|
经过几天的测试,hadoop分布式系统搭建完毕。首先说一下这几天对hadoop理论知识的理解,然后说一下安装及碰到的问题。有图有真相http://192.168.0.20:50070/dfshealth.jsp
第一:理论知识:
什么是hadoop:
由三部分组成:HDFS,MapReduce和Hbase。
维基百科这样说:一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。这里面关键就是高速运算和海量存储。我们首先讲海量存储,这个比较有意思,一会儿再说高速运算。
海量存储: HDFS<Hadoop Distributed File System>
前身来自google的一篇博文,所以自身带有浓厚的互联网色彩,比如读多于写的特性,高度的扩展性。 具体说一下他的特性:
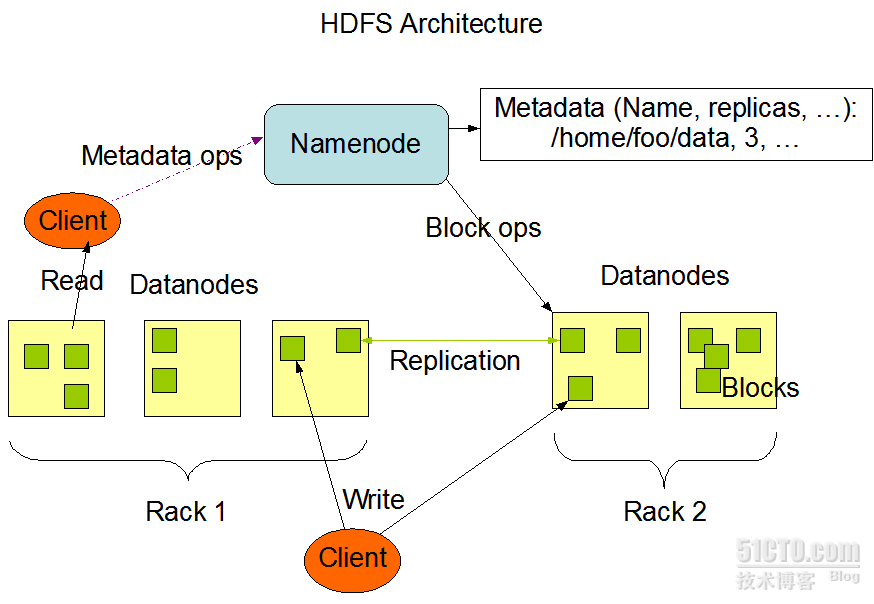
图1:HDFS结构示意图
<抄自 岑文初>
上图中展现了整个HDFS三个重要角色:NameNode、DataNode和Client。NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。Client就是需要获取分布式文件系统文件的应用程序。这里通过三个操作来说明他们之间的交互关系。
文件写入:
文件读取:
文件Block复制:
HDFS的几个设计特点:
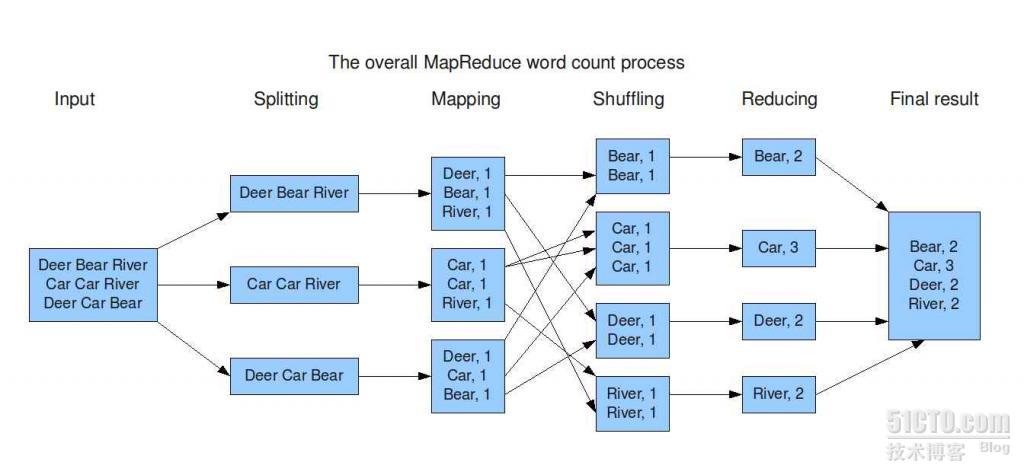
下面说高速计算:
上面的图片是计算这个文件中每个单词出现的次数,这个任务被分裂成三个子任务,然后映射到集群中JobTracker指定的TaskTracker上运行子任务,每个子任务都可以在指定的TaskTracker上运行,然后把运行的结果保存在当地,然后reduce程序被调用。然后进行的是结果的整合,整合完毕,就是最终结果了。这是计算向数据靠拢的计算方式。
好了,我们开始说安装,好多都在讲0.17和0.18的安装,hadoop这玩意儿因为最近很火,所以变动很厉害,变动的速度估计和nginx有一拼,所以在安装的时候得批判的继承他们安装过程。
环境:
首先:在这几台机器上安装CentOS5.4(最简化安装)并升级完毕。
保证计算机名的全局唯一性:
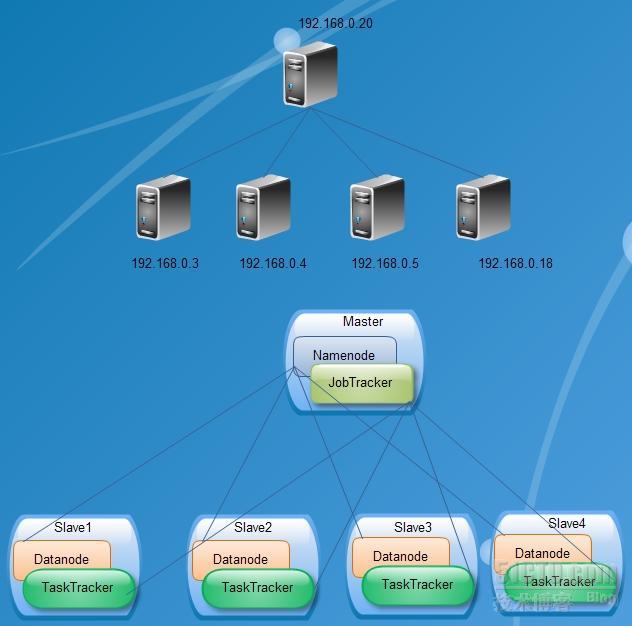
hadoop1.diarc.com.cn-----192.168.0.3
hadoop2.diarc.com.cn-----192.168.0.4
hadoop3.diarc.com.cn-----192.168.0.5
hadoop4.diarc.com.cn-----192.168.0.18
hadoop5.diarc.com.cn-----192.168.0.20
修改方式:(5台服务器都设置)
[root@hadoop5 ~]# hostname hadoop5.diarc.com.cn
[root@hadoop5 ~]# cat /etc/hosts # Do not remove the following line, or various programs # that require network functionality will fail. 127.0.0.1 localhost.localdomain localhost ::1 localhost6.localdomain6 localhost6 192.168.0.20 hadoop5.diarc.com.cn hadoop5
[root@hadoop5 ~]# cat /etc/sysconfig/network
NETWORKING=yes NETWORKING_IPV6=no HOSTNAME=hadoop5.diarc.com.cn GATEWAY=192.168.0.1 [root@hadoop5 ~]# 为了方便,关闭防火墙:(5台服务器都设置)
[root@hadoop5 ~]# service iptables stop
[root@hadoop5 ~]# chkconfig iptables off
方便起见,创建hadoop用户
[root@hadoop5 ~]# useradd hadoop
