|
作者介绍
杨建荣,竞技世界资深DBA,前搜狐畅游数据库专家,Oracle ACE,YEP成员。拥有近十年数据库开发和运维经验,目前专注于开源技术、运维自动化和性能调优。拥有Oracle 10g OCP、OCM、MySQL OCP认证,对Shell、Java有一定功底。每天通过微信、 博客进行技术分享,已连续坚持1800多天。
SQL审核,在业界已经被认同了,实际上也是对SQL的标准化管理;而人工审核时代,针对数据库规范其实是很难落地的,规范越多,DBA越累,开发也越累,所以我们在SQL审核的基础上,提出了自助的概念,本身也是希望提高DBA工作的幸福度,同样让开发同学也觉得有帮助。
一、SQL审核的意义
我们先来说下SQL审核的意义。要回答这个问题,就需要先解答下为什么要引入SQL审核:
SQL审核设计背景和方案
所以行业里也存在一些审核工具,比如Inception、SQL Advisor等。我们在此不着重介绍这些审核工具的细节,而是基于业务的场景来考虑。
二、SQL审核的核心
对于SQL审核来说,我认为要它的核心是:
在此基础上,审核的难点更多是需要基于公司规范定制审核规则。有很多不同的工具、方案可供选择,如何把基于自己特定业务的规范揉入进来?这是一个值得深思的问题。
整体来说,要做好SQL审核不是把软件安装好用就可以了,还需要做一些对比测试和分析,如果可以在这个基础上做一些补充和改进,那是极好的。
理解了我所强调的核心,边界问题就相对清晰了,所以SQL审核这件事情,其实说简单也可以很简单,要说复杂,体系也可以很庞大。
三、SQL审核的维度
一般来说,审核会覆盖几个维度:DDL、DML、DQL,它们之间的关系如下:
所以我认为在初期要落地SQL规范,建议是先从DDL方向入手,也就是通泛的create语句和alter语句,而相对来说create需求更为基础。
四、SQL审核的亮点
整个SQL审核的设计,本质是基于规范来完成,而作为一个工具或者产品,它一定有一些深耕的特性或者可以拿得出手的地方。大体来说,会有如下的四个亮点,也是在迭代开放的过程中初步沉淀下来的:
SQL规范定制
规范公司有,行业里也有,把两者有效的结合起来才是能够落地的规范。
对于审核信息的分级,简单来解释下:
一条SQL语句,通过审核工具可以给出多条建议,比如有20条建议,这些建议如果直接抛给业务同学,很可能会被忽略。一般业务同学都会叫苦,说历史遗留问题、项目周期、变更影响范围,所以对于业务同学来说,我们可以根据优先级来给出建议,弄清哪些是必须遵守的,哪些是有潜在问题,哪些是建议改进的,而其中必须遵守的建议应该是最基础的规范,也是需要督促业务同学修正的。
SQL质量可视化
这也是对于审核的一种辅助方式,我们给出了5条,10条,20条建议,这些建议意味着什么,其实可以使用可视化的方式来对接。
