol5������ƽ��ֵ���ڼ������ݵ�A��ʱ�������Ѿ���ÿһ�����˸�������col5���ǵ����ڶ��С� �����A.col5��ָ����B��ÿһ���е�A�������ǰ���ȫ�����ݵ��Ǹ�A����B�ĵ�һ���������� ((1,2,3),{(a,1,2,3,4.2,9.8),(a,1,2,3,1.4,0.2)}) ������B����һ��ʱ��Ҫ����AVG(A.col5)��pig���ҵ�(a,1,2,3,4.2,9.8)�е�4.2���Լ�(a,1,2,3,1.4,0.2)�е�1.4������������2���͵õ���ƽ��ֵ�� ͬ��������Ҳ֪����AVG(A.col6)����ô������ġ�������һ��Ҫע��ģ���(7,9,9)����飬����Ӧ������(b,7,9,9,,)�������������ֵ�ģ�������Ϊ���ǵ������ļ���Ӧλ���ϲ�����Ч���֣���������“-”��pig�ڼ������ݵ�ʱ���Զ�������Ϊ���ˣ����Ҽ���ƽ��ֵ��ʱ��Ҳ�������һ�����ݿ������ڣ��൱�ں����������ݵĴ��ڣ��� ����C�����ݽṹ�������ģ� C: {group: (col2: int,col3: int,col4: int),double,double} ��DUMP C���ǽ�C�е��������������̨�����Ҫ������ļ�����Ҫʹ�ã� STORE C INTO 'output'; ����pig�ͻ��ڵ�ǰĿ¼���½�һ��“output”Ŀ¼����Ŀ¼�������Ȳ����ڣ������ѽ���ļ��ŵ���Ŀ¼�¡� ���Ҫʵ����ͬ�Ĺ��ܣ���Java��C++дһ��Map-ReduceӦ�ó�����Ҫ�ܳ�ʱ�䣬����дһ��build.xml����Makefile�������ʱ�����д���pig����ļ�ʮ���ˣ� ����Ϊpig��������ƣ����ŵõ��˹㷺Ӧ�á� 5.2 Countͳ��������SQL����У�Ҫͳ�Ʊ������ݵ��������ܼ� SELECT COUNT(*) FROM table_name WHERE condition ��pig�У�Ҳ��һ��COUNT��������SQL��ͬ���������˵���� ����Ҫ���������ļ�a.txt�������� [root@localhost pig]$ cat a.txt a 1 2 3 4.2 9.8 a 3 0 5 3.5 2.1 b 7 9 9 - - a 7 9 9 2.6 6.2 a 1 2 5 7.7 5.9 a 1 2 3 1.4 0.2 ��ȷ�������ǣ� A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double); B = GROUP A ALL; C = FOREACH B GENERATE COUNT(A.col2); DUMP C; �������� (6) ������6�����ݡ� ����������У�ͳ��COUNT(A.col2)��COUNT(A)�Ľ����һ���ģ����ǣ����col2��һ���к��п�ֵ�� [root@localhost pig]$ cat a.txt a 1 2 3 4.2 9.8 a 0 5 3.5 2.1 b 7 9 9 - - a 7 9 9 2.6 6.2 a 1 2 5 7.7 5.9 a 1 2 3 1.4 0.2 ������pig����ִ�н��Ϊ�� grunt> A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double); grunt> B = GROUP A ALL; grunt> C = FOREACH B GENERATE COUNT(A.col2); grunt> DUMP C; (5) �ɼ������Ϊ5�С�������Ϊ��LOAD���ݵ�ʱ��ָ����col2����������Ϊint����a.txt�ĵڶ��������ǿյģ�������ݼ��ص�A�Ժ���һ���ֶξ��ǿյģ� grunt> DUMP A; (a,1,2,3,4.2,9.8) (a,,0,5,3.5,2.1) (b,7,9,9,,) (a,7,9,9,2.6,6.2) (a,1,2,5,7.7,5.9) (a,1,2,3,1.4,0.2) ��COUNT��ʱ��null���ֶβ��ᱻ�������ڣ����Խ����5�� 5.3 FLATTEN��ƽ�����������Ͽ���flatten����“Ūƽ”����˼������ͨ��һ������ʵ���˽�flatten��pig�е����á� ���Dz���ǰ���a.txt�����ļ���˵���� [root@localhost pig]$ cat a.txt a 1 2 3 4.2 9.8 a 3 0 5 3.5 2.1 b 7 9 9 - - a 7 9 9 2.6 6.2 a 1 2 5 7.7 5.9 a 1 2 3 1.4 0.2 �������ǰ�ĵ������������ά������µ�������е�ƽ��ֵ���� grunt> A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double); grunt> B = GROUP A BY (col2, col3, col4); grunt> C = FOREACH B GENERATE group, AVG(A.col5), AVG(A.col6); grunt> DUMP C; ((1,2,3),2.8,5.0) ((1,2,5),7.7,5.9) ((3,0,5),3.5,2.1) ((7,9,9),2.6,6.2) �ɼ����������У�ÿһ�еĵ�һ����һ��tuple��Ԫ�飩�������Կ�FLATTEN�����ã� grunt> A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double); grunt> B = GROUP A BY (col2, col3, col4); grunt> C = FOREACH B GENERATE FLATTEN(group), AVG(A.col5), AVG(A.col6); grunt> DUMP C; (1,2,3,2.8,5.0) (1,2,5,7.7,5.9) (3,0,5,3.5,2.1) (7,9,9,2.6,6.2) ��FLATTEN��group������һ��Ԫ�飬���ڱ���˱�ƽ�Ľṹ�ˡ�����pig�ĵ���˵����FLATTEN���ڶ�Ԫ�飨tuple���Ͱ���bag��“��Ƕ��”��un-nest���� ���е�ʱ��“��Ƕ��”�����ݽṹ�Dz����ڹ۲�ģ�������������ݿ��ܲ�������Χ������Ĵ��������磬pig��������������̺���Ҫ��������������������������һ��Ԫ�飬������������Ǻ����ŵģ�����ڴ�����������Ҫ��һ��ȥ���ŵĹ�����ˣ�FLATTEN�ṩ��һ����ijЩ����¿������������ط������ݵĻ��ᡣ 5.4 GROUP�����������GROUP��key�������һ���ֶΣ����籾��ǰ������ӣ�����GROUP֮������ݵ�key��һ��Ԫ�飨tuple��������������������GROUP��key��ͬ���͵Ķ����� GROUP�Ľ����һ����ϵ��relation�����������ϵ�У�ÿһ�����һ��Ԫ�飨tuple�������Ԫ����������ֶΣ���1����һ���ֶα�����Ϊ“group”——��һ��dz�������GROUP�ؼ�����������������ֿ��������ֶε�����������GROUP��key������ͬ����2���ڶ����ֶ���һ������bag�������������뱻GROUP�Ĺ�ϵ��������ͬ�� �ú���null���ֶ���GROUP�����Ҳ�Ὣnull���룬������ԡ� �����������ļ� a.txt ����Ϊ�� 1 2 5 1 3 1 3 6 9 8 ���У�ÿ��������֮������tab�ָ�ģ��ڶ��еĵ�2�С������еĵ�3��û�����ݣ�Ҳ����˵�����ص�Pig��֮��Ӧ�����ݻ���null�����������Щ���ݰ���1����2����GROUP�Ļ�����1��2���к���null���лᱻ������ ����һ�����飺 A = LOAD 'a.txt' AS (col1:int, col2:int, col3:int); B = GROUP A BY (col1, col2); DUMP B; ������Ϊ�� ((1,2),{(1,2,5)}) ((1,3),{(1,3,)}) ((1,),{(1,,3)}) ((6,9),{(6,9,8)}) ������Ľ���������У��ɼ���ԭ�����е�1��2���ﺬ��null����Ҳ�����������ˣ�Ҳ����˵��GROUP�����Dz������null�ģ�����COUNT������ͬ�� �����������������ļ��� [root@localhost ~]# cat 3.txt 1 9 2 2 3 3 4 0 1 9 1 9 4 0 ����Ҫ�ҳ���1��2�е�����У�ÿһ�ֵĸ����ֱ�Ϊ���٣����磬(1,9)�����3����(4,0)������������������ơ� �Զ�����ֻ��Ҫ��GROUP�Ϳ���������������������д�����´��룺 A = LOAD '3.txt' AS (col1: int, col2: int); B = GROUP A ALL; C = FOREACH B GENERATE group, COUNT(A); DUMP C; ��ϧ���������������Ҫ�ģ� (all,7) ���ǵı����ǰ���������GROUP������ʹ����GROUP ALL��������ʵ���ϱ����ͳ������������Ĵ������һ�α���ͳ�����������Ĵ��룺 A = LOAD '3.txt' AS (col1: int, col2: int); B = GROUP A ALL; C = FOREACH B GENERATE COUNT(A); DUMP C; ��ˣ������ C = FOREACH B GENERATE group, COUNT(A) Ҳ�Ǿ��Ƕ��ӡ��һ��group�����֣�all������——group�����ֱ�����Ϊ“all”������Pig�������ġ� ��ȷ�������ܼ�ֻ��Ҫ�������ֶ�GROUP���Ϳ����ˣ� A = LOAD '3.txt' AS (col1: int, col2: int); B = GROUP A BY (col1, col2); C = FOREACH B GENERATE group, COUNT(A); DUMP C; ������£� ((1,9),3) ((2,2),1) ((3,3),1) ((4,0),2) ����ǰ���������ȷ�����һ���ġ� 5.5 tuple�������Ǽ������������ݣ� [root@localhost pig]$ cat a.txt a 1 2 3 4.2 9.8 a 3 0 5 3.5 2.1 b 7 9 9 - - a 7 9 9 2.6 6.2 a 1 2 5 7.7 5.9 a 1 2 3 1.4 0.2 ����������·�ʽ���������ݣ� A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double); ��ô�õ���A�����ݽṹΪ�� grunt> DESCRIBE A; A: {col1: chararray,col2: int,col3: int,col4: int,col5: double,col6: double} �����Ҫ��A����һ��Ԫ�飨tuple�������أ� A = LOAD 'a.txt' AS (T : tuple (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double)); Ҳ������Ҫ�õ����������ݽṹ�� grunt> DESCRIBE A; A: {T: (col1: chararray,col2: int,col3: int,col4: int,col5: double,col6: double)} ��ô������ķ������õ�һ���յ�A�� grunt> DUMP A; () () () () () () ������Ϊ�����ļ�a.txt�Ľṹ���ʺ����������س�Ԫ�飨tuple���� ����������ļ�b.txt�� [root@localhost pig]$ cat b.txt (a,1,2,3,4.2,9.8) (a,3,0,5,3.5,2.1) (b,7,9,9,-,-) (a,7,9,9,2.6,6.2) (a,1,2,5,7.7,5.9) (a,1,2,3,1.4,0.2) ��ʹ��������˵�ļ��ط��������Ϊ�� grunt> A = LOAD 'b.txt' AS (T : tuple (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double)); grunt> DUMP A; ((a,1,2,3,4.2,9.8)) ((a,3,0,5,3.5,2.1)) ((b,7,9,9,,)) ((a,7,9,9,2.6,6.2)) ((a,1,2,5,7.7,5.9)) ((a,1,2,3,1.4,0.2)) �ɼ������ص����ݵĽṹȷʵ���������Ԫ�飨tuple���� 5.6 DISTINCTȥ���ڶ�ά������£���μ���ij��ά�������IJ��ظ���¼������ �������ļ� c.txt Ϊ���� [root@localhost pig]$ cat c.txt a 1 2 3 4.2 9.8 100 a 3 0 5 3.5 2.1 200 b 7 9 9 - - 300 a 7 9 9 2.6 6.2 300 a 1 2 5 7.7 5.9 200 a 1 2 3 1.4 0.2 500 ���⣺��μ����ڵ�2��3��4�е�����ά������£����һ�в��ظ��ļ�¼�ֱ��ж����������磬��2��3��4����һ��ά������ǣ�1��2��3���������ά��ά���£����һ��������ֵ��100 �� 500����˲��ظ��ļ�¼��Ϊ2��ͬ������������ļ�¼������ pig���뼰���������£� grunt> A = LOAD 'c.