 [Hadoop] 谈Hadoop的C++扩展 日期:2015-01-20 00:17:06 点击:74 好评:0
[Hadoop] 谈Hadoop的C++扩展 日期:2015-01-20 00:17:06 点击:74 好评:0
原文在http://blog.sina.com.cn/s/blog_6e273ebb0100pid0.html 长期一来,Hadoop因为其Java实现带来的性能问题而饱受争议,同时也涌现了很多方案来缓解这一问题。 Jeff Hammerbacher(Cloudera首席科学家)曾在Quora上写过这样一段: ----------------------...
[Hadoop] Hadoop C++ Pipes中context常见成员函数的作用 日期:2015-01-20 00:16:23 点击:101 好评:0
getJobConf Get the JobConf for the current task getInputKey Get the current key getInputValue Get the current value In the reducer, context.getInputValue is not available till context.nextValue is called ! progress This method simply phone...
[Hadoop] 面向MapReduce 的数据处理流程开发方法 ------------重点内容摘要 日期:2015-01-20 00:15:40 点击:59 好评:0
摘 要:数据处理流程在信息爆炸的今天被广泛应用并呈现出海量和并行的特点, MapReduce 编程模型的简单性和高性价比使得其适用于海量数据的并行处理, 但是 MapReduce 不支持多数据源的数据处理, 不能直接应用于具有多个处理操作、多个数据流分支的数据处理流...
[Hadoop] 在Redhat AS6上搭建Hadoop集群总结 日期:2015-01-20 00:15:14 点击:131 好评:0
本周末在家里的两台电脑上用Vmware+Redhat As6 + hadoop-0.21.0上搭建了一个3节点的Hadoop集群,虽说是原来已经搭建过类似的集群了,也跑过JavaAPI来操作HDFS与Map/reduce,但是这一次依然是受到挑战了,好些小细节,稍有遗漏就会有如坐过山车一般大起大落。...
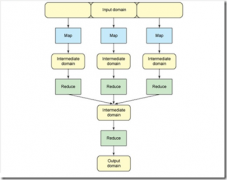 [Hadoop] Map-Reduce简介 日期:2015-01-20 00:14:25 点击:51 好评:0
[Hadoop] Map-Reduce简介 日期:2015-01-20 00:14:25 点击:51 好评:0
MapReduce是一种编程模型,始于:Dean, Jeffrey Ghemawat, Sanjay (2004). MapReduce: Simplified Data Processing on Large Clusters。主要应用于大规模数据集的并行运算。其将并行计算简化为Map和reduce过程,极大地方便了编程人员在不会分布式并行编程的...
 [Hadoop] Hadoop MapReduce 日期:2015-01-20 00:14:15 点击:159 好评:0
[Hadoop] Hadoop MapReduce 日期:2015-01-20 00:14:15 点击:159 好评:0
mapreducehadoop分布式计算任务分布式存储程序开发 Hadoop MapReduce是一个用于处理海量数据的分布式计算框架。这个框架解决了诸如数据分布式存储、作业调度、容错、机器间通信等复杂问题,可以使没有并行处理或者分布式计算经验的工程师,也能很轻松地写出...
[Hadoop] Hadoop Streaming 日期:2015-01-20 00:13:12 点击:139 好评:0
Hadoop MapReduce和HDFS采用Java实现,默认提供Java编程接口,另外提供了C++编程接口和Streaming框架。Streaming框架允许 任何程序语言 实现的程序在Hadoop MapReduce中使用,方便已有程序向Hadoop平台移植。 Streaming的原理 是用Java实现一个包装用户程序...
[Hadoop] Hadoop客户端环境配置 日期:2015-01-20 00:12:51 点击:199 好评:0
1. 安装客户端(通过端用户可以方便的和集群交互) 2. 修改客户端~/.bashrc alias hadoop=/home/work/hadoop/client/hadoop-client/hadoop/bin/hadoop #hadoop 可执行文件位置 alias hls=hadoop fs -ls alias hlsr=hadoop fs -lsr alias hcp=hadoop fs -cp a...
[Hadoop] Hadoop Streaming 实战: grep 日期:2015-01-20 00:12:28 点击:69 好评:-2
streaming支持shell 命令的使用。但是,需要注意的是,对于多个命令,不能使用形如cat; grep 之类的多命令,而需要使用脚本,后面将具体介绍。 下面示例用grep检索巨量数据: 1. 待检索的数据放入hdfs $ hadoop fs -put localfile /user/hadoop/hadoopfile...
[Hadoop] Hadoop Streaming 实战: bash脚本 日期:2015-01-20 00:12:00 点击:62 好评:0
streaming支持使用脚本作为map、reduce程序。以下介绍一个实现分布式的计算所有文件的总行数的程序 1. 待检索的数据放入hdfs $ hadoop fs -put localfile /user/hadoop/hadoopfile 2. 编写map、reduce脚本,记得给脚本加可执行权限。 mapper.sh view plain #!...
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个...
一、 Apache、Tomcat集群和负载均衡所需资源软件(附下载地址): a) apache_2.0.55-win...
不对的地方,欢迎大家拍砖。 现在有如下三台服务器: 10.57.22.201(做负载均衡配制)(...
一、试验拓扑 二、环境描述 负载均衡器: eth0 192.168.152.139 VIP : 192.168.152.2...