在此,通过打分系统来把SQL质量数字化,通过看板的方式把审核质量可视化:比如一条SQL的质量打分是70分,对于业务同学来说,这个和给出的建议个数相比是更加直观的印象,当然为了稳定业务同学的情绪,我们设置了最低分数为50分,这样就不会出现太尴尬的情况。
SQL质量跟踪
这方面是我们的审核工具后续迭代完善的,在使用的过程中,我们应该尽可能保留审核的明细信息,在后续对这些建议进行跟进和完善,这是一种反馈式的互动。
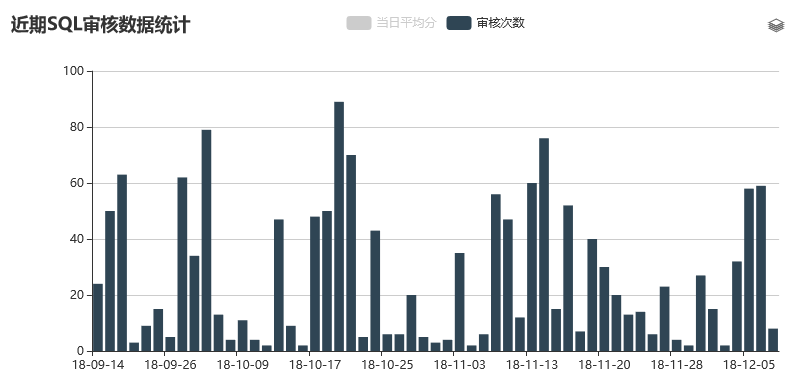
需要再次强调下数字可视化的效果,如果把数字可视化,其实可以看到很多有趣的信息,比如通过这种方式可以看到在一段时间里SQL审核的次数、每天审核的SQL质量,通过平均分来做统计分析;甚至能够看到大家更习惯在哪个时间段做SQL审核。这样对于我们后续做更新升级就会提供很好的数据参考,也对工具整体的落地方向有一个整体的把控。
说完审核的一些亮点,我们来看一些数据,以下是采集了真实需求的一个数据情况,可以看到多的时候每天有近百次的审核请求,而这些请求如果通过人工来做,是很占用碎片时间的。
五、怎么设计SQL审核的流程
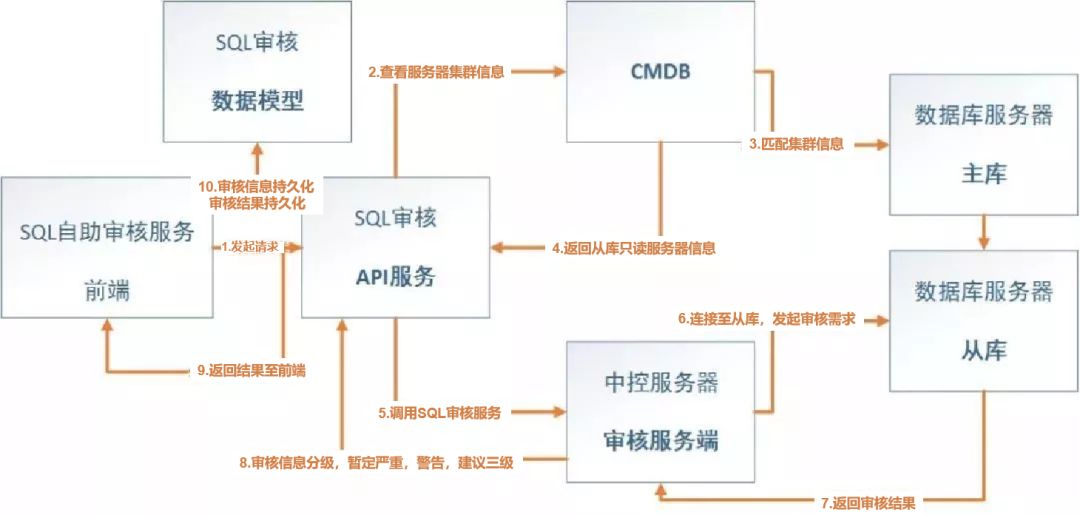
在这张图中,我特意标记了序号,可以看到一个SQL审核的需求从发起到最后返回,整个过程可能比我描述的还要多,我列出几个重要步骤来:
首先是前端,审核的需求从哪里发起?期望是有一个通用的入口。那么在没有建设完善前,那应该有一个迭代的过程,首先要具备基本的SQL审核调用服务。而对于前端的建议就是我们需要找一个通用入口,保证要方便调用和测试使用,最终的业务目标就是把它打造成一个小巧的工具,是提供给开发的自助服务小工具。
如果要涉及到外部系统,那么显然我们要封装API了。这个API有两个难点,我们要解析传送的SQL和其他属性信息,另外一个就是API层来对接后端的服务和结果回调。
这里需要提一下,就是图中的步骤3,我们要充分利用已有的元数据,如果需要做业务数据验证,比如输入了主库的IP,我们需要根据元数据映射关系来匹配到从库,完成审核任务,语法语义审核在从库端,至于后续要做的自动化上线,则逻辑需要定制改动。
整个SQL审核服务怎么部署,我们可以在一台中控服务器端部署一次即可,然后在各个数据库服务器上创建相应的账户即可。至于权限,在审核层面,我们只需要开放select权限即可。
在经过审核服务的审核之后,会推送审核结果到API服务端,这个过程是审核服务的核心,这个核心的意思是我们要从逻辑上完全可控,这可以分为两个层面的工作:
这个过程看起来已经比较完整了,但其实我们只走完了审核工作的70%的工作。
为什么这么说,其实如果我们不够重视,会很吃亏,如果一个开发经验不够丰富,那么它提交的SQL肯定会有很大数量的建议。我们测试的情况,有的SQL语句会有高达40条审核建议,如果一个人对于审核服务还比较陌生的话,从他第一次接触就基本会放弃,工具不好用,建议和规范就难以落实。
那么怎样才能够尽可能落实呢?
