|
本文总结了apache hive 的部署使用。 目录[-]
1 产品概述1.1 产品功能Apache Hive数据仓库软件提供对存储在分布式中的大型数据集的查询和管理,它本身是建立在Apache Hadoop之上,主要提供以下功能: 1. 它提供了一系列的工具,可用来对数据进行提取/转化/加载(ETL);是一种可以存储、查询和分析存储在HDFS(或者HBase)中的大规模数据的机制;查询是通过MapReduce来完成的(并不是所有的查询都需要MapReduce来完成,比如select * from XXX就不需要;在Hive0.11对类似select a,b from XXX的查询通过配置也可以不通过MapReduce来完成); 2. Hive是一种建立在Hadoop文件系统上的数据仓库架构,并对存储在HDFS中的数据进行分析和管理; 3. Hive定义了一种类似SQL的查询语言,被称为HQL,对于熟悉SQL的用户可以直接利用Hive来查询数据。同时,这个语言也允许熟悉MapReduce开发者们开发自定义的mappers和reducers来处理内建的mappers和reducers无法完成的复杂的分析工作。Hive可以允许用户编写自己定义的函数UDF,在查询中使用。Hive中有3种UDF:User Defined Functions(UDF)、User Defined Aggregation Functions(UDAF)、User Defined Table Generating Functions(UDTF)。 现在,Hive已经是一个成功的Apache项目,很多组织把它用作一个通用的、可伸缩的数据处理平台。 Hive和传统的关系型数据库有很大的区别,Hive将外部的任务解析成一个MapReduce可执行计划,而启动MapReduce是一个高延迟的一件事,每次提交任务和执行任务都需要消耗很多时间,这也就决定Hive只能处理一些高延迟的应用(如果想处理低延迟的应用,可以考虑一下Hbase)。同时,由于设计的目标不一样,Hive目前还不支持事务;不能对表数据进行修改。 1.2 Hive和传统数据库进行比较Hive在很多方面和RMDB类似,比如说它支持SQL接口;但是由于其它底层设计的原因,对HDFS和Mapreduce有很强的依赖,这也就意味这Hive的体系结构和RMDB有很大的区别。这些区别又间接的影响到Hive所支持的一些特性。 在传统的RMDB中,表的模式是在数据加载的时候强行确定好的。如果在加载时发现数据不符合模式,则拒绝加载这些数据。而Hive在加载的过程中不对数据进行任何的验证操作,其只是简单的将数据复制或者移动到表对应的目录下面。从这方面来说,传统数据库在数据加载的过程中比Hive要慢。但是因为传统数据库在数据加载过程中可以进行一些处理,比如对某一列建立索引等,这样可以提升数据的查询性能。而在这方面Hive不行。
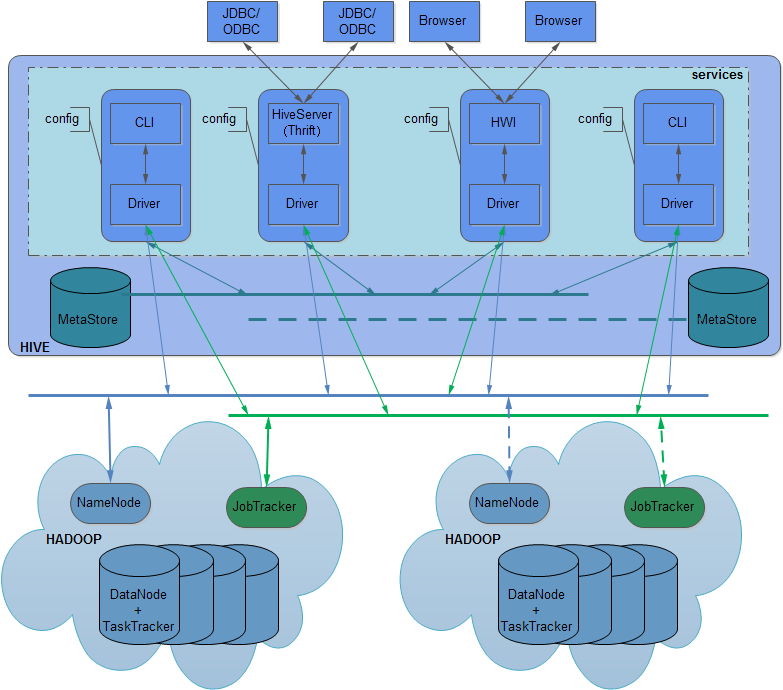
从上表可以看出,Hive和传统的数据库还是有很多的区别。 Hive的SQL方言一般被称为HiveQL,在下文我们简称HQL。在上面我们提到,HQL并不完全支持SQL92标准。这个也是有原因的。遵循SQL92从Hive的设计开始就不是它的目标。 1.3 应用场景Hive目前主要应用在海量数据处理、数据挖掘、数据分析等方面,hive是针批量对长时间数据分析设计的,不能做交互式的实时查询。 2 产品架构Hive产品架构如下图所示:
Hive架构图中涉及服务、元数据、Hdfs、Mapreduce等信息,下面分别进行说明: 2.1 服务hive有三种service,分别是cli,hiveserver和hwi。 1. cli是命令行工具,为默认服务,启动方式$HIVE_HOME/bin/hive 或 $HIVE_HOME/bin/hive --service cli。 2. hiverserver通过thrift对外提供服务,默认端口10000,启动方式为$HIVE_HOME/bin/hive--service hiveserver。 3. hwi为web接口,可以通过浏览器访问hive,默认端口9999,启动方式为$HIVE_HOME/bin/hive--service hwi。 每个服务间互相独立,有各自的配置文件(配置metasotre/namenode/jobtracker等),如果metasotre的配置一样则物理上对应同一hive库。 Driver用于解释、编译、优化、执行HQL,每个service的Driver相互独立。 CLI为用户提供命令行接口,每个CLI独享配置,即在一个CLI里修改配置不影响别的CLI。 多个JDBC可同时连到同一HiveServer上,所有会话共享一份配置。(注:从0.9.0起hiveserver配置已经从global降为session,即每个session的配置相互独立) 多个浏览器可同时连到同一HWI上,所有会话共享一份配置。 Hive可以在运行时用–service选项来明确指定使用的服务类型,可以用下面的--service help来查看帮助,如下: [wyp@master ~]$ hive --service help Usage ./hive <parameters> --service serviceName <service parameters> Service List: beeline cli help hiveserver2 hiveserver hwi jar lineage metastore metatool orcfiledump rcfilecat Parameters parsed: --auxpath : Auxillary jars --config : Hive configuration directory --service : Starts specific service/component. cli is default Parameters used: HADOOP_HOME or HADOOP_PREFIX : Hadoop install directory HIVE_OPT : Hive options For help on a particular service: ./hive --service serviceName --help Debug help: ./hive --debug –help 上面的输出项Service List,里面显示出Hive支持的服务列表:beeline cli help hiveserver2 hiveserver hwi jar lineage metastore metatool orcfiledump rcfilecat,下面介绍最常用的一些服务。 (1)cli:这个就是Command Line Interface的简写,是Hive的命令行界面,用的比较多。这是默认的服务,直接可以在命令行里面使用。 (2)hiveserver:这个可以让Hive以提供Trift服务的服务器形式来运行,允许许多不同语言编写的客户端进行通信。使用时需要启动HiveServer服务以和客户端联系,可以通过设置HIVE_PORT环境变量来设置服务器所监听的端口号,在默认的情况下,端口为10000。可以通过下面方式来启动hiveserver: [wyp@master ~]$ bin/hive --service hiveserver -p 10002 Starting Hive Thrift Server 其中-p参数也是用来指定监听端口的。 (3)hwi:其实就是hive web interface的缩写,它是Hive的Web接口,是hive cli的一个web替换方案。 (4)jar:与Hadoop jar等价的Hive的接口,这是运行类路径中同时包含Hadoop和Hive类的Java应用程序的简便方式。 (5)metastore:在默认情况下,metastore和Hive服务运行在同一个进程中。使用这个服务,可以让metastore作为一个单独的进程运行,可以通过METASTORE_PORT来指定监听的端口号,具体如下图所示:
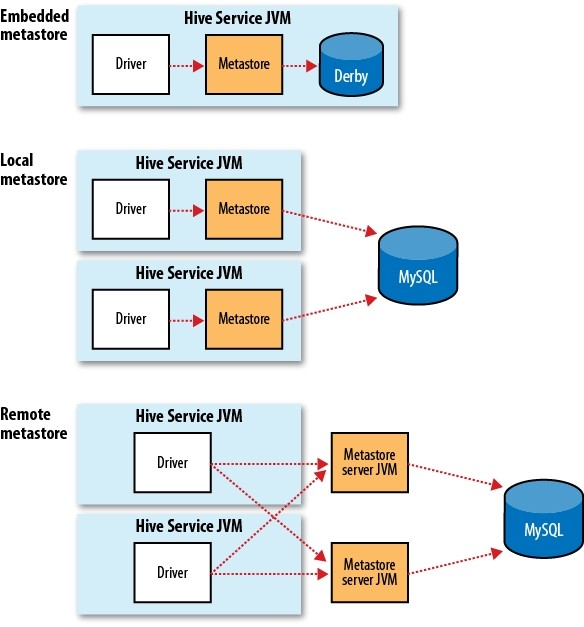
