|
虽然和GOOGLE的云计算框架相差很远,但是基本能够实现云框架还是可以的,我选择了hadoop,最近这个框架在网络上炒的很火,一部分IT高手加入了开发队列,本人也不例外(不过我不是高手,只是一个很普通的系统架构师而已)。
好了废话少说,直接切入主题吧
首先使用了五台机器来实现hadoop框架。
IP依次为:
192.168.1.199(master)
192.168.1.200(slave)
192.168.1.201(slave)
192.168.1.202(slave)
192.168.1.203(slave)
以下是简单结构:
首先登录119服务器
[root@localhost ~]# uname -ar
Linux localhost 2.6.18-92.el5 #1 SMP Tue Jun 10 18:49:47 EDT 2008 i686 i686 i386 GNU/Linux
保证计算机名的全局唯一性:
hadoop1. test.com -----192.168.1.203
hadoop2. test.com -----192.168.1.202
hadoop3. test.com -----192.168.1.201
hadoop4. test.com -----192.168.1.200
hadoop5. test.com -----192.168.1.199
设置hostname
Hostname hadoop5.test.com
[root@localhost ~]# vi /etc/hosts
127.0.0.1 localhost.localdomain localhos
192.168.1.199 hadoop5.test.com
[root@localhost ~]# uname -ar
Linux hadoop5.test.com 2.6.18-92.el5 #1 SMP Tue Jun 10 18:49:47 EDT 2008 i686 i686 i386 GNU/Linux
[root@localhost ~]# vi /etc/sysconfig/network
NETWORKING=yes
NETWORKING_IPV6=no
#HOSTNAME=localhost.localdomain
HOSTNAME=hadoop5.test.com
GATEWAY=192.168.1.254
OK了,已经修改过来了,其他机器也同样的设置。
为了方便,关闭防火墙:(5台服务器都设置)
[root@hadoop5 ~]# service iptables stop
[root@hadoop5 ~]# chkconfig iptables off
方便起见,创建hadoop用户
[root@hadoop5 ~]# useradd hadoop
下载hadoop最新 版:http://apache.freelamp.com/hadoop/core/hadoop-0.20.2/hadoop-0.20.2.tar.gz
下载JDK最新版:
http://cds.sun.com/is-bin/INTERSHOP.enfinity/WFS/CDS-CDS_Developer-Site/en_US/-/USD/VerifyItem-Start/jdk-6u19-linux-i586.bin?BundledLineItemUUID=YTBIBe.nt_gAAAEnpTtSWvsx&OrderID=Ga5IBe.n.w4AAAEnmjtSWvsx&ProductID=8ihIBe.nLjEAAAEnh3cZVnKo&FileName=/jdk-6u19-linux-i586.bin
全部放入/home/hadoop目录。
[root@localhost local]# cp jdk-6u19-linux-i586.bin /usr/local/
[root@localhost local]# cd /usr/local/
[root@localhost local]# chmod +x ./jdk-6u19-linux-i586.bin
[root@localhost local]#./jdk-6u19-linux-i586.bin #执行
一直按回车即可,然后输入yes回车。
[root@localhost local]# rm -rf jdk-6u19-linux-i586.bin
[root@localhost local]# cd /home/hadoop/
[root@localhost hadoop]# vi /etc/profile
在最下面加入:
export JAVA_HOME=/usr/local/jdk1.6.0_19
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin:$PATH
export HADOOP_HOME=/home/hadoop/hadoop-0.20.2
export PATH=$PATH:$HADOOP_HOME/bin
[root@localhost hadoop]# source /etc/profile
现在我们修改hadoop的配置文件:0.20以上的配置和以前的配置有些是不同的,我们 以0.20.2为例做东西
[root@localhost conf]# pwd
/home/hadoop/hadoop-0.20.2/conf
[root@localhost conf]# vi core-site.xml
[root@localhost conf]# echo "export JAVA_HOME=/usr/local/jdk1.6.0_19" >> hadoop-env.sh
[root@localhost conf]# vi hdfs-site.xml
[root@localhost conf]# vi mapred-site.xml
添加slave地址 vim /home/hadoop/hadoop-0.20.2/conf/slaves 我的内容是: 192.168.1.200 192.168.1.201 192.168.1.202 192.168.1.203 也可以用一下方法添加
[root@localhost conf]# echo 192.168.1.199 > masters
[root@localhost conf]# echo 192.168.1.200 > slaves
