|
年前,在老大的号召下,我们纠集了一帮人搞起了hadoop,并为其取了个响亮的口号“云在手,跟我走”。大家几乎从零开始,中途不知遇到多少问题,但终 于在回家之前搭起了一个拥有12台服务器的集群,并用命令行在该集群上运行了一些简单的mapreduce程序。想借此总结我们的工作过程。
安装过程:
一、安装Linux操作系统
二、在Ubuntu下创建hadoop用户组和用户
三、在Ubuntu下安装JDK
四、修改机器名
五、安装ssh服务
六、建立ssh无密码登录本机
七、安装hadoop
八、在单机上运行hadoop
一、安装Linux操作系统
我们是在windows中安装linux系统的,选择的是ubuntu11.10,介于有些朋友是第一次安装双系统,下面我就介绍一种简单的安装方法:
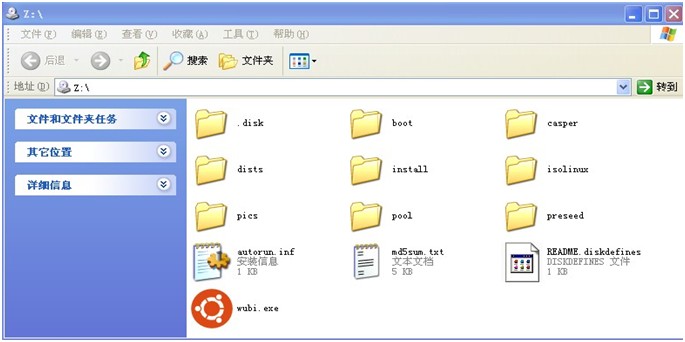
1、下载ubuntu-11.10-desktop-i386.iso镜像文件,用虚拟光驱打开,执行里面的wubi.exe程序,如图(1)
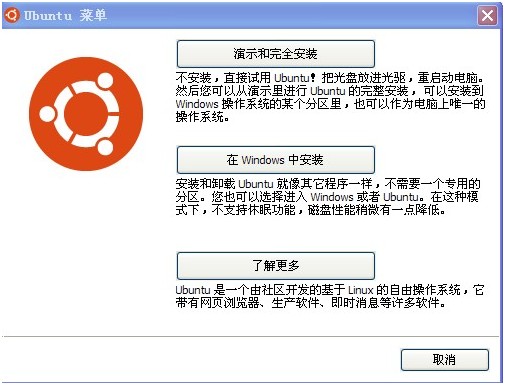
2、选择在widows中安装,如图(2)
3、在弹出的窗口中设置一些具体的参数,自动跟新完成后需要重启。重启时,就会出现ubuntu系统的选择了,系统一般默认开机启动windows系统,所以这里要自己手动选择哦~,进入ubuntu后,系统就自动下载,跟新、安装了。
(注:安装的过程中可能会卡在一个阶段很长时间(我卡了半个小时),这时我选择了强制关机,重启时同样选择进入ubuntu。一般第二次就不会卡,具体原 因我也不是很清楚,可能和wubi.exe程序有关吧。 在网上看到,有些人认为用wubi.exe安装ubuntu不是很好,可能这就是它的不好之处吧。不过这是非常简单的方法,所以我们还是选择这种安装方法 吧。)
二、在Ubuntu下创建hadoop用户组和用户
这里考虑的是以后涉及到hadoop应用时,专门用该用户操作。用户组名和用户名都设为:hadoop。可以理解为该hadoop用户是属于一个名为hadoop的用户组,这是linux操作系统的知识,如果不清楚可以查看linux相关的书籍。
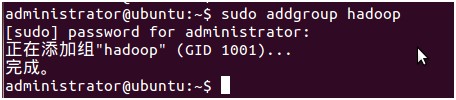
1、创建hadoop用户组,如图(3)
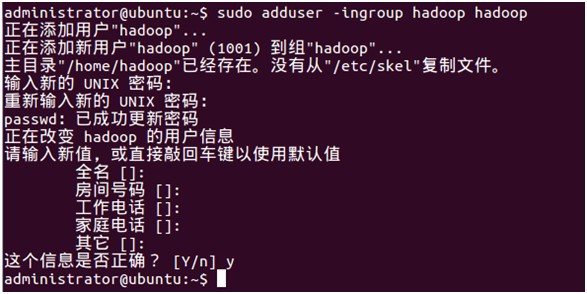
2、创建hadoop用户,如图(4)
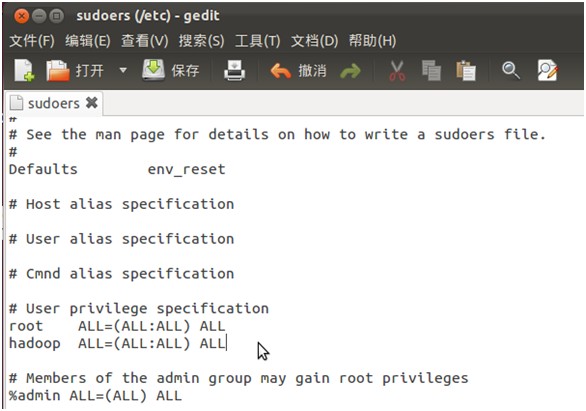
3、给hadoop用户添加权限,打开/etc/sudoers文件,如图(5)