下载hadoop最新版:http://apache.freelamp.com/hadoop/core/hadoop-0.20.2/hadoop-0.20.2.tar.gz
下载JDK最新版:http://cds-esd.sun.com/ESD6/JSCDL/jdk/6u19-b04/jdk-6u19-linux-i586-rpm.bin?AuthParam=1270716768_db3a41353e2febaf6e98b124c7e4a54d&TicketId=B%2Fw6lhWJS1NMThBDO15fkQPk&GroupName=CDS&FilePath=/ESD6/JSCDL/jdk/6u19-b04/jdk-6u19-linux-i586-rpm.bin&File=jdk-6u19-linux-i586-rpm.bin
全部放入/home/hadoop目录。
[root@hadoop5 ~]# cp jdk-6u19-linux-i586.bin /usr/local/
[root@hadoop5 ~]# cd /usr/local/
[root@hadoop5 ~]# ./jdk-6u19-linux-i586.bin [root@hadoop5 ~]# rm -rf jdk-6u19-linux-i586.bin [root@hadoop5 ~]# cd /home/hadoop/
[root@hadoop5 hadoop]# tar zxvf hadoop-0.20.2.tar.gz
[root@hadoop5 ~]# cat /etc/profile ##放入如下信息 export JAVA_HOME=/usr/local/jdk1.6.0_19 export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin:$PATH
export HADOOP_HOME=/home/hadoop/hadoop-0.20.2
export PATH=$PATH:$HADOOP_HOME/bin
然后执行如下命令:
[root@hadoop5 ~]# source /etc/profile
现在我们修改hadoop的配置文件:0.20以上的配置和以前的配置有些是不同的,我们以0.20.2为例做东西
[root@hadoop5 conf]# cat core-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property> <name>fs.default.name</name> <value>hdfs://192.168.0.20:54310/</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/tmp/</value> </property> </configuration>
===========================================================================
[root@hadoop5 conf]# echo "export JAVA_HOME=/usr/local/jdk1.6.0_19" >> hadoop-env.sh ===========================================================================
[root@hadoop5 conf]# cat hdfs-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property> <name>dfs.replication</name> <value>3</value> </property> </configuration> ===========================================================================
[root@hadoop5 conf]# cat mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property> <name>mapred.job.tracker</name> <value>hdfs://192.168.0.20:54311/</value> </property>