其实我们可以想想,一下子给我几十条建议,任何人开始都吃不消。建议这么多,有没有优先级呢?我大致分了三类:
这些信息怎么来映射,其实就和审核服务里的提示信息是密切关联起来的,审核服务里面有个error_code,我们可以根据这个error_code来分级,然后把信息都归类到不同的类别里面,根据优先度来显示出来。
所以我们对这些信息做了配置化操作:
后期要做的而就是我们可以根据审核的建议信息,把这个调用信息做到持久化,包括SQL,包括审核建议,然后一定的时间范围内做下对比和跟进,看看哪些建议还不够好,哪些可以继续改进。
在这个基础上,就可以考虑邮件甚至其他更好的方式了。我们可以做一些数据分析或者反馈,通过比较友好的方式推送出去,或者做成打分系统,让这个过程更透明。
打分系统的使用对于业务来说更加友好,目前对于打分部分的设计有以下几个要点,供参考:
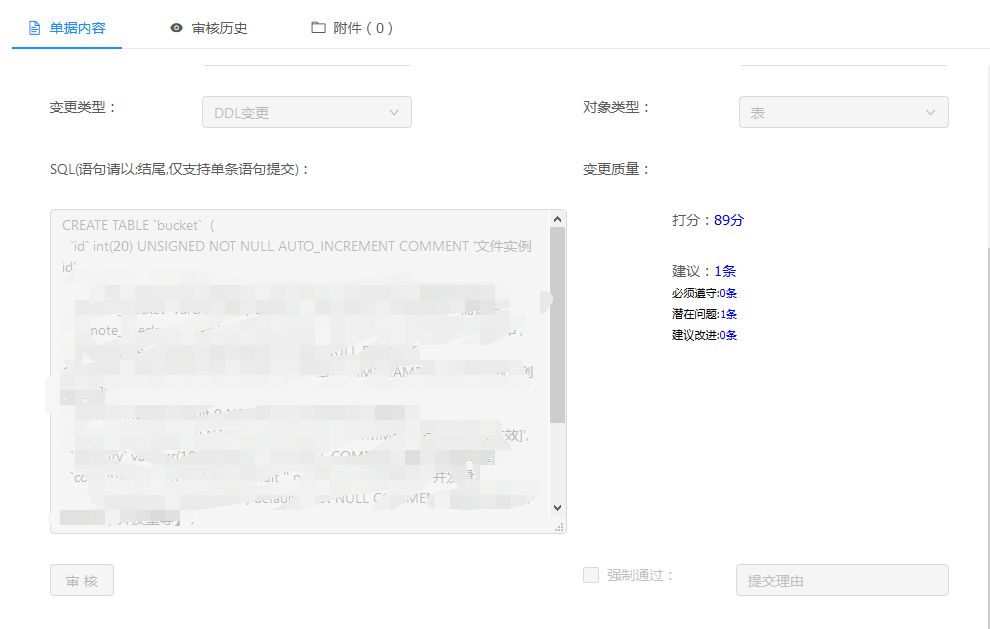
我们看一个基本的小例子,可以看到给了4个建议,其中一个建议是比较重要的,另外的改进建议则可以根据实际情况来考虑:
六、落地SQL审核的正确姿势
要落地SQL审核,只靠我们的热情是不够的,还需要流程的接入。我们开放了自助审核的入口,但是使用效果还是有限,怎么把价值发挥出来呢?
我们需要对审核工具转正,把它纳入到正式的业务流程中。所以我们后续接入了工单系统,如果业务提交的变更打分不到60分,就无法正常提交单据,如果不规范还要强制提交,这些信息会在审批时明确标识出来。
从目前来看,我们就不用可以关注审核工具的使用情况了,我们需要更关注的是审核工具本身的健壮性。
七、SQL审核的质量跟踪
SQL质量的后续跟踪是我们一直在做的事情,在逐步推行的过程中也看到了一些明显的效果,对于业务同学来说,他通过审核熟悉了规范,同时也提高了SQL开发经验,对我们都是双赢。
我们后端会记录下审核的建议信息,以下的结果是我们希望看到的,可以看到随着时间的变化,SQL质量有了很大的提升:
八、SQL审核的后续规划
后续如果继续落地SQL规范,基本有下面的一些思路:
换句话来说,SQL审核的终极目标是没有审核,一个对标方向就是SQL自动化上线,初期来看实现会有难度,但是从源头上把问题解决掉,整个局面就打开了。
所以要达成一个目标,发现很多事情不是一蹴而就,一个核心思想就是迭代。简而言之,迭代的目标有两个主要的结果,一个是从0到1,另外一个是从1到99。对于很多系统建设来说,大家不要总是聊“后期如何如何”,先说有没有。
对于SQL审核也是如此,行业里有很多不错的审核方案,对于大多数同学来说,就没有必要完全从头开始弄一个了,要充分拥抱开源红利,在此也感谢那些默默奉献的开源爱好者,是你们的奉献让我们的生活美好。 |