|
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output,Reporter reporter)
throws IOException{
int maxValue = Integer.MIN_VALUE;
while (values.hasNext()) {
maxValue = Math.max(maxValue, values.next().get());
}
output.collect(key, new IntWritable(maxValue));
}
}
TestHadoop.java
-
package com.my.hadoop.test.main;
-
-
import org.apache.hadoop.fs.Path;
-
import org.apache.hadoop.io.IntWritable;
-
import org.apache.hadoop.io.Text;
-
import org.apache.hadoop.mapred.FileInputFormat;
-
import org.apache.hadoop.mapred.FileOutputFormat;
-
import org.apache.hadoop.mapred.JobClient;
-
import org.apache.hadoop.mapred.JobConf;
-
-
import com.my.hadoop.mapper.TestMapper;
-
import com.my.hadoop.reducer.TestReducer;
-
-
public class TestHadoop {
-
-
public static void main(String[] args) throws Exception{
-
-
if (args.length != 2) {
-
System.err
-
.println("Usage: MaxTemperature <input path> <output path>");
-
System.exit(-1);
-
}
-
JobConf job = new JobConf(TestHadoop.class);
-
job.setJobName("Max temperature");
-
FileInputFormat.addInputPath(job, new Path(args[0]));
-
FileOutputFormat.setOutputPath(job, new Path(args[1]));
-
job.setMapperClass(TestMapper.class);
-
job.setReducerClass(TestReducer.class);
-
job.setOutputKeyClass(Text.class);
-
job.setOutputValueClass(IntWritable.class);
-
JobClient.runJob(job);
-
}
-
-
}
为了方便对于Hadoop的HDFS文件系统操作,我们可以在Eclipse下面的Map/Reduce Locations窗口与Hadoop建立连接,直接右键新建Hadoop连接即可:
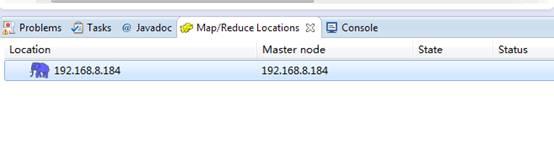
连接配置如下:

然后点击完成即可,新建完成后,我们可以在左侧目录中看到HDFS的文件系统目录:
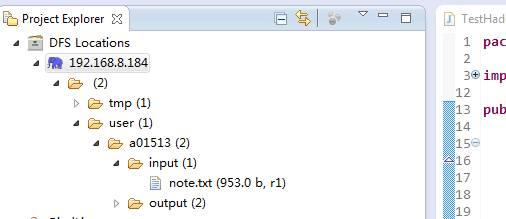
这里不仅可以显示目录结构,还可以对文件及目录进行删除、新增等操作,非常方便。
当上面的工作都做好之后,就可以把这个项目导出来了(导成jar文件放到Hadoop服务器上运行):
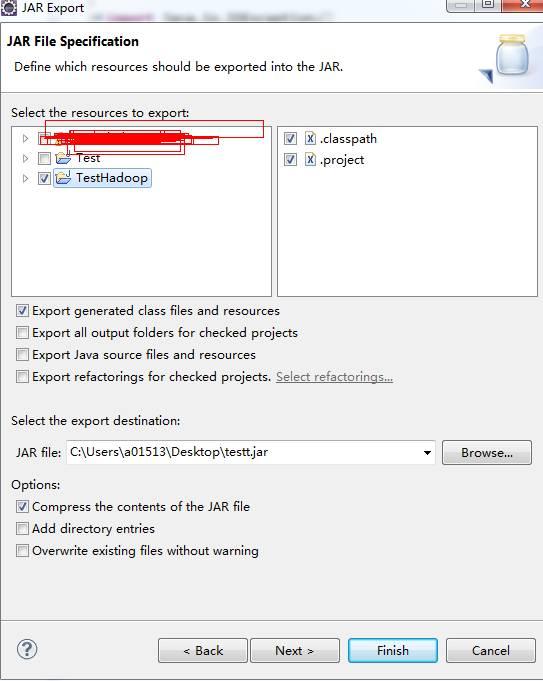
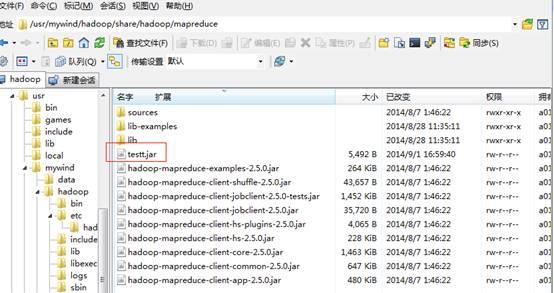
点击完成,然后把这个testt.jar文件上传到Hadoop服务器(192.168.8.184)上,目录(其实可以放到其他目录,你自己喜欢)是:
-
/usr/mywind/hadoop/share/hadoop/mapreduce
如下图:
4、运行Hadoop程序及查看运行日志
当上面的工作准备好了之后,我们运行自己写的Hadoop程序很简单:
-
$ hadoop jar /usr/mywind/hadoop/share/hadoop/mapreduce/testt.jar com.my.hadoop.test.main.TestHadoop input output
注意这是output文件夹名称不能重复哦,假如你执行了一次,在HDFS文件系统下面会自动生成一个output文件夹,第二次运行时,要么把output文件夹先删除($ hdfs dfs -rmr /user/a01513/output),要么把命令中的output改成其他名称如output1、output2等等。
如果看到以下输出结果,证明你的运行成功了:
-
a01513@hadoop :~$ hadoop jar /usr/mywind/hadoop/share/hadoop/mapreduce/testt.jar com.my.hadoop.test.main.TestHadoop input output
-
14/09/02 11:14:03 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0 :8032
(责任编辑:IT)
|