</configuration>
[root@hadoop5 conf]# =========================================================================== [root@hadoop5 conf]# cat masters 192.168.0.20 [root@hadoop5 conf]# cat slaves 192.168.0.3 192.168.0.4 192.168.0.5 192.168.0.18 [root@hadoop5 conf]# ==========================================================================
现在我们做无密码的ssh登录:
建立Master到每一台Slave的SSH受信证书。由于Master将会通过SSH启动所有Slave的Hadoop,所以需要建立单向或者双向证书保证命令执行时不需要再输入密码。在Master和所有的Slave机器上执行:ssh-keygen -t rsa。执行此命令的时候,看到提示只需要回车。然后就会在/root/.ssh/下面产生id_rsa.pub的证书文件,通过scp将Master机器上的这个文件拷贝到Slave上(记得修改名称),例如:scp root@masterIP:/root/.ssh/id_rsa.pub /root/.ssh/46_rsa.pub,然后执行cat /root/.ssh/46_rsa.pub >>/root/.ssh/authorized_keys,建立authorized_keys文件即可,可以打开这个文件看看,也就是rsa的公钥作为key,user@IP作为value。此时可以试验一下,从master ssh到slave已经不需要密码了。由slave反向建立也是同样。为什么要反向呢?其实如果一直都是Master启动和关闭的话那么没有必要建立反向,只是如果想在Slave也可以关闭Hadoop就需要建立反向。
然后每台服务器上都修改ssh的配置文件:/etc/ssh/sshd_config 把GSSAPIAuthentication的值设置为no,然后:
[root@hadoop5 conf]# service sshd restart
[root@hadoop5 conf]# 我们从master向slave依次登录
[root@hadoop5 conf]#ssh root@192.168.0.3
[root@hadoop5 conf]#ssh root@192.168.0.4
[root@hadoop5 conf]#ssh root@192.168.0.5
[root@hadoop5 conf]#ssh root@192.168.0.18
然后压缩hadoop文件夹成为一个压缩包
[root@hadoop5 hadoop]# tar zcvf hadoop-0.20.2.tar.gz hadoop-0.20.2
然后在每台slave上执行如下命令
[root@hadoop1 hadoop]# cd /home/hadoop
[root@hadoop1 hadoop]# scp -r root@192.168.0.20:/home/hadoop/hadoop-0.20.2.tar.gz /home/hadoop/ [root@hadoop1 hadoop]# tar zxvf hadoop-0.20.2.tar.gz
好,我们现在可以在master上执行如下命令:
[root@hadoop5 hadoop]# hadoop namenode -format
[root@hadoop5 hadoop]# cd /home/hadoop/hadoop-0.20.2/bin/ [root@hadoop5 bin]# ./start-all.sh
然后在地址栏输入:http://192.168.0.20:50070可以查看master和slave的状态。
手写的有点木,不多写了
参考文献:
Hadoop官方文档:http://hadoop.apache.org/common/docs/r0.18.2/cn/index.html(读晕拉倒)
百度百科:http://baike.baidu.com/view/908354.htm
(责任编辑:IT) |