按回车键后就会打开/etc/sudoers文件了,给hadoop用户赋予root用户同样的权限。在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL,如图(6)
三、在Ubuntu下安装JDK(http://weixiaolu.iteye.com/blog/1401786)
四、修改机器名
每当ubuntu安装成功时,我们的机器名都默认为:ubuntu ,但为了以后集群中能够容易分辨各台服务器,需要给每台机器取个不同的名字。机器名由 /etc/hostname文件决定。
1、打开/etc/hostname文件,如图(7)

2、回车后就打开/etc/hostname文件了,将/etc/hostname文件中的ubuntu改为你想取的机器名。这里我取“s15“。重启系统后才会生效。
五、安装ssh服务
这里的ssh和三大框架:spring,struts,hibernate没有什么关系,ssh可以实现远程登录和管理,具体可以参考其他相关资料。
1、安装openssh-server,如图(8)

(注:自动安装openssh-server时,可能会进行不下去,可以先进行如下操作:)

2、更新的快慢取决于您的网速了,如果中途因为时间过长您中断了更新(Ctrl+z),当您再次更新时,会更新不了,报错为:“Ubuntu无法锁定管理目录(/var/lib/dpkg/),是否有其他进程占用它?“需要如下操作,如图(10)

操作完成后继续执行第1步。
这时假设您已经安装好了ssh,您就可以进行第六步了哦~
六、 建立ssh无密码登录本机
ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式。
1、创建ssh-key,,这里我们采用rsa方式,如图(11)

(注:回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的)
2、进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的,如图(12)

(完成后就可以无密码登录本机了。)
3、登录localhost,如图(13)
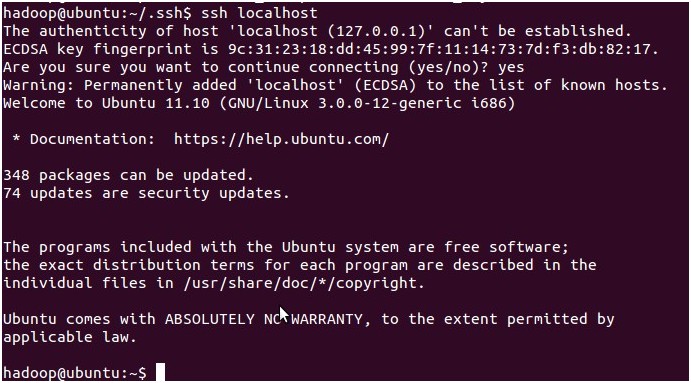
( 注:当ssh远程登录到其它机器后,现在你控制的是远程的机器,需要执行退出命令才能重新控制本地主机。)
4、执行退出命令,如图(14)