2.2 元数据Hive的数据分为表数据和元数据,表数据是Hive中表格(table)具有的数据;而元数据是用来存储表的名字,表的列和分区及其属性(是否为外部表等),表的数据所在目录等。 元数据位置通过参数javax.jdo.option.ConnectionURL来指定,可在会话中自由修改。相关的参数包括: javax.jdo.option.ConnectionDriverName #数据库驱动 javax.jdo.option.ConnectionURL #数据库ip端口库名等 javax.jdo.option.ConnectionUserName #用户名 javax.jdo.option.ConnectionPassword #密码 通过修改这些参数可以在多个MetaStore间热切换,可用于HA。 2.3 NameNode与JobTrackerNameNode由fs.default.name指定,JobTracker由mapred.job.tracker指定,这两个参数都可以在会话中自由修改来指向不同的NameNode和JobTracker。 配合MetaStore可以有多种组合出现,例如在同一个MetaStore里让table1的数据存在HDFS1,用JobTracker1计算,table2的数据存在HDFS2,用JobTracker2计算,或者让两个表都在JobTracker3上计算。 NameNode和JobTracker最好指向同一个集群,否则计算的时候需要跨集群复制数据。 在MetaStore存储的是表数据文件的绝对路径,当心其与NameNode/ JobTracker不在同一个集群里导致跨集群复制。 对hiveserver与hwi配置的修改会作用到同一service上的所有会话。(注:从0.9.0起hiveserver配置已经从global降为session,即每个session的配置相互独立)。 3 安装部署Hive最新版本是apache-hive-0.13.1-bin.tar.gz,下载地址为http://apache.fayea.com/apache-mirror/hive/hive-0.13.1/。 下载后,选个目录,解压,命令如下: # tar -zxvf hive-0.10.0.tar.gz 现在需要配置Hive,才能够运行Hive。进入conf文件夹,将hive-default.xml.template文件的内容复制到hive-site.xml文件中,操作如下: #cd conf/ #cp hive-default.xml.template hive-site.xml 在hive-site.xml文件中进行如下配置: <property> <name>hive.metastore.warehouse.dir</name> <value>/home/wyp/cloud/hive/warehouse</value> <description>location of default database for the warehouse</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive_hdp?characterEncoding=UTF-8&createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> <description>password to use against metastore database</description> </property> Hive将元数据存储在RDBMS中,比如MySQL、Derby中。Hive默认是用Derby数据库,这里修改为MySQL(所以要确保电脑上已经安装好了MySQL数据库)。需要将mysql驱动jar包mysql-connector-java-5.1.22-bin.jar拷贝到$HIVE_HOME/lib/目录下。然后编辑/etc/profile文件,将Hive的home目录添加进去,操作如下: #sudo vim /etc/profile 在其中添加下面语句,修改Hive的home路径为解压的目录: export HIVE_HOME=/home/...hive-0.10.0 PATH=$PATH:$HIVE_HOME/bin 最后让上面的修改生效,请运行下面的命令: #source /etc/profile 现在可以试一下,hive是否安装好(需要启动Hadoop,否则不能运行成功!): #hive hive> 如果出现了上述情况,说明hive安装成功。
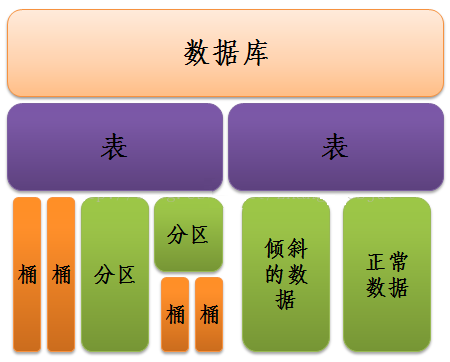
4 数据存储模式1. Hive的数据存储 Hive是基于Hadoop分布式文件系统的,它的数据存储在Hadoop分布式文件系统中。Hive本身是没有专门的数据存储格式,也没有为数据建立索引,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。所以往Hive表里面导入数据只是简单的将数据移动到表所在的目录中(如果数据是在HDFS上;但如果数据是在本地文件系统中,那么是将数据复制到表所在的目录中)。 Hive中主要包含以下几种数据模型:Table(表),External Table(外部表),Partition(分区),Bucket(桶)。 a. 表:Hive中的表和关系型数据库中的表在概念上很类似,每个表在HDFS中都有相应的目录用来存储表的数据,这个目录可以通过${HIVE_HOME}/conf/hive-site.xml配置文件中的hive.metastore.warehouse.dir属性来配置,这个属性默认的值是/user/hive/warehouse(这个目录在HDFS上),我们可以根据实际的情况来修改这个配置。如果我有一个表wyp,那么在HDFS中会创建/user/hive/warehouse/wyp目录(这里假定hive.metastore.warehouse.dir配置为/user/hive/warehouse);wyp表所有的数据都存放在这个目录中。这个例外是外部表。 b.外部表:Hive中的外部表和表很类似,但是其数据不是放在自己表所属的目录中,而是存放到别处,这样的好处是如果你要删除这个外部表,该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;而如果你要删除表,该表对应的所有数据包括元数据都会被删除。 c.分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。比如wyp表有dt和city两个分区,则对应dt=20131218,city=BJ对应表的目录为/user/hive/warehouse/dt=20131218/city=BJ,所有属于这个分区的数据都存放在这个目录中。 d.桶:对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。比如将wyp表id列分散至16个桶中,首先对id列的值计算hash,对应hash值为0和16的数据存储的HDFS目录为:/user/hive/warehouse/wyp/part-00000;而hash值为2的数据存储的HDFS 目录为:/user/hive/warehouse/wyp/part-00002。 Hive数据抽象结构如下图所示:
2.Hive的元数据 Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。由于Hive的元数据需要不断的更新、修改,而HDFS系统中的文件是多读少改的,这显然不能将Hive的元数据存储在HDFS中。目前Hive将元数据存储在数据库中,如Mysql、Derby中。我们可以通过以下的配置来修改Hive元数据的存储方式。 <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive_hdp?characterEncoding=UTF-8 &createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> <description>password to use against metastore database</description> </property> 还需要将连接对应数据库的依赖包复制到${HIVE_HOME}/lib目录中,这样才能将元数据存储在对应的数据库中。
5 基本操作5.1 Hive内置数据类型Hive的内置数据类型可以分为两大类:(1)基础数据类型;(2)复杂数据类型。其中,基础数据类型包括:TINYINT,SMALLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,STRING,BINARY,TIMESTAMP,DECIMAL,CHAR,VARCHAR,DATE。下面的表格列出这些基础类型所占的字节以及从什么版本开始支持这些类型。
复杂类型包括ARRAY,MAP,STRUCT,UNION,这些复杂类型是由基础类型组成的。 ARRAY:ARRAY类型是由一系列相同数据类型的元素组成,这些元素可以通过下标来访问。比如有一个ARRAY类型的变量fruits,它是由['apple','orange','mango']组成,那么我们可以通过fruits[1]来访问元素orange,因为ARRAY类型的下标是从0开始的; MAP:MAP包含key->value键值对,可以通过key来访问元素。比如”userlist”是一个map类型,其中username是key,password是value;那么我们可以通过userlist['username']来得到这个用户对应的password; STRUCT:STRUCT可以包含不同数据类型的元素。这些元素可以通过”点语法”的方式来得到所需要的元素,比如user是一个STRUCT类型,那么可以通过user.address得到这个用户的地址。 UNION: UNIONTYPE,他是从Hive 0.7.0开始支持的。 创建一个包含复制类型的表格可以如下: CREATE TABLE employees ( name STRING, salary FLOAT, subordinates ARRAY<STRING>, deductions MAP<STRING, FLOAT>, address STRUCT<street:STRING, city:STRING, state:STRING, zip:INT> ) PARTITIONED BY (country STRING, state STRING); 5.2 Hive参数配置方法Hive提供三种可以改变环境变量的方法,分别是:(1)修改${HIVE_HOME}/conf/hive-site.xml配置文件;(2)命令行参数;(3)在已经进入cli时进行参数声明。下面分别介绍这几种设定。 