 [Hadoop] 构建Hadoop集群实验 日期:2019-07-27 14:22:18 点击:121 好评:0
[Hadoop] 构建Hadoop集群实验 日期:2019-07-27 14:22:18 点击:121 好评:0
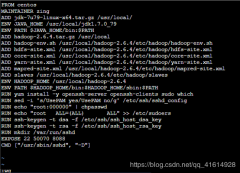
(1)通过实训平台进入到操作系统界面,在#后输入mkdir ssh命令,创建一个ssh文件夹,然后在#后输入cd ssh命令,进入ssh文件夹中。示例代码如下: [root@it~]# mkdir ssh [root@it~]# cd ssh (2)在#后输入vi Dockerfile命令,创建并编辑一个Dockerfile文件...
 [Hadoop] 使用Apache Ambari管理Hadoop集群 日期:2019-07-27 14:09:18 点击:125 好评:0
[Hadoop] 使用Apache Ambari管理Hadoop集群 日期:2019-07-27 14:09:18 点击:125 好评:0
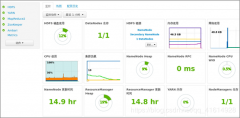
1. 服务管理 (1)登录到实训系统,接着登录到安装好的ambari平台(用户名:密码admin:admin),ambari大数据平台首页。如图1所示: (2)服务信息,在页面左侧的服务列表中,可以选中任何一个想要操作的服务。以 HDFS为例,单击左侧服务列表中的HDFS按钮后...
 [Hadoop] 使用Ambari安装Hadoop集群 日期:2019-07-27 14:07:36 点击:110 好评:0
[Hadoop] 使用Ambari安装Hadoop集群 日期:2019-07-27 14:07:36 点击:110 好评:0
声明:此次安装使用版本为Linux6.6,ambari文件ambari-1.7.0-centos6.tar.gz,HDP文件HDP-2.2.0.0-centos6-rpm.tar.gz,HDP-UTILS文件HDP-UTILS-1.1.0.20-centos6.tar.gz 关于Hadoop的一些组件需要用到的传统型数据库:MySQL,Derby,PostgerSQL。在Ambari安装...
[Hadoop] hadoop + spark+ hive 集群搭建(apache版本) 日期:2018-10-24 15:53:24 点击:66 好评:0
2018-09-11 17:49:27 0. 引言 hadoop 集群,初学者顺利将它搭起来,肯定要经过很多的坑。经过一个星期的折腾,我总算将集群正常跑起来了,所以,想将集群搭建的过程整理记录,分享出来,让大家作一个参考。 由于搭建过程比较漫长,所以,这篇文章应该也会很...
[Hadoop] Hadoop的HA环境搭建 日期:2018-10-24 15:28:49 点击:144 好评:0
一、集群的规划 Zookeeper集群: 192.168.176.131 (bigdata112) 192.168.176.132 (bigdata113) 192.168.176.135 (bigdata114) Hadoop集群: 192.168.176.131 (bigdata112) NameNode1 ResourceManager1 Journalnode 192.168.176.132 (bigdata113) N...
[Hadoop] 伪Hadoop伪分布式集群搭建 日期:2018-04-27 14:43:35 点击:54 好评:0
Hadoop伪分布式 一、准备工作 1、关闭防火墙 service iptables start 立即开启防火墙,但是重启后失效。 service iptables stop 立即关闭防火墙,但是重启后失效。 如下命令是永久性操作,重启后生效。 chkconfig iptables on 开启防火墙,重启后生效。 chkc...
[Hadoop] Hadoop完全分布式配置 日期:2018-04-27 14:41:04 点击:97 好评:0
Hadoop完全分布式配置 一、 介绍 Hadoop2.0中,2个NameNode的数据其实是实时共享的。新HDFS采用了一种共享机制,Quorum Journal Node(JournalNode)集群或者Nnetwork File System(NFS)进行共享。NFS是操作系统层面的,JournalNode是hadoop层面的,我们这...
 [Hadoop] Hadoop 集群安装与配置 日期:2017-07-21 20:45:29 点击:55 好评:0
[Hadoop] Hadoop 集群安装与配置 日期:2017-07-21 20:45:29 点击:55 好评:0
1 Hadoop 是什么? Apache Hadoop 是一个支持数据密集型分布式应用程序的开源软件框架,能在大型集群上运行应用程序。Hadoop 框架实现了 MapReduce 编程范式,把应用程序分成许多小部分,每个部分能在任意节点上运行。并且 Hadoop 提供了分布式文件系统存储...
 [Hadoop] Hadoop2.x下安装HBase 日期:2017-02-05 23:39:52 点击:71 好评:0
[Hadoop] Hadoop2.x下安装HBase 日期:2017-02-05 23:39:52 点击:71 好评:0
环境:CentOS6.5 Hadoop2.5.2 HBase1.0.0 1.安装好 hadoop 集群,并启动 [grid@hadoop4 ~]$ sh hadoop-2.5.2/sbin/start-dfs.sh [grid@hadoop4 ~]$ sh hadoop-2.5.2/sbin/start-yarn.sh 查看 hadoop 版本: [grid@hadoop4 ~]$ hadoop-2.5.2/bin/hadoop versi...
 [Hadoop] Hadoop 2.0集群配置详细教程 日期:2017-02-05 23:37:18 点击:82 好评:0
[Hadoop] Hadoop 2.0集群配置详细教程 日期:2017-02-05 23:37:18 点击:82 好评:0
前言 Hadoop2.0介绍 Hadoop是 apache 的开源 项目,开发的主要目的是为了构建可靠,可拓展 scalable ,分布式的系 统, hadoop 是一系列的子工程的 总和,其中包含 1. hadoop common : 为其他项目提供基础设施 2. HDFS :分布式的文件系 统 3. MapReduce :...
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个...