七、安装hadoop
我们采用的hadoop版本是:hadoop-0.20.203(http://apache.etoak.com/hadoop/common/hadoop-0.20.203.0/ ),因为该版本比较稳定。
1、假设hadoop-0.20.203.tar.gz在桌面,将它复制到安装目录 /usr/local/下,如图(15)

2、解压hadoop-0.20.203.tar.gz,如图(16)

3、将解压出的文件夹改名为hadoop,如图(17)

4、将该hadoop文件夹的属主用户设为hadoop,如图(18)

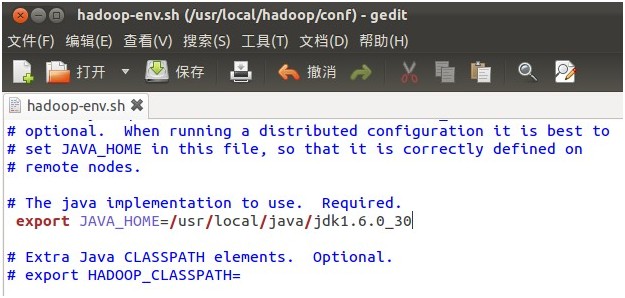
5、打开hadoop/conf/hadoop-env.sh文件,如图(19)

6、配置conf/hadoop-env.sh(找到#export JAVA_HOME=...,去掉#,然后加上本机jdk的路径)
7、打开conf/core-site.xml文件,编辑如下:
Java代码 
-
<?xml version="1.0"?>
-
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
-
-
<!-- Put site-specific property overrides in this file. -->
-
-
<configuration>
-
<property>
-
<name>fs.default.name</name>
-
<value>hdfs://localhost:9000</value>
-
</property>
-
</configuration>
8、打开conf/mapred-site.xml文件,编辑如下:
Java代码
-
<?xml version="1.0"?>
-
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
-
-
<!-- Put site-specific property overrides in this file. -->
-
-
<configuration>
-
<property>
-
<name>mapred.job.tracker</name>
-
<value>localhost:9001</value>
-
</property>
-
</configuration>
9、打开conf/hdfs-site.xml文件,编辑如下:
Java代码
-
<configuration>
-
<property>
-
<name>dfs.name.dir</name>
-
<value>/usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2</value>
-
</property>
-
<property>
-
<name>dfs.data.dir</name>
-
<value>/usr/local/hadoop/data1,/usr/local/hadoop/data2</value>
-
</property>
-
<property>
-
<name>dfs.replication</name>
-
<value>2</value>
-
</property>
-
</configuration>
10、打开conf/masters文件,添加作为secondarynamenode的主机名,作为单机版环境,这里只需填写localhost就Ok了。
11、打开conf/slaves文件,添加作为slave的主机名,一行一个。作为单机版,这里也只需填写localhost就Ok了。
八、在单机上运行hadoop
1、进入hadoop目录下,格式化hdfs文件系统,初次运行hadoop时一定要有该操作,如图(21)

当你看到下图时,就说明你的hdfs文件系统格式化成功了。

3、启动bin/start-all.sh,如图(23)

4、检测hadoop是否启动成功,如图(24)
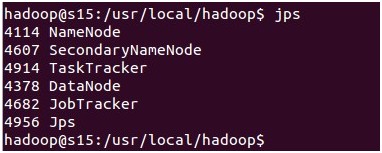
如果有Namenode,SecondaryNameNode,TaskTracker,DataNode,JobTracker五个进程,就说明你的hadoop单机
版环境配置好了,呵呵,多么宏伟的工程呀!
九、 Linux下的快捷键:
Ctrl+Alt+t:弹出终端
Ctrl+空格:中英文输入法切换
十、Hadoop执行WordCount程序
(责任编辑:IT) |