方法一: 在Hive中,所有的默认配置都在${HIVE_HOME}/conf/hive-default.xml文件中,如果需要对默认的配置进行修改,可以创建一个hive-site.xml文件,放在${HIVE_HOME}/conf目录下。里面可以对一些配置进行个性化设定。在hive-site.xml的格式如下: <configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>location of default database for the warehouse</description> </property> </configuration> 所有的配置都是放在<configuration></configuration>标签之间,一个configuration标签里面可以存在多个<property></property>标签。<name>标签里面就是要设定属性的名称;<value>标签里面是要设定的值;<description>标签描述这个属性的作用。绝大多少配置都是在xml文件里面配置的,因为在这里做的配置都全局用户都生效,而且是永久的。用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。 方法二: 在启动Hive cli的时候进行配置,可以在命令行添加-hiveconf param=value来设定参数,例如: # hive --hiveconf mapreduce.job.queuename=queue1 这样在Hive中所有MapReduce作业都提交到队列queue1中。这一设定对本次启动的会话有效,下次启动需要重新配置。 方法三: 在已经进入cli时进行参数声明,可以在HQL中使用SET关键字设定参数,例如: hive> set mapreduce.job.queuename=queue1; 这样也能达到方法二的效果。这种配置也是对本次启动的会话有效,下次启动需要重新配置。在HQL中使用SET关键字还可以查看配置的值,如下: hive> set mapreduce.job.queuename; mapreduce.job.queuename=queue1 我们可以得到mapreduce.job.queuename=queue1。如果set后面什么都不添加,这样可以查到Hive的所有属性配置,如下: hive> set; datanucleus.autoCreateSchema=true 上述三种设定方式的优先级依次递增。即参数声明覆盖命令行参数,命令行参数覆盖配置文件设定。 5.3 Hive日志调试在很多程序中,可以通过输出日志的形式来得到程序的运行情况,通过这些输出日志来调试程序。 在Hive中,使用的是Log4j来输出日志,默认情况下,CLI是不能将日志信息输出到控制台的。在Hive0.13.0之前版本,默认的日志级别是WARN,从Hive0.13.0开始,默认的日志级别是INFO。默认的日志存放在/tmp/<user.name>文件夹的hive.log文件中,即/tmp/<user.name>/hive.log。 在默认的日志级别情况下,不能将DEBUG信息输出,这样一来出现的各种详细的错误信息是不能输出的。但是可以通过以下两种方式修改log4j输出的日志级别,从而利用这些调试日志进行错误定位,具体做法如下: # hive --hiveconf hive.root.logger=DEBUG,console 或者在${HIVE_HOME}/conf/hive-log4j.properties文件中找到hive.root.logger属性,并将其修改为下面的设置 hive.root.logger=DEBUG,console 上面两种方法的设置各有优劣,方法一的设定只是对本次会话有效,下次如果还想修改日志输出级别需要重新设定,但是不是每时每刻都需要修改日志的输出级别,所以在有时需要修改输出的日志级别,有时不需要的时候可以用这种方法;方法二将日志输出级别设定到文件中去了,这个设定是对所有的用户都生效,而且每次使用HQL的时候都会输出一大堆的日志,这种情况适合那些无时无刻都需要HQL的运行日志的用户。 5.4 hiveQL插入语法1. Insert基本语法格式为: INSERT OVERWRITE TABLE tablename [PARTITON(partcol1=val1,partclo2=val2)]select_statement FROM from_statement 示例:insert overwrite table test_insert select * from test_table; 2. 对多个表进行插入操作: FROM fromstatte INSERT OVERWRITE TABLE tablename1 [PARTITON(partcol1=val1,partclo2=val2)]select_statement1 INSERT OVERWRITE TABLE tablename2 [PARTITON(partcol1=val1,partclo2=val2)]select_statement2 示例: from test_table insert overwrite table test_insert1 select key insert overwrite table test_insert2 select value; insert的时候,from子句即可以放在select子句后面,也可以放在 insert子句前面。 hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。数据是以load的方式加载到建立好的表中。数据一旦导入就不可以修改。 3.通过查询将数据保存到filesystem INSERT OVERWRITE [LOCAL] DIRECTORY directory SELECT.... FROM ..... 导入数据到本地目录: insert overwrite local directory '/home/zhangxin/hive' select * from test_insert1; 产生的文件会覆盖指定目录中的其他文件,即将目录中已经存在的文件进行删除。 导出数据到HDFS中: insert overwrite directory '/user/zhangxin/export_test' select value from test_table; 同一个查询结果可以同时插入到多个表或者多个目录中: from test_insert1 insert overwrite local directory '/home/zhangxin/hive' select * insert overwrite directory '/user/zhangxin/export_test' select value; Hive insert into语句的标准语法如下: 用法一: INSERT OVERWRITE TABLE tablename1 [PARTITION \ (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] \ select_statement1 FROM from_statement; 用法二: INSERT INTO TABLE tablename1 [PARTITION \ (partcol1=val1, partcol2=val2 ...)] \ select_statement1 FROM from_statement; 举例: hive> insert into table cite > select * from tt; 这样就会将tt表格里面的数据追加到cite表格里面。并且在cite数据存放目录生成了一个新的数据文件,这个新文件是经过处理的,列之间的分割是cite表格的列分割符,而不是tt表格列的分隔符。 (1) 如果两个表格的维度不一样,将会插入错误: hive> insert into table cite > select * from cite_standby; FAILED: SemanticException [Error 10044]: Line 1:18 Cannot insert into target table because column number/types are different 'cite': Table insclause-0 has 2 columns, but query has 1 columns. 从上面错误提示看出,查询的表格cite_standby只有一列,而目标表格(也就是需要插入数据的表格)有2列,由于列的数目不一样,导致了上面的语句不能成功运行,我们需要保证查询结果列的数目和需要插入数据表格的列数目一致,这样才行。 (2) 在用extended关键字创建的表格上插入数据将会影响到其它的表格的数据,因为他们共享一份数据文件。 (3) 如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,比如如果查询出来的数据类型为int,插入表格对应的列类型为string,可以通过转换将int类型转换为string类型;但是如果查询出来的数据类型为string,插入表格对应的列类型为int,转换过程可能出现错误,因为字母就不可以转换为int,转换失败的数据将会为NULL。 (4) 可以将一个表查询出来的数据插入到原表中: hive> insert into table cite > select * from cite; 结果就是相当于复制了一份cite表格中的数据。 (5) 和insert overwrite的区别: hive> insert overwrite table cite > select * from tt; 上面的语句将会用tt表格查询到的数据覆盖cite表格已经存在的数据。 5.5 hiveQL删除语法hiveQL删除语法如下所示: hive> TRUNCATE TABLE t; 这样将会删掉表格t关联的所有数据,但会保留表和metadata的完整性。 5.6 hiveQL执行文件Hive可以运行保存在文件里面的一条或多条的语句,只要用-f参数,一般情况下,保存这些Hive查询语句的文件通常用.q或者.hql后缀名,但是这不是必须的,你也可以保存你想要的后缀名。假设test文件里面有一下的Hive查询语句: select * from p limit 10; select count(*) from p; 那么我们可以用下面的命令来查询: #bin/hive -f test ........这里省略了一些输出........... OK 196 242 3 881250949 20131102 jx 186 302 3 891717742 20131102 jx 22 377 1 878887116 20131102 jx 244 51 2 880606923 20131102 jx Time taken: 4.386 seconds, Fetched: 4 row(s) ........这里省略了一些输出........... OK 4 Time taken: 16.284 seconds, Fetched: 1 row(s) 如果你配置好了Hive shell的路径,你可以用SOURCE命令来运行那个查询文件: [wyp@wyp hive-0.11.0-bin]$ hive hive> source /home/.../test; ........这里省略了一些输出........... ........这里省略了一些输出........... OK 196 242 3 881250949 20131102 jx 186 302 3 891717742 20131102 jx 22 377 1 878887116 20131102 jx 244 51 2 880606923 20131102 jx Time taken: 4.386 seconds, Fetched: 4 row(s) ........这里省略了一些输出........... OK 4 Time taken: 16.284 seconds, Fetched: 1 row(s)
6 数据导入导出6.1 Hive数据导入的方式Hive目前有四种导入数据的方式: (1)从本地文件系统中导入数据到Hive表; (2)从HDFS上导入数据到Hive表; (3)从别的表中查询出相应的数据并导入到Hive表中; (4)在创建表的时候通过从别的表中查询出相应的记录并插入到所创建的表中。 6.1.1 本地导入先在Hive中建表,如下: hive> create table wyp > (id int , name string, > age int , tel string) > ROW FORMAT DELIMITED > FIELDS TERMINATED BY '\t' > STORED AS TEXTFILE; OK Time taken: 2.832 seconds 这个表很简单,只有四个字段。本地文件系统中有个/home/wyp/wyp.txt文件,内容如下: [wyp @master ~]$ cat wyp.txt 1 wyp 25 13188888888888 2 test 30 13888888888888 3 zs 34 899314121 wyp.txt文件中的数据列之间是使用\t分割的,可以通过下面的语句将这个文件里面的数据导入到wyp表里面,操作如下: hive> load data local inpath 'wyp.txt' into table wyp; Copying data from file:/home/wyp/wyp.txt Copying file: file:/home/wyp/wyp.txt Loading data to table default .wyp Table default .wyp stats: [num_partitions: 0 , num_files: 1 , num_rows: 0 , total_size: 67 ] OK Time taken: 5.967 seconds 这样就将wyp.txt里面的内容导入到wyp表里面去了,可以到wyp表的数据目录下查看,如下命令: hive> dfs -ls /user/hive/warehouse/wyp ; Found 1 items -rw-r--r-- 3 wyp supergroup 67 2014 - 02 - 19 18 : 23 /hive/warehouse/wyp/wyp.txt 数据的确导入到wyp表里面去了。 和关系型数据库不一样,Hive现在还不支持在insert语句里面直接给出一组记录的文字形式,也就是说,Hive并不支持INSERT INTO .... VALUES形式的语句。 6.1.2 HDFS导入从本地文件系统中将数据导入到Hive表的过程中,其实是先将数据临时复制到HDFS的一个目录下(典型的情况是复制到上传用户的HDFS home目录下,比如/home/wyp/),然后再将数据从那个临时目录下移动(注意,这里说的是移动,不是复制!)到对应的Hive表的数据目录里面。既然如此,那么Hive肯定支持将数据直接从HDFS上的一个目录移动到相应Hive表的数据目录下,假设有下面这个文件/home/wyp/add.txt,具体的操作如下: [wyp@master /home/q/hadoop-2.2.0]$ bin/hadoop fs -cat /home/wyp/add.txt 5 wyp1 23 131212121212 6 wyp2 24 134535353535 7 wyp3 25 132453535353 8 wyp4 26 154243434355 上面是需要插入数据的内容,这个文件是存放在HDFS上/home/wyp目录(和本地导入的不同,本地导入中提到的文件是存放在本地文件系统上)里面,可以通过下面的命令将这个文件里面的内容导入到Hive表中,具体操作如下: hive> load data inpath '/home/wyp/add.txt' into table wyp; Loading data to table default.wyp Table default.wyp stats: [num_partitions: 0, num_files: 2, num_rows: 0, total_size: 215] OK Time taken: 0.47 seconds
hive> select * from wyp; OK 5 wyp1 23 131212121212 6 wyp2 24 134535353535 7 wyp3 25 132453535353 8 wyp4 26 154243434355 1 wyp 25 13188888888888 2 test 30 13888888888888 3 zs 34 899314121 Time taken: 0.096 seconds, Fetched: 7 row(s) 从上面的执行结果可以看到,数据的确导入到wyp表中了!请注意load data inpath ‘/home/wyp/add.txt’ into table wyp;里面是没有local这个单词的,这个是和本地导入方式的区别。 6.1.3 别的表查询导入假设Hive中有test表,其建表语句如下所示: hive> create table test( > id int, name string > ,tel string) > partitioned by > (age int) > ROW FORMAT DELIMITED > FIELDS TERMINATED BY '\t' > STORED AS TEXTFILE; OK Time taken: 0.261 seconds 大体和wyp表的建表语句类似,只不过test表里面用age作为了分区字段。下面语句将wyp表中的查询结果插入到test表中: hive> insert into table test > partition (age='25') > select id, name, tel > from wyp; ################################################################# 这里输出了一堆Mapreduce任务信息,这里省略 ################################################################# Total MapReduce CPU Time Spent: 1 seconds 310 msec OK Time taken: 19.125 seconds hive> select * from test; OK 5 wyp1 131212121212 25 6 wyp2 134535353535 25 7 wyp3 132453535353 25 8 wyp4 154243434355 25 1 wyp 13188888888888 25 2 test 13888888888888 25 3 zs 899314121 25 Time taken: 0.126 seconds, Fetched: 7 row(s) 通过上面的输出,我们可以看到从wyp表中查询出来的东西已经成功插入到test表中去了!