|
然后把要测试的输入文件放在文件系统中:
-
$ hdfs dfs -put /usr/mywind/psa input
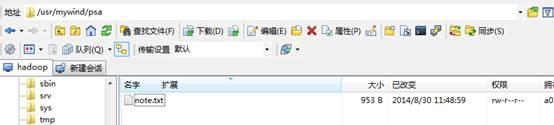
文件内容是Hadoop经典的天气例子的数据:
-
12345679867623119010123456798676231190101234567986762311901012345679867623119010123456+001212345678903456
-
12345679867623119010123456798676231190101234567986762311901012345679867623119010123456+011212345678903456
-
12345679867623119010123456798676231190101234567986762311901012345679867623119010123456+021212345678903456
-
12345679867623119010123456798676231190101234567986762311901012345679867623119010123456+003212345678903456
-
12345679867623119010123456798676231190201234567986762311901012345679867623119010123456+004212345678903456
-
12345679867623119010123456798676231190201234567986762311901012345679867623119010123456+010212345678903456
-
12345679867623119010123456798676231190201234567986762311901012345679867623119010123456+011212345678903456
-
12345679867623119010123456798676231190501234567986762311901012345679867623119010123456+041212345678903456
-
12345679867623119010123456798676231190501234567986762311901012345679867623119010123456+008212345678903456
把文件拷贝到HDFS目录之后,我们可以通过浏览器查看相关的文件及一些状态:
http://192.168.8.184:50070/
这里的IP地址根据你实际的Hadoop服务器地址啦。
好吧,我们所有的Hadoop后台服务搭建跟数据准备都已经完成了,那么我们的M/R程序也要开始动手写了,不过在写当然先配置开发环境了。
3、基于Eclipse的Hadoop2.x开发环境配置
关于JDK及ECLIPSE的安装我就不再介绍了,相信能玩Hadoop的人对这种配置都已经再熟悉不过了,如果实在不懂建议到谷歌百度去搜索一下教程。假设你已经把Hadoop的Eclipse插件下载下来了,然后解压把jar文件放到Eclipse的plugins文件夹里面:

重启Eclipse即可。
然后我们再安装Hadoop到Win7下,在这不再详细说明,跟安装JDK大同小异,在这个例子中我安装到了E:\hadoop。
启动Eclipse,点击菜单栏的【Windows/窗口】→【Preferences/首选项】→【Hadoop Map/Reduce】,把Hadoop Installation Directory设置成开发机上的Hadoop主目录:

点击OK。
开发环境配置完成,下面我们可以新建一个测试Hadoop项目,右键【NEW/新建】→【Others、其他】,选择Map/Reduce Project
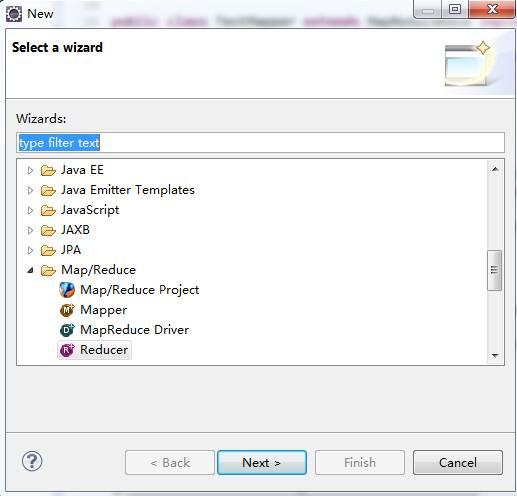
输入项目名称点击【Finish/完成】:
创建完成后可以看到如下目录:
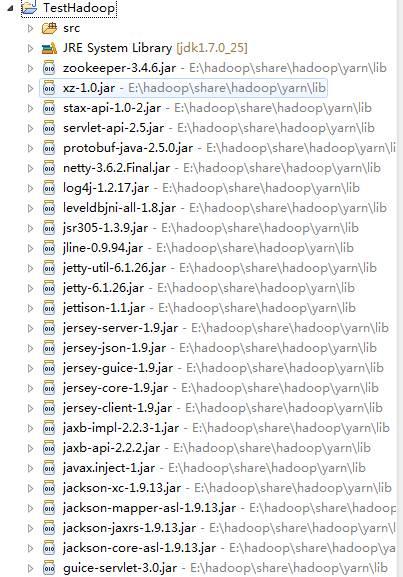
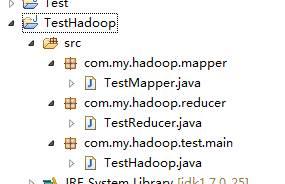
然后在SRC下建立下面包及类:
以下是代码内容:
TestMapper.java
-
package com.my.hadoop.mapper;
-
-
import java.io.IOException;
-
-
import org.apache.commons.logging.Log;
-
import org.apache.commons.logging.LogFactory;
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.LongWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapred.MapReduceBase;
-
import org.apache.hadoop.mapred.Mapper;
-
import org.apache.hadoop.mapred.OutputCollector;
-
import org.apache.hadoop.mapred.Reporter;
-
-
public class TestMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
-
private static final int MISSING = 9999;
-
private static final Log LOG = LogFactory.getLog(TestMapper.class);
-
-
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output,Reporter reporter)
-
throws IOException {
-
String line = value.toString();
-
String year = line.substring(15, 19);
-
int airTemperature;
-
if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs
-
airTemperature = Integer.parseInt(line.substring(88, 92));
-
} else {
-
airTemperature = Integer.parseInt(line.substring(87, 92));
-
}
-
LOG.info("loki:"+airTemperature);
-
String quality = line.substring(92, 93);
-
LOG.info("loki2:"+quality);
-
if (airTemperature != MISSING && quality.matches("[012459]")) {
-
LOG.info("loki3:"+quality);
-
output.collect(new Text(year), new IntWritable(airTemperature));
-
}
-
}
-
-
}
TestReducer.java
-
package com.my.hadoop.reducer;
-
-
import java.io.IOException;
-
import java.util.Iterator;
-
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapred.MapReduceBase;
-
import org.apache.hadoop.mapred.OutputCollector;
-
import org.apache.hadoop.mapred.Reporter;
-
import org.apache.hadoop.mapred.Reducer;
-
-
public class TestReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
(责任编辑:IT)
|