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double, col7:int); grunt> B = GROUP A BY (col2, col3, col4); grunt> C = FOREACH B {D = DISTINCT A.col7; GENERATE group, COUNT(D);}; grunt> DUMP C; ((1,2,3),2) ((1,2,5),1) ((3,0,5),1) ((7,9,9),1) ������ÿһ���ֱ�������ʲô�������ݣ� ��LOAD����˵�ˣ����Ǽ������ݣ� ��GROUPҲ����˵�ˣ���ǰ����˵��һ����GROUP֮��õ������������ݣ� grunt> DUMP B; ((1,2,3),{(a,1,2,3,4.2,9.8,100),(a,1,2,3,1.4,0.2,500)}) ((1,2,5),{(a,1,2,5,7.7,5.9,200)}) ((3,0,5),{(a,3,0,5,3.5,2.1,200)}) ((7,9,9),{(b,7,9,9,,,300),(a,7,9,9,2.6,6.2,300)}) ��ʵ������������۾Ϳ��Կ��������Ҫ��Ľ����ʲô�ˣ���Ȼ������Ҫ��pig��������ɣ�Ҫ��Ȼ��ôӦ�Ժ������ݣ� �������FOREACH��ǰ���е㲻һ�����������ν��“Ƕ��FOREACH”�� Ȼ���ٽ���һ�£�FOREACH�Ƕ�B��ÿһ�н��б��������У�B��ÿһ���ﺬ��һ������bag����ÿһ�����к�������Ԫ�飨tuple��A����ˣ�FOREACH ����Ĵ�������IJ�������ʵ�Ƕ���ν��“�ڲ���”��inner bag���IJ�����������ο�FOREACH��˵�����������ָ���˶�A��col7��һ�н���ȥ�أ�ȥ�صĽ��������ΪD��Ȼ���ٶ�D������COUNT�����͵õ���������Ҫ�Ľ���� �����������ݣ���ǰ�������IJ�ࡣ �����ʹ����Ŀ�ġ� ���⣬DISTINCT��������ȥ�أ�����Ϊ��Ҫ�����ݼ��ϵ�һ�𣬲�֪����Щ�������ظ��ģ���ˣ��������reduce���̡�ͬʱ����map�Σ���Ҳ������combiner����ȥ��һ�����ظ������Լӿ촦���ٶȡ� 5.7 STREAM����pig�п���Ƕ��ʹ��shell���и������������棬����һ��ʵ�ʵ�������˵���� ������ijһ��pig�����õ������������� b.txt �е����ݣ� [root@localhost pig]$ cat b.txt 1 5 98 = 7 34 8 6 3 2 62 0 6 = 65 ���⣺��ν������е�4���е�“=”����ȫ���滻Ϊ9999�� pig���뼰���������£� grunt> A = LOAD 'b.txt' AS (col1:int, col2:int, col3:int, col4:chararray, col5:int); grunt> B = STREAM A THROUGH `awk '{if($4 == "=") print $1"\t"$2"\t"$3"\t9999\t"$5; else print $0}'`; grunt> DUMP B; (1,5,98,9999,7) (34,8,6,3,2) (62,0,6,9999,65) ��������δ�������������ģ� �ټ������ݡ� ��ͨ��“STREAM … THROUGH …”�ķ�ʽ�����Ե���һ��shell��䣬�ø�shell����A��ÿһ�����ݽ��д������˴���shell��Ϊ����ijһ�����ݵĵ�4��Ϊ“=”����ʱ�������滻Ϊ“9999”���������ԭ�������һ�С� �����B���ɼ������ȷ�� ���ͳ��һ���ַ����а�����ָ���ַ���������Բ����Ǹ�Pig�������ˣ���������Ϊ��һ��shell�����⡣�ӱ���ǰ�沿�������Ѿ�֪����Pig�п����� STREAM ... THROUGH ������shell���и������ݴ����� �������ı��ļ��� [root@localhost ~]$ cat 1.txt 123 abcdef:243789174 456 DFJKSDFJ:3646:555558888 789 yKDSF:00000%0999:2343324:11111:33333 ����Ҫͳ�ƣ�ÿһ���У��ڶ�������������ð�ţ�“:”���ֱ�Ϊ���٣��������£� A = LOAD '1.txt' AS (col1: chararray, col2: chararray); B = STREAM A THROUGH `awk -F":" '{print NF-1}'` AS (colon_count: int); DUMP B; ���Ϊ�� (1) (2) (4) 5.8 �����������pig�ű�������ļ���ͨ���ⲿ����ָ���ģ���˲�������д������Ҫ���롣��pig�У�ʹ�ô���IJ���������ʾ�� STORE A INTO '$output_dir'; �����“output_dir”���Ǹ�����IJ������ڵ������pig�ű���shell�ű��У������������������ pig -param output_dir="/home/my_ourput_dir/" my_pig_script.pig ���ﴫ��IJ���“output_dir”��ֵΪ“/home/my_output_dir/”�� 5.9 COGROUP������GROUP������һ����COGROUPҲ����������ģ���ͬ���ǣ�COGROUP���������ϵ�е��ֶν��з��顣 ������һ��ʵ����˵�����������������������ļ��� [root@localhost pig]$ cat a.txt uidk 12 3 hfd 132 99 bbN 463 231 UFD 13 10 [root@localhost pig]$ cat b.txt 908 uidk 888 345 hfd 557 28790 re 00000 ������pig�����²������õ��Ľ��Ϊ�� grunt> A = LOAD 'a.txt' AS (acol1:chararray, acol2:int, acol3:int); grunt> B = LOAD 'b.txt' AS (bcol1:int, bcol2:chararray, bcol3:int); grunt> C = COGROUP A BY acol1, B BY bcol2; grunt> DUMP C; (re,{},{(28790,re,0)}) (UFD,{(UFD,13,10)},{}) (bbN,{(bbN,463,231)},{}) (hfd,{(hfd,132,99)},{(345,hfd,557)}) (uidk,{(uidk,12,3)},{(908,uidk,888)}) ÿһ������ĵ�һ��Ƿ����key���ڶ���͵�����ֱ���һ������bag�������У��ڶ����Ǹ���ǰ���key�ҵ���A�е����ݰ����������Ǹ���ǰ���key�ҵ���B�е����ݰ��� ��������һ�������“re”��Ϊgroup��keyʱ�����Ҳ�����Ӧ��A�е����ݣ���˵ڶ������һ���յİ�“{}”��“re”���key��B���ҵ��˶�Ӧ�����ݣ�28790 re 00000������˵�������ǰ�{(28790,re,0)}�� �����������Ҳ���ơ� 5.10 ͳ������������������ݣ� [root@localhost]# cat a.txt 1 3 4 7 1 3 5 4 2 7 0 5 9 8 6 6 ��������Ҫͳ�Ƶ�1��2�еIJ�ͬ����ж����֣��Ա�����˵����������֣� 1 3 2 7 9 8 Ҳ����˵����Ҫ�Ĵ���3�� ��д��ȫ����Pig���룺 A = LOAD 'a.txt' AS (col1:int, col2:int, col3:int, col4:int); B = GROUP A BY (col1, col2); C = GROUP B ALL; D = FOREACH C GENERATE COUNT(B); DUMP D; Ȼ������������Щ��������μ��������Ľ���ģ� �ٵ�һ�д���������ݣ�ûʲô��˵�ġ� �ڵڶ��д��룬�õ���1��2�����ݵ�������ϡ�B�����ݽṹΪ�� grunt> DESCRIBE B; B: {group: (col1: int,col2: int),A: {col1: int,col2: int,col3: int,col4: int}} ��B DUMP�������õ��� ((1,3),{(1,3,4,7),(1,3,5,4)}) ((2,7),{(2,7,0,5)}) ((9,8),{(9,8,6,6)}) �dz����ԣ�(1,3)��(2,7)��(9,8)����������Ѿ������г����ˣ�����õ������������ݡ���һ��Ҫ������ͳ������������һ���ж����У�Ҳ�͵õ��˵�1��2�е�����ж����顣 �۵����͵����д��룬��ʵ����ͳ�����������Ĺ��ܡ� ������Ҫ�ر�˵�����ǣ� a)Ϊʲô�����ڶ����������COUNT(B)��������COUNT(group)�� �����Ƕ�C����FOREACH������Ҫ�ȿ���C�����ݽṹ�� grunt> DESCRIBE C; C: {group: chararray,B: {group: (col1: int,col2: int),A: {col1: int,col2: int,col3: int,col4: int}}} �ɼ�������C�����һ��map�Ľṹ��key��һ��group��value��һ������bag��������������B�����������N��Ԫ�أ�ÿһ��Ԫ�ض���Ӧ��������˵��һ�С����ݢڵķ��������Ǿ���Ҫͳ��B��Ԫ�صĸ�������ˣ�������COUNT(B)�� b)COUNT������������ͳ��һ������bag���е�Ԫ�صĸ����� COUNT Computes the number of elements in a bag. ��C�����ݽṹ����B��һ��bag������COUNT�����ǿ����������ġ� �������ͼ��COUNTӦ����һ����bag�����ݽṹ�ϣ��ᷢ���������磺 java.lang.ClassCastException: org.apache.pig.data.BinSedesTuple cannot be cast to org.apache.pig.data.DataBag ���ǰ�Tuple����COUNT����ʱ�����Ĵ��� 5.11 ǿ������ת��������int a = 3 �� int b = 2���������ڴ������������a/b�õ�����1����õ���ȷ���1.5�Ļ�����Ҫת��Ϊfloat�ټ��㡣��Pig����ʵ���������һ����������ü�������������ʵ�飺 [root@localhost ~]# cat a.txt 3 2 4 5 ��Pig�У� grunt> A = LOAD 'a.txt' AS (col1:int, col2:int); grunt> B = FOREACH A GENERATE col1/col2; grunt> DUMP B; (1) (0) �ɼ�����������ת���ļ�������ȡ��֮���ֵ�� ��ô��ת��һ�����ԣ� grunt> A = LOAD 'a.txt' AS (col1:int, col2:int); grunt> B = FOREACH A GENERATE (float)(col1/col2); grunt> DUMP B; (1.0) (0.0) ����ת�����Dz��еģ���������������ԵĽ��һ��——��ֻ�ǰ�ȡ��֮�������ת��Ϊ����������˵�Ȼ���С� grunt> A = LOAD 'a.txt' AS (col1:int, col2:int); grunt> B = FOREACH A GENERATE (float)col1/col2; grunt> DUMP B; (1.5) (0.8) ��������Ҳ�У� grunt> A = LOAD 'a.txt' AS (col1:int, col2:int); grunt> B = FOREACH A GENERATE col1/(float)col2; grunt> DUMP B; (1.5) (0.8) ��ˣ���pig�����������ʱ����Ҫע����һ�㡣 5.12 UNION�������������������ļ�Ϊ�� [root@localhost ~]# cat 1.txt 0 3 1 5 0 8
[root@localhost ~]# cat 2.txt 1 6 0 9 ����Ҫ������ڵ�һ����ͬ������£��ڶ��еĺͷֱ�Ϊ���٣� ���磬��һ��Ϊ 1 ��ʱ�ڶ�����5��6����ֵ����Ϊ11��ͬ������һ��Ϊ0��ʱ�ڶ��еĺ�Ϊ 3+8+9=20�� ����������Pig�������£� A = LOAD '1.txt' AS (a: int, b: int); B = LOAD '2.txt' AS (c: int, d: int); C = UNION A, B; D = GROUP C BY $0; E = FOREACH D GENERATE FLATTEN(group), SUM(C.$1); DUMP E; ���Ϊ�� (0,20) (1,11) ����������ÿһ���ֱ�����ʲô�� �ٵ�1�С���2�д���ֱ�������ݵ���ϵA��B�У�ûʲô��˵�ġ� �ڵ�3�д��룬����ϵA��B�ϲ������ˡ��ϲ�������ݽṹΪ�� grunt> DESCRIBE C; C: {a: int,b: int} ������Ϊ�� grunt> DUMP C; (0,3) (1,5) (0,8) (1,6) (0,9) �۵�4�д��밴��1�У���$0�����з��飬���������ݽṹΪ�� grunt> DESCRIBE D; D: {group: int,C: {a: int,b: int}} ������Ϊ�� grunt> DUMP D; (0,{(0,9),(0,3),(0,8)}) (1,{(1,5),(1,6)}) �����һ�д��룬����D����D��ÿһ���������bag(��C)�ĵ�2��(��$1)�����ۼӣ��͵õ�����Ҫ�Ľ���� 5.13 �������ʽ���������Pig��ʹ���������ʽ���ַ�������ƥ��ķ����� �����������������ļ��� [root@localhost ~]# cat a.txt 1 http://ui.qq.com/abcd.html 5 http://tr.qq.com/743.html 8 http://vid.163.com/trees.php 9 http:auto.qq.com/us.php ����Ҫ�ҳ����ļ��У��ڶ��з���“*//*.qq.com/*”ģʽ�������У��˴�ֻ��ǰ���з�������������ô���� Pig�������£� A = LOAD 'a.txt' AS (col1: int, col2: chararray); B = FILTER A BY col2 matches '.*//.*\\.qq\\.com/.*'; DUMP B; matches�ؼ��ֶ� col2 ����������ƥ�䣬��ʹ�õ���Java��ʽ���������ʽƥ����� .��ʾ�����ַ���*��ʾ�ַ��������������\.��.������ת�壬��ʾƥ��.����ַ���/���DZ�ʾƥ��/����ַ��� ������Ҫע����ǣ��������У�����ת����ַ�\��Ҫ���������ܱ�ʾһ�������������\\.�����������е�\.��һ���ģ���ƥ�� . ����ַ������ԣ������Ҫƥ�����ֵĻ���Ӧ��������д����\d��ʾƥ�����֣��������б�����\\d���� B = FILTER A BY (col matches '\\d.