如果目标表(test)中不存在分区字段,可以去掉partition (age=’25′)语句。当然,也可以在select语句里面通过使用分区值来动态指明分区: hive> set hive.exec.dynamic.partition.mode=nonstrict; hive> insert into table test > partition (age) > select id, name, > tel, age > from wyp; ################################################################# 这里输出了一堆Mapreduce任务信息,这里省略 ################################################################# Total MapReduce CPU Time Spent: 1 seconds 510 msec OK Time taken: 17.712 seconds hive> select * from test; OK 5 wyp1 131212121212 23 6 wyp2 134535353535 24 7 wyp3 132453535353 25 1 wyp 13188888888888 25 8 wyp4 154243434355 26 2 test 13888888888888 30 3 zs 899314121 34 Time taken: 0.399 seconds, Fetched: 7 row(s) 这种方法叫做动态分区插入,但是Hive中默认是关闭的,所以在使用前需要先把hive.exec.dynamic.partition.mode设置为nonstrict。当然,Hive也支持insert overwrite方式来插入数据,从字面可以看出,overwrite是覆盖的意思,执行完这条语句的时候,相应数据目录下的数据将会被覆盖,而insert into则不会。例子如下: hive> insert overwrite table test > PARTITION (age) > select id, name, tel, age > from wyp; Hive还支持多表插入,在Hive中,可以把insert语句倒过来,把from放在最前面,它的执行效果和放在后面是一样的,如下: hive> show create table test3; OK CREATE TABLE test3( id int, name string) Time taken: 0.277 seconds, Fetched: 18 row(s) hive> from wyp > insert into table test > partition(age) > select id, name, tel, age > insert into table test3 > select id, name > where age>25;
hive> select * from test3; OK 8 wyp4 2 test 3 zs Time taken: 4.308 seconds, Fetched: 3 row(s) 可以在同一个查询中使用多个insert子句,这样只需要扫描一遍源表就可以生成多个不相交的输出。 6.1.4 创建表时导入在实际情况中,表的输出结果可能太多,不适于显示在控制台上,这时候,将Hive的查询输出结果直接存在一个新的表中是非常方便的,称这种情况为CTAS(create table as select)如下: hive> create table test4 > as > select id, name, tel > from wyp; hive> select * from test4; OK 5 wyp1 131212121212 6 wyp2 134535353535 7 wyp3 132453535353 8 wyp4 154243434355 1 wyp 13188888888888 2 test 13888888888888 3 zs 899314121 Time taken: 0.089 seconds, Fetched: 7 row(s) 数据就插入到test4表中去了,CTAS操作是原子的,因此如果select查询由于某种原因而失败,新表是不会创建的。 6.2 Hive数据导出的方式Hive根据导出的地方不同可以将导出方式分为三种:(1)导出到本地文件系统;(2)导出到HDFS中;(3)导出到Hive的另一个表中,下面逐一介绍。 6.2.1 导出到本地文件系统hive> insert overwrite local directory '/home/wyp/wyp' > select * from wyp; 这条HQL的执行需要启用Mapreduce完成,运行完这条语句之后,将会在本地文件系统的/home/wyp/wyp目录下生成文件,这个文件是Reduce产生的结果(这里生成的文件名是000000_0),我们可以看看这个文件的内容: [wyp@master ~/wyp]$ vim 000000_0 5^Awyp1^A23^A131212121212 6^Awyp2^A24^A134535353535 7^Awyp3^A25^A132453535353 8^Awyp4^A26^A154243434355 1^Awyp^A25^A13188888888888 2^Atest^A30^A13888888888888 3^Azs^A34^A899314121 可以看出,这是wyp表中的所有数据。数据中的列与列之间的分隔符是^A(ascii码是\00001)。 在Hive 0.11.0版本之前,数据的导出是不能指定列之间的分隔符的,只能用默认的列分隔符,也就是上面的^A来分割,这样导出来的数据很不直观,看起来很不方便。 如果用的Hive版本是0.11.0和之后版本,可以在导出数据的时候来指定列之间的分隔符,操作如下: hive> insert overwrite local directory '/home/yangping.wu/local' > row format delimited > fields terminated by '\t' > select * from wyp;
[wyp@master ~/local]$ vim 000000_0 5 wyp1 23 131212121212 6 wyp2 24 134535353535 7 wyp3 25 132453535353 8 wyp4 26 154243434355 1 wyp 25 13188888888888 2 test 30 13888888888888 3 zs 34 899314121 其实,还可以用hive的-e和-f参数来导出数据。其中-e表示后面直接接带双引号的sql语句;而-f是接一个文件,文件的内容为一个sql语句,如下: [wyp@master ~/local]$ hive -e "select * from wyp" >> local/wyp.txt [wyp@master ~/local]$cat wyp.txt 5 wyp1 23 131212121212 6 wyp2 24 134535353535 7 wyp3 25 132453535353 8 wyp4 26 154243434355 1 wyp 25 13188888888888 2 test 30 13888888888888 3 zs 34 899314121 得到的结果也是用\t分割的。也可以用-f参数实现: [wyp@master ~/local]$ cat wyp.sql select * from wyp [wyp@master ~/local]$ hive -f wyp.sql >> local/wyp2.txt 上述语句得到的结果也是\t分割的。 6.2.2 导出到HDFS中和导入数据到本地文件系统一样的简单,可以用下面的语句实现: hive> insert overwrite directory '/home/wyp/hdfs' > select * from wyp; 将会在HDFS的/home/wyp/hdfs目录下保存导出来的数据。注意,和导出文件到本地文件系统的HQL少一个local,数据的存放路径就不一样了。 6.2.3 导出到Hive的另一个表中hive> insert into table test > partition (age='25') > select id, name, tel > from wyp; ################################################################# 这里输出了一堆Mapreduce任务信息,这里省略 ################################################################# Total MapReduce CPU Time Spent: 1 seconds 310 msec OK Time taken: 19.125 seconds hive> select * from test; OK 5 wyp1 131212121212 25 6 wyp2 134535353535 25 7 wyp3 132453535353 25 8 wyp4 154243434355 25 1 wyp 13188888888888 25 2 test 13888888888888 25 3 zs 899314121 25 Time taken: 0.126 seconds, Fetched: 7 row(s) 其实就是讲hive中一个表的内容导入到另一个表中。 