|
Hadoop近几年一直很热门,市面上有各种各样的书籍以及培训机构,当你熟悉完这些准备在生产上运行自己的第一个生产Hadoop集群的时候,就需要考虑购买什么样的硬件了,专业人士肯定会说:“这要看你的业务类型和负载了”,当然这是很有道理的,但是我接触的很多企业在生产部署Hadoop之前还没有完全的大概的知道自己的运行job的类型,到底是耗IO类型的还是耗CPU类型的,又或者是两个都有,这个预估对有些企业来说是很难的。但是总是有一些基本的遴选方法的。我们把Job分为两种类型:
IO-bound workloads:
先不讨论每次加载的数据量问题,处理这种类型的job,每个cpu的主频在2Ghz~2.6Ghz之间是足够的
CPU-bound workloads:
处理这种类型的job,每个cpu的主频在2.8Ghz~3Ghz之间是足够的
先看看Hadoop的最基础的两个组件:HDFS(NameNode+DataNode+Standby)和MapReduce(JobTracker+TaskTrackers)
Namenode负责协调整个集群上的数据存储,Namenode需要RAM存储集群内部数据的block原信息,一个比较靠谱的经验是,Namenode上面1GB的RAM可以支撑1 million的block信息,64GB的RAM可以支撑100 million的block信息。 JobTracker负责协调整个集群上的数据处理。 Standby NameNode不是Namenode的HA,Standby NameNode不应该运行在集群内的Namenode节点上,而是应用部署在和Namenode相同的独立硬件上面。建议在运行NameNode和JobTracker的服务器上配置Raid1和冗余电源。 Datanode负责集群上的数据存储。 TaskTrackers负责集群上的数据处理。
4–6 SAS 1TB hard disks in a JBOD configuration (1 for the OS[RAID 1], 2 for the FS image [RAID 1], and 1 for Journal node) 2×8,2×10,2×12 core CPUs, running at least 2-2.5GHz 64-128GB of RAM Bonded Gigabit Ethernet or 10Gigabit Ethernet
12-24 SATA 2-8TB hard disks in a JBOD 2×8,2×10,2×12 core CPUs, running at least 2-2.5GHz 64-512GB of RAM Bonded Gigabit Ethernet or 10Gigabit Ethernet
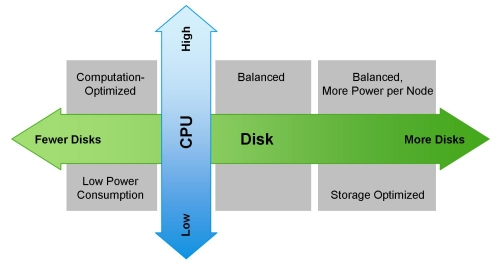
下面是一些针对不同负载任务类型的硬件建议: Light Processing Configuration (1U/machine): 两颗六核处理器,24-64GB内存,8块硬盘(单盘2TB or 4TB) Balanced Compute Configuration (1U/machine): 两颗六核处理器,48-128GB内存,12 – 16块硬盘(单盘4TB or 6TB) ,直接和主板控制器连接。如果这种节点发生故障,将会导致集群内部数据抖动,产生大量的流量 Storage Heavy Configuration (2U/machine): 两颗六核处理器,48-96GB内存,16-24块硬盘(单盘6TB or 8TB),如果这种节点发生故障,将会导致集群内部数据抖动,产生大量的流量 Compute Intensive Configuration (2U/machine): 两颗六核处理器,64-512GB内存,4-8块硬盘(单盘2TB or 4TB) 注:上面的CPU都是最小配置,建议使用的是 2×8,2×10,2×12 core的处理器配置(不包括超线程)。下图显示在不同维度集群配置的侧重点:
Namenode的内存预估: <Secondary NameNode memory> = <NameNode memory> = <HDFS cluster management memory> + <2GB for the NameNode process> + <4GB for the OS> Datanode的内存预估: 如果是I/O类型的job,每个core分配2~4GB RAM 如果是CPU类型的job,每个core分配6~8GB RAM 除了以上的job消耗内存外,整个机型还需要额外的增加: Datanode进程管理HDFS的block,需要2GB RAM TaskTracker 进程管理节点运行的task,需要2GB RAM OS,需要4GB RAM 下面给出一个计算公式: <DataNode memory for I/O bound profile> = 4GB * <number of physical cores> + <2GB for the DataNode process> + <2GB for the TaskTracker process> + <4GB for the OS> <DataNode memory for CPU bound profile> = 8GB * <number of physical cores> + <2GB for the DataNode process> + <2GB for the TaskTracker process> + <4GB for the OS> 如果新集群你还是无法预估你的最终工作量,我们建议还是使用均衡的硬件配置。
其他注意事项: Hadoop生态系统是一个并行环境的系统,购买处理器时并不建议购买最高GHz的处理器,这样的话电源则会高达150W+,直接导致集群的功率和热量增大,中档配置的机型则会降低主频,配置适当的Core,来达到合适的价格。如果在生产中遇到大量产生中间数据的程序,其他程序顺序的读入这些输出的数据,我们建议网卡使用bond,每个节点提供2 Gbps的网络吞吐量,则每个节点可以存储12T的数据,还有良好的访问效果,一旦你移动的数据达到12T以上,建议提供4 Gbps的网络吞吐量。如果是土豪用户,请使用10 Gigabit Ethernet。 当计算内存需求时,请记住,java最多使用10%的内存来管理jvm虚拟机。建议严格配置Hadoop使用的堆大小限制,以避免内存交换到磁盘,交换会大大影响MapReduce的性能。 附:主流CPU信息
主流硬盘信息(TB级别): 3.5寸NLSAS盘:
3.5寸SATA盘:
注:NLSAS不是纯SAS,更不是SATA。虽然近线SAS和SATA都是盘体马达7200转速,但是近线SAS盘体内部有近SAS总线,对外接口为SATA,而SATA盘的盘内和盘外的接口全部为SATA。 2.5寸NLSAS盘:
2.5寸NLSAS盘(土豪套餐):
(责任编辑:IT) |