*'); (1,http://ui.qq.com/abcd.html) (5,http://tr.qq.com/743.html) �ɼ��������ȷ�ġ� 5.14 SUBSTRING�����ڴ�������ʱ�����������ȡ��һ�������ַ�������ݣ�������ȡ��“2011-10-26”�е�“2011”�����������ú��� SUBSTRING ��ʵ�֣� SUBSTRING Returns a substring from a given string. Syntax SUBSTRING(string, startIndex, stopIndex) �����һ�����ӡ������������ļ��� [root@localhost ~]# cat a.txt 2010-05-06 abc 2008-06-18 uio 2011-10-11 tyr 2010-12-23 fgh 2011-01-05 vbn ��һ�������ڣ�����Ҫ�ҳ����в��ظ����������Щ�������������� A = LOAD 'a.txt' AS (dateStr: chararray, flag: chararray); B = FOREACH A GENERATE SUBSTRING(dateStr, 0, 4); C = DISTINCT B; DUMP C; ������Ϊ�� (2008) (2010) (2011) �ɼ��ﵽ����Ҫ��Ч���� ����Ĵ���̫���ˣ����ض��ԣ�Ψһ��Ҫ˵��һ�µ��� SUBSTRING ���������ĵ�һ��������Ҫ��ȡ���ַ������ڶ�����������ʼ��������0��ʼ���������������ǽ��������� 5.15 CONCAT�������������������ļ��� [root@localhost ~]# cat 1.txt abc 123 cde 456 fgh 789 ijk 200 ����Ҫ�ѵ�һ�к͵ڶ�����Ϊ�ַ���ƴ�������������һ�л���“abc123”����ôʹ��CONCAT�����ֵ������eval function���Ϳ��������� A = LOAD '1.txt' AS (col1: chararray, col2: int); B = FOREACH A GENERATE CONCAT(col1, (chararray)col2); DUMP B; ������Ϊ�� (abc123) (cde456) (fgh789) (ijk200) ע����������ڼ������ݵ�ʱ��ѵڶ���ָ��Ϊint���ͣ�����Ϊ��˵���������Ͳ�һ�µ�ʱ��CONCAT������� ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1045: Could not infer the matching function for org.apache.pig.builtin.CONCAT as multiple or none of them fit. Please use an explicit cast. �����ں���CONCAT��ʱ�Եڶ��н���������ת���� ���⣬��������ļ�����Ϊ�� [root@localhost ~]# cat 1.txt 5 123 7 456 8 789 0 200 ��ô���������������CONCAT�� A = LOAD '1.txt' AS (col1: int, col2: int); B = FOREACH A GENERATE CONCAT(col1, col2); ͬ��Ҳ������� ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1045: Could not infer the matching function for org.apache.pig.builtin.CONCAT as multiple or none of them fit. Please use an explicit cast. Ҫƴ�Ӽ����ַ�����CONCAT �� CONCAT �Ϳ����ˡ� 5.16 JOIN�����������������������ļ��� [root@localhost ~]# cat 1.txt 123 456 789 200 �Լ��� [root@localhost ~]# cat 2.txt 200 333 789 ����Ҫ�ҳ������ļ��У���ͬ���ݵ�������Ҳ������ν�����������ݼ����غϡ� �ù�ϵ������JOIN�����Դﵽ���Ŀ�ġ��ڴ�����������ʱ�������������غϵ���������JOIN��Pig��һ��������Ҫ�IJ����� �ڱ����У������ļ�����������ͬ�������У�789�Լ�200����ˣ����Ӧ����2�� ��������������ȷ�Ĵ��룺 A = LOAD '1.txt' AS (a: int); B = LOAD '2.txt' AS (b: int); C = JOIN A BY a, B BY b; D = GROUP C ALL; E = FOREACH D GENERATE COUNT(C); DUMP E; �ٵ�һ�������Ǽ������ݡ� �ڵ����а�A�ĵ�1�С�B�ĵڶ��н���“���”��JOIN֮��a��b���в���ͬ�����ݾͱ������ˡ�C�����ݽṹΪ�� C: {A::a: int,B::b: int} C������Ϊ�� (200,200) (789,789) ����������Ҫͳ�Ƶ����������������������Pig�����еĵ�4��5�оͽ����˼��������㡣 ������ļ� 2.txt ��һ������“200”�����Ϊ3�С����ʱ��C������Ϊ�� (200,200) (200,200) (789,789) ���������Ҫȥ���ظ��ģ�����Ҫ��DISTINCE��C����һ�£� A = LOAD '1.txt' AS (a: int); B = LOAD '2.txt' AS (b: int); C = JOIN A BY a, B BY b; uniq_C = DISTINCT C; D = GROUP uniq_C ALL; E = FOREACH D GENERATE COUNT(uniq_C); DUMP E; �����õ��Ľ������2�� ������Ҫע����ǣ����JOIN�����о��в�ͬ���������ͣ��ǻ�ʧ�ܵġ��������´��룺 A = LOAD '1.txt' AS (a: int); B = LOAD '2.txt' AS (b: chararray); C = JOIN A BY a, B BY b; D = GROUP C ALL; E = FOREACH D GENERATE COUNT(C); DUMP E; �������û�д���ģ�����һ���оͻᱨ���� ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1107: Cannot merge join keys, incompatible types ������Ϊa��b���в�ͬ�����ͣ�int��chararray�� ���ܶ�ͬһ����ϵ��relation������JOIN��������ʾ�� �����������ļ��� [root@localhost ~]# cat 1.txt 1 a 2 e 3 v 4 n ����Ե�һ������JOIN�� A = LOAD '1.txt' AS (col1: int, col2: chararray); B = JOIN A BY col1, A BY col1; ��ô������ͼ DUMP B ��ʱ�ᱨ���µĴ��� ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1108: Duplicate schema alias: A::col1 in "B" ������ΪPig��Ū����JOIN֮����ֶ���——�����ֶξ�ΪA::col1��ʹ��һ����ϵ��relation���г������ظ������֣����Dz������ġ� Ҫ���������⣬ֻ�轫����LOAD���Σ����Ҹ�������ͬ�����־Ϳ����ˣ� grunt> A = LOAD '1.txt' AS (col1: int, col2: chararray); grunt> B = LOAD '1.txt' AS (col1: int, col2: chararray); grunt> C = JOIN A BY col1, B BY col1; grunt> DESCRIBE C; C: {A::col1: int,A::col2: chararray,B::col1: int,B::col2: chararray} grunt> DUMP C; (1,a,1,a) (2,e,2,e) (3,v,3,v) (4,n,4,n) ������C��schema�����Կ������������ͬһ����ϵA�ĵ�һ�н���JOIN���ᵼ��schema�г�����ͬ���ֶ��������Ե�Ȼ������� ����ʹ��JOINʱ��һ����ʹ�õĶ�����ν��“�ڲ���JOIN”(inner JOIN)��Ҳ�������� C = JOIN A BY col1, B BY col2 ������JOIN��PigҲ֧��“�ⲿ��JOIN”(outer JOIN)������;�һ�����ӡ� �������ļ��� [root@localhost ~]# cat 1.txt 1 a 2 e 3 v 4 n �Լ��� [root@localhost ~]# cat 2.txt 9 a 2 e 3 v 0 n ���������������ļ��ĵ�һ����һ��outer JOIN�� grunt> A = LOAD '1.txt' AS (col1: int, col2: chararray); grunt> B = LOAD '2.txt' AS (col1: int, col2: chararray); grunt> C = JOIN A BY col1 LEFT OUTER, B BY col1; grunt> DESCRIBE C; C: {A::col1: int,A::col2: chararray,B::col1: int,B::col2: chararray} grunt> DUMP C; (1,a,,) (2,e,2,e) (3,v,3,v) (4,n,,) ��outer JOIN�У�“OUTER”�ؼ����ǿ���ʡ�Եġ�������Ľ�������Կ������������һ��inner JOIN�������������ļ��ĵ�һ�������ж���������ڽ���У���Ϊ���ǵĵ�һ�в���ͬ��������LEFT OUTER JOIN�У��ļ�1.txt�ĵ�һ������ȴ������ˣ����������LEFT OUTER JOIN���ص㣺����ߵļ�¼��˵����ʹ�����ұߵļ�¼��ƥ�䣬��Ҳ�ᱻ��������������С� ͬ����֪RIGHT OUTER JOIN�Ĺ���——������� LEFT ���� RIGHT��������£� (,,0,n) (2,e,2,e) (3,v,3,v) (,,9,a) �ɼ�������ߵļ�¼��ƥ����ұߵļ�¼������������������ߵļ�¼û�б����������������ű�����Ϊ�գ��������RIGHT OUTER JOIN��Ч������Ԥ�ڵ�һ���� ����OUTERJOIN���ô�����һ�����ӣ�����������“����ij���ݼ��е���Щ���ݣ��������غϵ����ݣ�”����������������������ļ�Ϊ����������Ҫ��� 1.txt �У���һ�в��� 2.txt �еĵ�һ�е���Щ��¼��1��4������������ 2.txt �ĵ�һ����û�г��֣���2��3�����ˣ���ˣ�����Ҫ�ҵļ�¼���ǣ� 1 a 4 n Ҫʵ�����Ч����Pig���뼰���Ϊ�� grunt> A = LOAD '1.txt' AS (col1: int, col2: chararray); grunt> B = LOAD '2.txt' AS (col1: int, col2: chararray); grunt> C = JOIN A BY col1 LEFT OUTER, B BY col1; grunt> DESCRIBE C; C: {A::col1: int,A::col2: chararray,B::col1: int,B::col2: chararray} grunt> D = FILTER C BY (B::col1 is null); grunt> E = FOREACH D GENERATE A::col1 AS col1, A::col2 AS col2; grunt> DUMP E; (1,a) (4,n) �ɼ���ȷʵ�ҳ���“���غϵļ�¼”�������������ݷ���ʱ�����ֹ����Ǽ�Ϊ���õġ� �����һ���ܽ �������������ݼ�����1.txt��2.txt�У����ֱ�ֻ��1�У������´��룺 A = LOAD '1.txt' AS (col1: chararray); B = LOAD '2.txt' AS (col1: chararray); C = JOIN A BY col1 LEFT OUTER, B BY col1; D = FILTER C BY (B::col1 is null); E = FOREACH D GENERATE A::col1 AS col1; DUMP E; ������Ϊ����A�У�������B�еļ�¼�� 5.17 ��Ŀ�����ʹ����Ŀ�����“ ? : ”��������š� ���������������ļ��� [root@localhost ~]# cat a.txt 5 8 9 6 0 4 3 1 ���У��ڶ��еĵڶ�����������ȱʧ�ģ���ˣ���������֮�������Ϊnull��˳��ϻ�һ�䣬�ڴ�����������ʱ��������ȱʧ�Ǿ������������� ���ڣ����Ҫ������ȱʧ��������Ϊ -1�� ����ʹ����Ŀ������������� A = LOAD 'a.txt' AS (col1:int, col2:int, col3:int); B = FOREACH A GENERATE col1, ((col2 is null)? -1 : col2), col3; DUMP B; ������Ϊ�� (5,8,9) (6,-1,0) (4,3,1) ((col2 is null)? -1 : col2) �ĺ��岻�ý�����Ҳ֪�������ǵ�col2Ϊnull��ʱ������Ϊ-1������ͱ���ԭ����ֵ������ע�⣬�����������������������ģ����ȥ�����ţ�д�� (col2 is null)? -1 : col2����ô�ͻ�������� ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1000: Error during parsing. Encountered " "is" "is "" at line 1, column 36. Was expecting one of ������ʡ�ԣ� ������ʾ�е㲻ֱ�ۡ����ԣ���ʱ��ʹ����Ŀ������DZ���Ҫʹ�����ŵġ� 5.18 ����ȱʧ�����������ļ����£� [root@localhost ~]# cat 1.txt 1 (4,9) 5 8 (3,0) 5 (9,2) 6 ��Щ���ݵIJ��ֱȽϹ֣�Ҫ�������س�ʲô����schema�أ��𣺵�һ��Ϊһ��int���ڶ���Ϊһ��tuple����tuple�ֺ�����int�������м��еڶ�����������ȱʧ�ġ� ���⣺�������ڵ�һ��������ͬ������£��ڶ��������еĵ�һ�������ĺͷֱ�Ϊ���٣� ���磬��һ��Ϊ1������ֻ��һ�У�����һ�У�����ˣ��ڶ��еĵ�һ�������ĺ;���4�� ���Ƕ����һ�У�Ҳ���ǵ�һ��Ϊ6ʱ��������ڶ�������ȱʧ������ϣ��������Ľ����0�� ��������Pig���룺 A = LOAD '1.txt' AS (a:int, b:tuple(x:int, y:int)); B = FOREACH A GENERATE a, FLATTEN(b); C = GROUP B BY a; D = FOREACH C GENERATE group, SUM(B.x); DUMP D; ���Ϊ�� (1,4) (5,9) (6,) (8,3) (5��9) ��һ�����������ļ� 1.txt �ĵ� 2��4�м���õ��ģ����У���2��������ȱʧ�����Ⲣ��Ӱ����ͼ��㣬��Ϊ��һ������û��ȱʧ������������룺һ������bag�����ж������������һ��Ϊnull����������Ϊnullʱ����������ӻ��Զ�����null�� Ȼ���������� (6,) �Dz���̫�����ˣ�û������Ϊ�����ļ� 1.txt �����һ��ȱʧ�˵ڶ��У����ԣ��� SUM(B.x) �е� B.x Ϊnull�ͻᵼ�¼�����Ϊnull���Ӷ�ʲôҲ������ˡ� �������������������е㲻ͬ�ˡ�����ϣ������ȱʧ�����ݲ�Ҫ���ţ��������0�� �뷨1�� D = FOREACH C GENERATE group, ((IsEmpty(B.x)) ? 0 : SUM(B.x)); ������Ϊ�� (1,4) (5,9) (6,) (8,3) �ɼ��в�ͨ��������������֪����IsEmpty(B.x) Ϊfalse����B.x����empty�ģ����Բ����������� �뷨2�� D = FOREACH C GENERATE group, ((B.x is null) ? 0 : SUM(B.x)); ����������������һ������Ȼ�в�ͨ���������ˣ�B.x�ȷ�empty��Ҳ��null����ô����ʲô����������ҵ����⣬��groupΪ6ʱ����Ӧ����һ���ǿյİ���bag����������һ��null�Ķ��������ԣ����������empty�ģ���Ҳ��null���Ҳ�֪�����������Ƿ���ȷ������������ȥ�����������ġ� �뷨3�� D = FOREACH C GENERATE group, SUM(B.x) AS s; E = FOREACH D GENERATE group, ((s is null) ? -1 : s); DUMP E; ������Ϊ�� (1,4) (5,9) (6,-1) (8,3) �ɼ��ﵽ��������Ҫ�Ľ�������뱾��ǰ�沿�ֵ�������һ�µģ������ȵõ���null�Ľ�����ٰ��������е�null�滻Ϊָ����ֵ�� 5.19 Scalars projections“Scalars can be only used with projections”�����ԭ�� �������һ�������Ӹ��������ʾһ�²�����������ԭ��֮һ�� ���������������ļ��� [root@localhost ~]$ cat 1.txt a 1 b 8 c 3 c 3 d 6 d 3 c 5 e 7 ����Ҫͳ�ƣ��ڵ�1�е�ÿһ������£��ڶ���Ϊ3��6�����ݷֱ��ж������� ���磬����1��Ϊ c ʱ���ڶ���Ϊ3��������2����Ϊ6��������0��������1��Ϊdʱ���ڶ���Ϊ3��������1����Ϊ6��������1�����������������ơ� Pig�������£� A = LOAD '1.txt' AS (col1:chararray, col2:int); B = GROUP A BY col1; C = FOREACH B { D = FILTER A BY col2 == 3; E = FILTER A BY col2 == 6; GENERATE group, COUNT(D), COUNT(E); }; DUMP C; ������Ϊ�� (a,0,0) (b,0,0) (c,2,0) (d,1,1) (e,0,0) �ɼ��������ȷ�ġ� ��ô�������������Ĵ����У���“D = FILTER A BY col2 == 3”��С��д����“D = FILTER B BY col2 == 3”���Ϳ϶���õ�“Scalars can be only used with projections”�Ĵ�����ʾ�� Ƕ�ģ�nested��FOREACH���ڲ��ģ�inner��FOREACH��һ����˼������������ʾ��һ��FOREACH���Զ�ÿһ����¼ʩ�Զ��ֲ�ͬ�Ĺ�ϵ������Ȼ����GENERATE�õ���Ҫ�Ľ���������Ƕ��/�ڲ���FOREACH�� 5.20 Pig��ʹ�������ַ��������Pig��ʹ��������ΪFILTER�������� �����ļ� data.txt ����Ϊ��ÿһ��֮����TABΪ�ָ������� 1 ������ a 2 �Ϻ��� b 3 ������ c 4 ������ f 5 ����� e Pig�ű��ļ� test.pig ����Ϊ�� A = LOAD 'data.txt' AS (col1: int, col2: chararray, col3: chararray); B = FILTER A BY (col2 == '������'); DUMP B; ���ȣ��������ļ��ı��붼��UTF-8(��BOM)����Linux�������£�ֱ���Ա���ģʽִ��Pig�ű� test.pig�� pig -x local test.pig �õ���������Ϊ�� (1,������,a) (3,������,c) (4,������,f) �ɼ��������ȷ�ġ� ���ǣ������grunt����ģʽ�£��� test.pig ������ճ����ȥִ�У��ǵò����κ��������ģ� grunt> A = LOAD 'data.txt' AS (col1: int, col2: chararray, col3: chararray); grunt> B = FILTER A BY (col2 == '������'); grunt> DUMP B; ����ʹ��������ΪFILTER��������ֻҪ���ڽ���ģʽ��ִ�����Pig�ű����ɡ� 5.21 ��������1. Ҫ��Pig job�����ȼ���ΪHIGH��ֻ����Pig�ű��Ŀ�ͷ����һ�䣺 set job.priority HIGH; ���ɽ�Pig job�����ȼ���Ϊ���ˡ� 2. ����Pig job��job name ��Pig�ű���ͷ����һ�䣺 set job.name 'My-Job-Name'; ��ô��ִ�и�Pig�ű�֮����Hadoop��Job Tracker�п�����“Name”����“My-Job-Name”�ˡ� ��������ã���ʾ��name��������“Job6245768625829738970.jar”�����Ķ�����job���ʱ����ȫû�б�ʶ�ȣ�����һ��Ҫ����һ�������job name�� 3. UDF�����ִ�Сд�� ��ΪUDF����Java����ʵ�ֵģ��������ִ�Сд������ô�� 