[root@localhost conf]# echo 192.168.1.201 >> slaves
[root@localhost conf]# echo 192.168.1.202 >> slaves
[root@localhost conf]# echo 192.168.1.203 >> slaves
现在我们做无密码的ssh登录的设置:
建立Master到每一台Slave的SSH受信证书。由于Master将会通过SSH启动所有Slave的 Hadoop,所以需要建立单向或者双向证书保证命令执行时不需要再输入密码。在Master和所有的Slave机器上执行:ssh-keygen -t rsa。
执行此命令的时候,看到提示只需要回车。然 后就会在/root/.ssh/下面产生id_rsa.pub的证书文件,通过scp将Master机器上的这个文件拷贝 到Slave上(记得修改名称),例如:
Scp root/.ssh/id_rsa.pub root@192.168.1.200:/root/.ssh/authorized_keys
,建立authorized_keys文件即可,可以打开这个文件看看,也就是rsa的公 钥作为key,user@IP作为value。此时可以试验一下,从master ssh到slave已经不需要密码了。由slave反向建立也是同样。为什么要反向呢?其实如果一直都是Master启动和关闭的话那么没有必要建立反 向,只是如果想在Slave也可以关闭Hadoop就需要建立反向。
[root@localhost .ssh]# scp /root/.ssh/id_rsa.pub root@192.168.1.200:/root/.ssh/authorized_keys
root@192.168.1.200's password:
id_rsa.pub 100% 403 0.4KB/s 00:00
[root@localhost .ssh]# scp /root/.ssh/id_rsa.pub root@192.168.1.201:/root/.ssh/authorized_keys
root@192.168.1.201's password:
id_rsa.pub 100% 403 0.4KB/s 00:00
[root@localhost .ssh]# scp /root/.ssh/id_rsa.pub root@192.168.1.202:/root/.ssh/uthorized_keysroot@192.168.1.202's password:
id_rsa.pub 100% 403 0.4KB/s 00:00
[root@localhost .ssh]# scp /root/.ssh/id_rsa.pub root@192.168.1.203:/root/.ssh/authorized_keys
root@192.168.1.203's password:
id_rsa.pub 100% 403 0.4KB/s 00:00
然后重启SSHD服务
[root@localhost .ssh]# service sshd restart
Stopping sshd: [ OK ]
Starting sshd: [ OK ]
然后每台服务器上都修改ssh的配置文件:/etc/ssh/sshd_config 把GSSAPIAuthentication的值设置为no
这样起到加速的作用,具体含义,自己看下ssh手册。
然后压缩hadoop文件夹成为一个压缩包
[root@localhost hadoop]# cd /home/hadoop/
[root@localhost hadoop]# tar zcvf hadoop-0.20.2.tar.gz hadoop-0.20.2
依次传送到slave服务器上
[root@localhost hadoop]# scp hadoop-0.20.2.tar.gz root@192.168.1.200:/home/hadoop
hadoop-0.20.2.tar.gz 100% 43MB 21.3MB/s 00:02
[root@localhost hadoop]# scp hadoop-0.20.2.tar.gz root@192.168.1.201:/home/hadoop
hadoop-0.20.2.tar.gz 100% 43MB 14.2MB/s 00:03
[root@localhost hadoop]# scp hadoop-0.20.2.tar.gz root@192.168.1.203:/home/hadoop
hadoop-0.20.2.tar.gz 100% 43MB 21.3MB/s 00:02
[root@localhost hadoop]# scp hadoop-0.20.2.tar.gz root@192.168.1.202:/home/hadoop
hadoop-0.20.2.tar.gz
然后依次登录slave服务器并解压hadoop文件
tar zxvf hadoop-0.20.2.tar.gz
好,我们现在可以在master上执行如下命令:
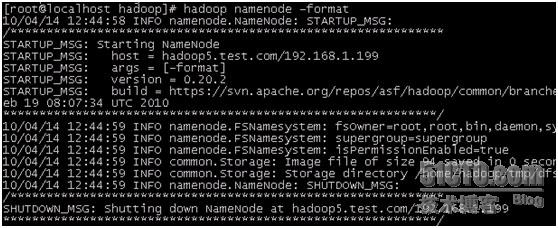
[root@localhost hadoop]# cd /home/hadoop/hadoop-0.20.2/bin/
报了一堆错误
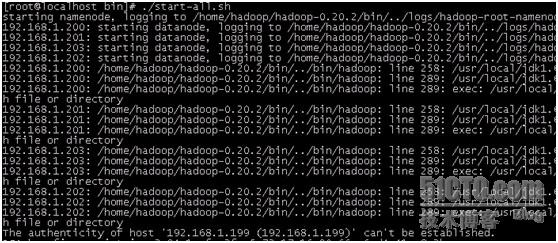
总之意思就是说没有jdk,后来仔细想想 ,确实忘记在slave上安装jdk了。
然后按照master上安装jdk的步骤依次在slave上重复一次。
所有机器都安装完JDK之后,继续到199主服务器上执行
[root@localhost bin]# ./start-all.sh

所有服务器执行成功.
然后可以在浏览器上输入http://192.168.1.199:50070/dfshealth.jsp
查看master/slave的服务状态了。
不过有一点要注意一下,iptables可能限定了某些端口,所有方便起见,还是要关闭master/slave服务器上的iptables的。
剩下就是开发事宜,我们下次再讲,希望解占辉的文章对您有帮助,谢谢!
参考文献:
http://doc.chinaunix.net/linux/200911/189633.shtml
(责任编辑:IT) |