 [Hadoop] Hadoop2分布式及NN和RM实现HA的实验 日期:2016-06-10 01:10:21 点击:171 好评:0
[Hadoop] Hadoop2分布式及NN和RM实现HA的实验 日期:2016-06-10 01:10:21 点击:171 好评:0
目录结构 引言 实验环境 实验过程 演示demo [一]、 引言 在Hadoop2.x初期的时候写过一篇hadoop 2.2.0 集群模式安装配置和测试,记录了分布式搭建的最基本的搭建步骤和运行演示,那篇文章中没有对HA的配置做实验,本文会详细介绍 Hadoop2的分布式、NameNode配...
[Hadoop] hadoop管理 日期:2016-06-10 00:01:27 点击:194 好评:0
1. hdfs基本统计情况 fs是个比较抽象的层面,在分布式环境中,fs就是dfs,但在本地环境中,fs是local file system,这个时候dfs就不能用。 hadoop dfsadmin -report 2. hadoop安全模式 NameNode在启动时会自动进入安全模式。安全模式是NameNode的一种状态,在...
[Hadoop] Hadoop三种安装模式 日期:2016-06-09 23:56:05 点击:93 好评:0
Hadoop三种安装模式:单机模式,伪分布式,真正分布式 一 单机模式standalone 单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Had...
[Hadoop] 伪分布模式下执行wordcount实例时报错解决办法 日期:2016-06-09 23:55:18 点击:117 好评:0
问题1、不能分配内存,错误提示如下: FAILED java.lang.RuntimeException: Error while running command to get file permissions : java.io.IOException: Cannot run program /bin/ls: java.io.IOException: error=12, Cannot allocate memory at java.lang...
[Hadoop] 安装hadoop2.4.0遇到的问题 日期:2016-06-09 23:53:57 点击:101 好评:0
一、执行start-dfs.sh后,datenode没有启动 查看日志如下: 2014-06-18 20:34:59,622 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for block pool Block pool registering (Datanode Uuid unassigned) service to localh...
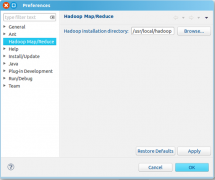 [Hadoop] Eclipse下搭建Hadoop2.4.0开发环境 日期:2016-06-09 23:53:51 点击:200 好评:0
[Hadoop] Eclipse下搭建Hadoop2.4.0开发环境 日期:2016-06-09 23:53:51 点击:200 好评:0
一、安装Eclipse 下载Eclipse,解压安装,例如安装到/usr/local,即/usr/local/eclipse 4.3.1版本下载地址:http://pan.baidu.com/s/1eQkpRgu 二、在eclipse上安装hadoop插件 1、下载hadoop插件 下载地址:http://pan.baidu.com/s/1mgiHFok 此zip文件包含了...
 [Hadoop] 一、Ubuntu14.04下安装Hadoop2.4.0 (单机模式) 日期:2016-06-09 23:52:02 点击:89 好评:0
[Hadoop] 一、Ubuntu14.04下安装Hadoop2.4.0 (单机模式) 日期:2016-06-09 23:52:02 点击:89 好评:0
一、在Ubuntu下创建hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop操作时,我们使用该用户。 1、创建hadoop用户组 2、创建hadoop用户 sudo adduser -ingroup hadoop hadoop 回车后会提示输入新的UNIX密码,这是新...
 [Hadoop] 二、Ubuntu14.04下安装Hadoop2.4.0 (伪分布模式) 日期:2016-06-09 23:50:13 点击:173 好评:0
[Hadoop] 二、Ubuntu14.04下安装Hadoop2.4.0 (伪分布模式) 日期:2016-06-09 23:50:13 点击:173 好评:0
在Ubuntu14.04下安装Hadoop2.4.0(单机模式)基础上配置 一、配置core-site.xml /usr/local/hadoop/etc/hadoop/core-site.xml 包含了hadoop启动时的配置信息。 编辑器中打开此文件 sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml 在该文件的configu...
[Hadoop] ubuntu + hadoop2.5.2分布式环境配置 日期:2016-06-09 23:46:37 点击:62 好评:0
我之前有详细写过hadoop-0.20.203.0rc1版本的环境搭建 hadoop学习笔记环境搭建 http://www.cnblogs.com/huligong1234/p/3533382.html 本篇部分细节就不多说。 一、基础环境准备 系统:(VirtualBox) ubuntu-12.04.2-desktop-i386.iso hadoop版本:hadoop-2.5....
 [负载均衡SLB] LVS+Keepalived实现高可用负载均衡分发 日期:2016-06-09 23:31:56 点击:157 好评:0
[负载均衡SLB] LVS+Keepalived实现高可用负载均衡分发 日期:2016-06-09 23:31:56 点击:157 好评:0
一、概念理解 负载均衡 集群即将相同服务部署在多台服务器上构成一个集群整体对外提供服务。在应用中,内容服务器之前总会有一台负载均衡服务器,负载均衡器的任务就是作为web服务器的流量入口,将客户端的请求分发到后端集群真实服务器,实现客户端到服务端...
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个...
一、 Apache、Tomcat集群和负载均衡所需资源软件(附下载地址): a) apache_2.0.55-win...
不对的地方,欢迎大家拍砖。 现在有如下三台服务器: 10.57.22.201(做负载均衡配制)(...
一、试验拓扑 二、环境描述 负载均衡器: eth0 192.168.152.139 VIP : 192.168.152.2...