4. Pig�е�����operator�����������ᴥ��reduce���̣� ��GROUP������GROUP�����Ὣ���о�����ͬkey�ļ�¼�ռ���һ�����������������map�д����Ļ����ͻᴥ��shuffle→reduce�Ĺ��̡� ��ORDER��������Ҫ��������ȵļ�¼�ռ���һ�𣨲�����������ORDER�ᴥ��reduce���̡�ͬʱ�������Ǹ�Pig job֮�⣬Pig��������һ�������M-R job�����������У���ΪPig��Ҫ�����ݼ�����������ȷ�����ݵķֲ�������Ӷ�������ݷֲ����ز����������jobЧ�ʹ��ڵ��µ����⡣ ��DISTINCT��������Ҫ����¼�ռ���һ�𣬲���ȷ�������Dz����ظ��ģ����DISTINCT�ᴥ��reduce���̡���Ȼ��DISTINCTҲ������combiner��map�ξͰ��ظ��ļ�¼�Ƴ��� ��JOIN��JOIN�������غϣ��������غϵ�ʱ����Ҫ��������ͬkey�ļ�¼�ռ���һ����ˣ�JOIN�ᴥ��reduce���̡� ��LIMIT��������Ҫ����¼�ռ���һ�𣬲���ͳ�Ƴ������ص���������ˣ�LIMIT�ᴥ��reduce���̡� ��COGROUP����GROUP���ƣ��ο�����ǰ��IJ��֣���������ᴥ��reduce���̡� ��CROSS����������������ϵ�IJ���� 6 Pig����6.1 Hadoop 2.x.0 yarn����������master������Mapreduceû�����⣬������slave�ڵ������лᱨ���´��� [root@fk01 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.2.0.jar wordcount /input /ouput3 14/08/21 10:41:18 WARN util.NativeCodeLoader: Unable to load native- hadoop library for your platform... using builtin-java classes where applicable 14/08/21 10:41:18 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 14/08/21 10:41:19 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS) 14/08/21 10:41:20 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS) 14/08/21 10:41:21 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 2 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS) 14/08/21 10:41:22 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 3 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS) 14/08/21 10:41:23 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 4 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS) 14/08/21 10:41:24 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 5 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS) 14/08/21 10:41:25 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 6 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS) ...................... ����취Ϊ��yare-site.xml������������Ϣ�� <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> 6.2 �汾������������Hadoop2.x.0��pig0.13.0���й����У�hadoop��pig grunt��������������dump���ݱ�����Ĵ��� ERROR 1066: Unable to open iterator for alias actor org.apache.pig.impl.logicalLayer.FrontendException: ERROR 1066: Unable to open iterator for alias actor at org.apache.pig.PigServer.openIterator(PigServer.java:880) at org.apache.pig.tools.grunt.GruntParser.processDump(GruntParser.java:774) at org.apache.pig.tools.pigscript.parser.PigScriptParser.parse(PigScriptParser.java:372) at org.apache.pig.tools.grunt.GruntParser.parseStopOnError(GruntParser.java:198) at org.apache.pig.tools.grunt.GruntParser.parseStopOnError(GruntParser.java:173) at org.apache.pig.tools.grunt.Grunt.run(Grunt.java:69) at org.apache.pig.Main.run(Main.java:541) at org.apache.pig.Main.main(Main.java:156) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at org.apache.hadoop.util.RunJar.main(RunJar.java:212) Caused by: java.io.IOException: Job terminated with anomalous status FAILED at org.apache.pig.PigServer.openIterator(PigServer.java:872) ... 12 more ����������ֵ�ԭ����pig�Ѿ������jar�ļ���hadoop�İ汾�����ݵ��µģ����Բ������±���ķ���������⣬������ʾ�� (1) cd /${PIG_HOME} (2) mv pig-0.10.1-withouthadoop.jar pig-0.10.1-withouthadoop.jar.bak (3) mv pig-0.10.1.jar pig-0.10.1.jar.bak (4) ant clean jar-withouthadoop -Dhadoopversion=23 ������ɺ���${PIG_HOME}/buildĿ������ɣ� pig-0.12.0-SNAPSHOT-core.jar, pig-0.12.0-SNAPSHOT-withouthadoop.jar (5) ����һ�����ɵ������ļ�Copy��${PIG_HOME}�£������и����� pig-0.12.0-SNAPSHOT-core.jar --> pig-0.12.0.jar pig-0.12.0-SNAPSHOT-withouthadoop.jar --> pig-0.12.0-withouthadoop.jar 7 �ο�����������Ҫ�ο�����IJ��ģ� http://www.codelast.com/?p=3621 |