7 Hive索引索引是标准的数据库技术,hive 0.7版本之后支持索引。Hive提供有限的索引功能,这不像传统的关系型数据库那样有“键(key)”的概念,用户可以在某些列上创建索引来加速某些操作,给一个表创建的索引数据被保存在另外的表中。 Hive的索引功能现在还相对较晚,提供的选项还较少。但是,索引被设计为可使用内置的可插拔的java代码来定制,用户可以扩展这个功能来满足自己的需求。用户可以使用EXPLAIN语法来分析HiveQL语句是否可以使用索引来提升用户查询的性能。像RDBMS中的索引一样,需要评估索引创建的是否合理,毕竟,索引需要更多的磁盘空间,并且创建维护索引也会有一定的代价。 用户必须要权衡从索引得到的好处和代价。 下面介绍创建索引的方法: 1. 先创建表: hive> create table a3( id int, name string) > ROW FORMAT DELIMITED > FIELDS TERMINATED BY '\t' > STORED AS TEXTFILE; 2. 导入数据: hive> load data local inpath 'apache-hive-0.13.1-bin/a21.txt' > overwrite into table a3; Copying data from file:/usr/local/apache-hive-0.13.1-bin/a21.txt Copying file: file:/usr/local/apache-hive-0.13.1-bin/a21.txt Loading data to table default.a3 rmr: DEPRECATED: Please use 'rm -r' instead. Deleted hdfs://localhost:9000/user/hive/warehouse/a3 Table default.a3 stats: [numFiles=1, numRows=0, totalSize=169, rawDataSize=0] OK Time taken: 0.468 seconds 3. 创建索引之前测试 hive> select * from a3 where id=28; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1414112118511_0001, Tracking URL = http://h77.hadoop.org:8088/proxy/application_1414112118511_0001/ Kill Command = /usr/local/hadoop-2.4.1/bin/hadoop job -kill job_1414112118511_0001 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2014-10-24 09:12:11,220 Stage-1 map = 0%, reduce = 0% 2014-10-24 09:12:16,404 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.13 sec MapReduce Total cumulative CPU time: 1 seconds 130 msec Ended Job = job_1414112118511_0001 MapReduce Jobs Launched: Job 0: Map: 1 Cumulative CPU: 1.13 sec HDFS Read: 375 HDFS Write: 8 SUCCESS Total MapReduce CPU Time Spent: 1 seconds 130 msec OK 28 fdah Time taken: 14.007 seconds, Fetched: 1 row(s) 一共用了14.007s 4. 对user创建索引 hive> create index a3_index on table a3(id) > as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' > with deferred rebuild > in table a3_index_table; OK Time taken: 0.292 seconds hive> alter index a3_index on a3 rebuild > ; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks not specified. Estimated from input data size: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1414112118511_0002, Tracking URL = http://h77.hadoop.org:8088/proxy/application_1414112118511_0002/ Kill Command = /usr/local/hadoop-2.4.1/bin/hadoop job -kill job_1414112118511_0002 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2014-10-24 09:13:52,094 Stage-1 map = 0%, reduce = 0% 2014-10-24 09:13:57,265 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.75 sec 2014-10-24 09:14:03,479 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 1.81 sec MapReduce Total cumulative CPU time: 1 seconds 810 msec Ended Job = job_1414112118511_0002 Loading data to table default.a3_index_table rmr: DEPRECATED: Please use 'rm -r' instead. Deleted hdfs://localhost:9000/user/hive/warehouse/a3_index_table Table default.a3_index_table stats: [numFiles=1, numRows=20, totalSize=1197, rawDataSize=1177] MapReduce Jobs Launched: Job 0: Map: 1 Reduce: 1 Cumulative CPU: 1.81 sec HDFS Read: 375 HDFS Write: 1277 SUCCESS Total MapReduce CPU Time Spent: 1 seconds 810 msec OK Time taken: 17.976 seconds hive> select * from a3_index_table; OK 1 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [0] 2 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [6] 3 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [12] 6 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [40] 8 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [18] 12 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [46] 18 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [54] 21 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [22] 28 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [128] 78 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [119] 83 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [136] 98 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [153] 123 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [27] 129 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [161] 234 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [80,109] 812 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [144] 891 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [34] 1231 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [70,88] 2134 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [61] 7897 hdfs://localhost:9000/user/hive/warehouse/a3/a21.txt [98] Time taken: 0.041 seconds, Fetched: 20 row(s) 这样对user表创建了一个索引。 