Hadoop伪分布配置与基于Eclipse开发环境搭建(5)
时间:2014-09-04 22:29来源:linux.it.net.cn 作者:it
|
Total vcore-seconds taken by all reduce tasks=4500
Total megabyte-seconds taken by all map tasks=15172608
Total megabyte-seconds taken by all reduce tasks=4608000
Map-Reduce Framework
Map input records=9
Map output records=9
Map output bytes=81
Map output materialized bytes=111
Input split bytes=208
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=111
Reduce input records=9
Reduce output records=1
Spilled Records=18
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=115
CPU time spent (ms)=1990
Physical memory (bytes) snapshot=655314944
Virtual memory (bytes) snapshot=2480295936
Total committed heap usage (bytes)=466616320
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1430
File Output Format Counters
Bytes Written=10
a01513@hadoop :~$
我们可以到Eclipse查看输出的结果:
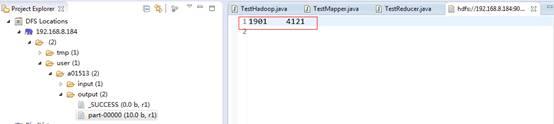
或者用命令行查看:
-
$ hdfs dfs -cat output/part-00000

假如你们发现运行后结果是为空的,可能到日志目录查找相应的log.info输出信息,log目录在:/usr/mywind/hadoop/logs/userlogs 下面。
好了,不太喜欢打字,以上就是整个过程了,欢迎大家来学习指正。
原文链接:http://my.oschina.net/lanzp/blog/309078
(责任编辑:IT) |
------分隔线----------------------------