5、对创建索引后的user再进行测试 hive> select * from a3 where id=28; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1414112118511_0003, Tracking URL = http://h77.hadoop.org:8088/proxy/application_1414112118511_0003/ Kill Command = /usr/local/hadoop-2.4.1/bin/hadoop job -kill job_1414112118511_0003 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2014-10-24 09:15:40,439 Stage-1 map = 0%, reduce = 0% 2014-10-24 09:15:46,617 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.21 sec MapReduce Total cumulative CPU time: 1 seconds 210 msec Ended Job = job_1414112118511_0003 MapReduce Jobs Launched: Job 0: Map: 1 Cumulative CPU: 1.21 sec HDFS Read: 375 HDFS Write: 8 SUCCESS Total MapReduce CPU Time Spent: 1 seconds 210 msec OK 28 fdah Time taken: 11.924 seconds, Fetched: 1 row(s) 时间用了11.924s比没有创建索引的效果好些,数据量大的时候效果会更明显。 8 JDBC连接Hive Server可以通过CLI、Client、Web UI等Hive提供的用户接口来和Hive通信,但这三种方式最常用的是CLI;Client是Hive的客户端,用来连接至Hive Server。在启动Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。WUI是通过浏览器访问 Hive。下面介绍通过HiveServer来操作Hive。 Hive提供了JDBC驱动,使得我们可以用Java代码来连接Hive并进行一些类关系型数据库的SQL语句查询等操作。同关系型数据库一样,也需要将Hive的服务打开;在Hive 0.11.0版本之前,只有HiveServer服务可用,得在程序操作Hive之前,在安装Hive的服务器上打开HiveServer服务,如下所示: #bin/hive --service hiveserver -p 10002 Starting Hive Thrift Server 上面代表你已经成功的在端口为10002(默认的端口是10000)启动了hiveserver服务。这时候,你就可以通过Java代码来连接hiveserver,代码如下: import java.sql.SQLException; import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; import java.sql.DriverManager;
public class Testmzl {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException { try { Class.forName(driverName); } catch (ClassNotFoundException e) { e.printStackTrace(); System.exit(1); }
Connection con = DriverManager.getConnection( "jdbc:hive://192.168.1.77:10002/default", "", ""); Statement stmt = con.createStatement(); String tableName = "wyp"; stmt.execute("drop table if exists " + tableName); stmt.execute("create table " + tableName + " (key int, value string)"); System.out.println("Create table success!"); // show tables String sql = "show tables"; System.out.println("Running: " + sql); ResultSet res = stmt.executeQuery(sql); while (res.next()) { System.out.println(res.getString(1)); }
// describe table sql = "describe " + tableName; System.out.println("Running: " + sql); res = stmt.executeQuery(sql); while (res.next()) { System.out.println(res.getString(1) + "\t" + res.getString(2)); }
sql = "select * from " + tableName; res = stmt.executeQuery(sql); while (res.next()) { System.out.println(String.valueOf(res.getInt(1)) + "\t" + res.getString(2)); }
sql = "select count(1) from " + tableName; System.out.println("Running: " + sql); res = stmt.executeQuery(sql); while (res.next()) { System.out.println(res.getString(1)); } } } 编译上面的代码,之后就可以运行,结果如下: Create table success! Running: show tables 'wyphao' wyphao Running: describe wyphao key int value string Running: select count(1) from wyphao 0 上面用Java连接HiveServer,而HiveServer本身存在很多问题(比如:安全性、并发性等);针对这些问题,Hive0.11.0版本提供了一个全新的服务:HiveServer2,这个很好的解决HiveServer存在的安全性、并发性等问题。这个服务启动程序在${HIVE_HOME}/bin/hiveserver2里面,可以通过下面的方式来启动HiveServer2服务: $HIVE_HOME/bin/hiveserver2 也可以通过下面的方式启动HiveServer2: $HIVE_HOME/bin/hive --service hiveserver2 两种方式效果一样。但是之前的java程序需要修改两个地方,如下所示: private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver"; 改为 private static String driverName = "org.apache.hive.jdbc.HiveDriver";
Connection con = DriverManager.getConnection("jdbc:hive://localhost:10002/default", "", ""); 改为 Connection con = DriverManager.getConnection("jdbc:hive2://localhost:10000/default", "", ""); 其他的不变就可以了。
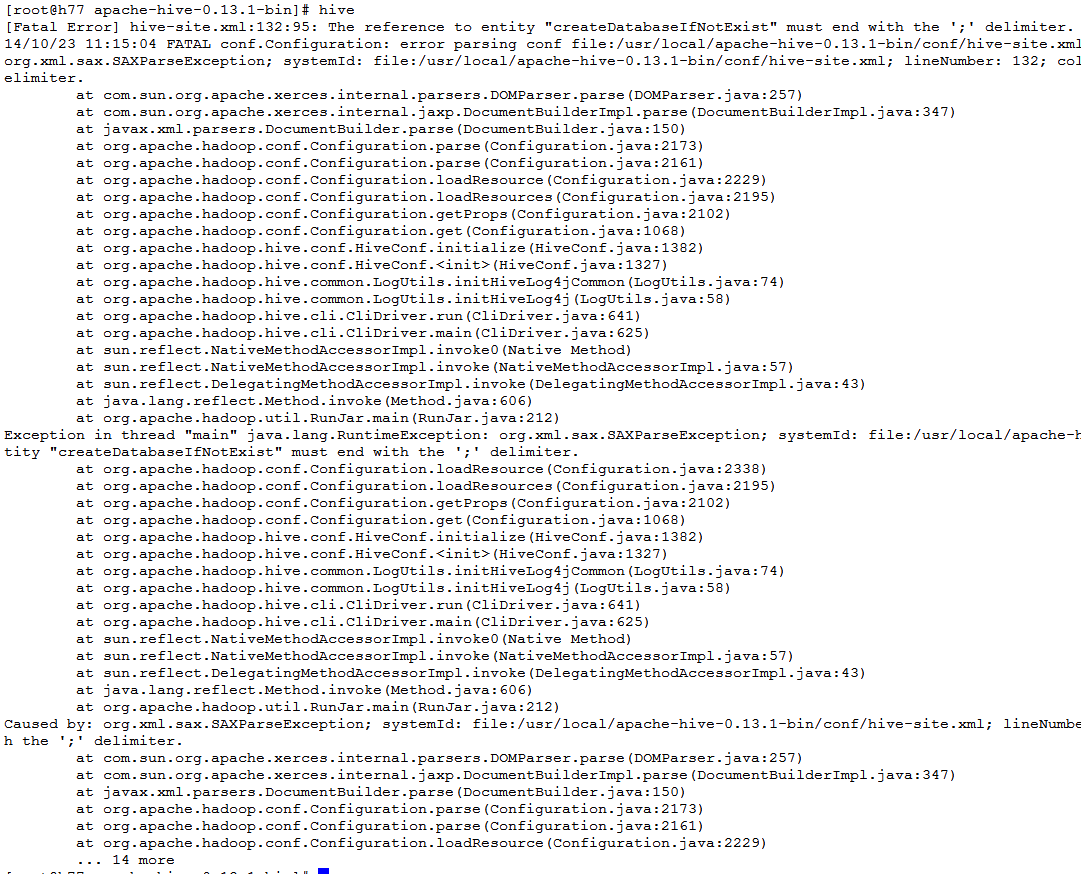
9 常见问题9.1 disabled stack guard在安装运行hadoop时会出现下面的错误: Hadoop 2.2.0 - warning: You have loaded library /home/hadoop/2.2.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. 具体出错内容如下: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/2.2.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'. localhost] sed: -e expression #1, char 6: unknown option to `s' HotSpot(TM): ssh: Could not resolve hostname HotSpot(TM): Name or service not known 64-Bit: ssh: Could not resolve hostname 64-Bit: Name or service not known Java: ssh: Could not resolve hostname Java: Name or service not known Server: ssh: Could not resolve hostname Server: Name or service not known VM: ssh: Could not resolve hostname VM: Name or service not known 解决方法: [root@h77 hadoop-2.4.1]#vim etc/hadoop/hadoop-env.sh 在HADOOP_PREFIX变量的定义后面,HADOOP_OPTS变量的定义前面添加下列变量: export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib" 9.2 javax.jdo.option.ConnectionURL配置的问题Hive安装过程中出现 The reference to entity "createDatabaseIfNotExist" must end with the ';' delimiter.问题,具体如下所示: [Fatal Error] hive-site.xml:132:95: The reference to entity "createDatabaseIfNotExist" must end with the ';' delimiter. 14/10/23 11:15:04 FATAL conf.Configuration: error parsing conf file:/usr/local/apache-hive-0.13.1-bin/conf/hive-site.xml org.xml.sax.SAXParseException; systemId: file:/usr/local/apache-hive-0.13.1-bin/conf/hive-site.xml; lineNumber: 132; columnNumber: 95; The reference to entity "createDatabaseIfNotExist" must end with the ';' delimiter. 显示如下图所示:
因为hive-site.xml中的javax.jdo.option.ConnectionURL配置项引起的,如下所示: <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive_hdp?characterEncoding=UTF-8&createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> 正确配置如下: <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive_hdp?characterEncoding=UTF-8&createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> 这是因为xml文件中的编码规则引起的。 在xml文件中有以下几类字符要进行转义替换如下表所示:
所以javax.jdo.option.ConnectionURL项中的&符号需要用&表示。 10 Hive优化10.1 简单查询不启用Mapreduce job如果你想查询某个表的某一列,Hive默认是会启用MapReduce Job来完成这个任务: hive> SELECT id, money FROM m limit 10; Total MapReduce jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Cannot run job locally: Input Size (= 235105473) is larger than hive.exec.mode.local.auto.inputbytes.max (= 134217728) Starting Job = job_1384246387966_0229, Tracking URL =
http://l-datalogm1.data.cn1:9981/proxy/application_1384246387966_0229/
Kill Command = /home/q/hadoop-2.2.0/bin/hadoop job -kill job_1384246387966_0229 hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2013-11-13 11:35:16,167 Stage-1 map = 0%, reduce = 0% 2013-11-13 11:35:21,327 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.26 sec 2013-11-13 11:35:22,377 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.26 sec MapReduce Total cumulative CPU time: 1 seconds 260 msec Ended Job = job_1384246387966_0229 MapReduce Jobs Launched: Job 0: Map: 1 Cumulative CPU: 1.26 sec HDFS Read: 8388865 HDFS Write: 60 SUCCESS Total MapReduce CPU Time Spent: 1 seconds 260 msec OK 1 122 1 185 1 231 1 292 1 316 1 329 1 355 1 356 1 362 1 364 Time taken: 16.802 seconds, Fetched: 10 row(s) 启用MapReduce Job会消耗系统开销,对于这个问题,从Hive0.10.0版本开始,对于简单的不需要聚合的类似SELECT <col> from <table> LIMIT n语句,不需要起MapReduce job,直接通过Fetch task获取数据,可以通过下面几种方法实现: 方法一: hive> set hive.fetch.task.conversion=more; hive> SELECT id, money FROM m limit 10; OK 1 122 1 185 1 231 1 292 1 316 1 329 1 355 1 356 1 362 1 364 Time taken: 0.138 seconds, Fetched: 10 row(s) 上面set hive.fetch.task.conversion=more;开启了Fetch任务,所以对于上述简单的列查询不再启用MapReduce job。 方法二: bin/hive --hiveconf hive.fetch.task.conversion=more 方法三: 上面的两种方法都可以开启了Fetch任务,但是都是临时起作用的;如果你想一直启用这个功能,可以在${HIVE_HOME}/conf/hive-site.xml里面加入以下配置: <property> <name>hive.fetch.task.conversion</name> <value>more</value> <description>Some select queries can be converted to single FETCH task minimizing latency.Currently the query should be single sourced not having any subquery and should not have any aggregations or distincts (which incurrs RS), lateral views and joins. 1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only 2. more : SELECT, FILTER, LIMIT only (+TABLESAMPLE, virtual columns) </description> </property> 这样就可以长期启用Fetch任务了。
11 参考博文本文主要参考下面的博文: http://www.iteblog.com/archives/category/hive (责任编辑:IT) |